Gerenciando Itens¶
O Datapool nos permite gerenciar de forma eficiente o processamento de itens em lote.
Nas seções a seguir, você encontrará mais detalhes sobre o funcionamento dos Datapools e como utilizar esses recursos em conjunto com seus processos de automação.
Adicionando novos itens ao Datapool¶
Podemos adicionar novos itens ao Datapool de algumas maneiras diferentes.
Adicionando cada item manualmente¶
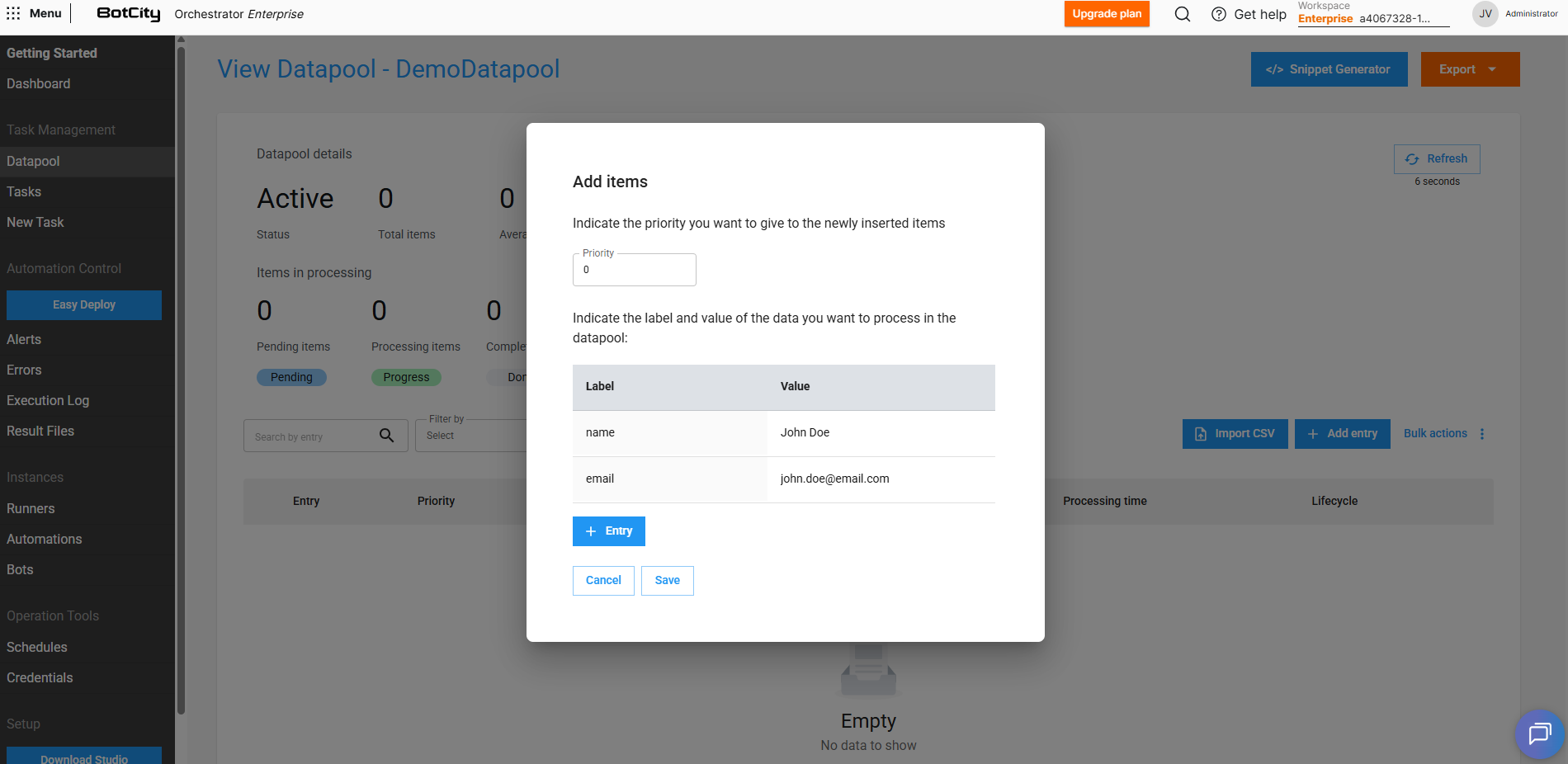
Clicando em + Adicionar entrada vamos poder adicionar um novo item ao Datapool.
Podemos preencher qual será a prioridade desse item em específico e também os valores que esse item recebe. Itens com prioridades mais altas serão processados primeiro.
Informação
Além de preencher os valores que foram definidos na criação do Schema, também podemos adicionar campos extras para um item através do botão + Entrada.
Adicionando itens através de um arquivo CSV¶
Além de adicionar itens manualmente, também podemos incluir vários itens de uma só vez através de um arquivo .csv.
Ao selecionar a opção Importar CSV, podemos baixar um arquivo de exemplo e preencher com as informações dos itens que serão adicionados ao Datapool.
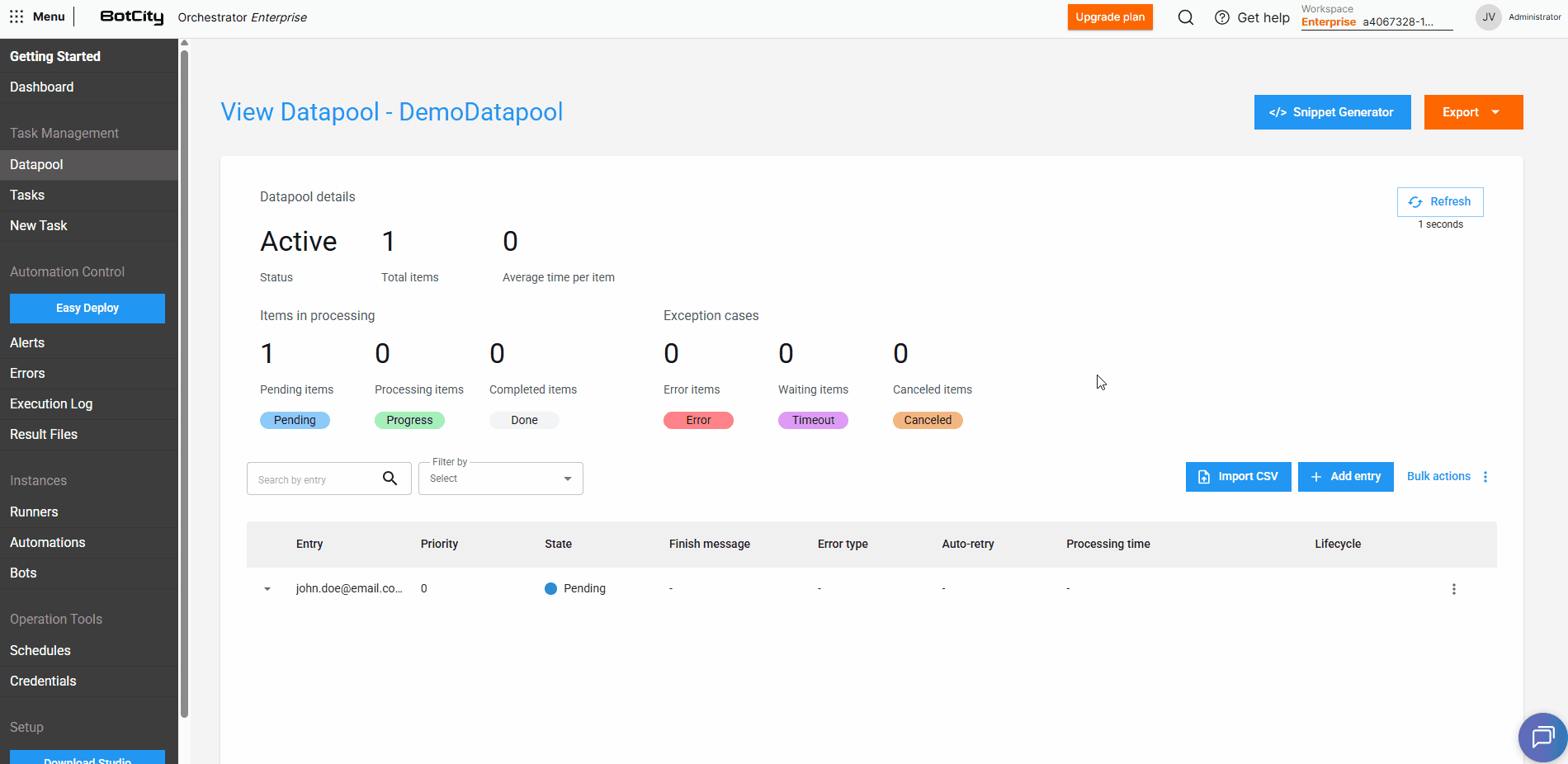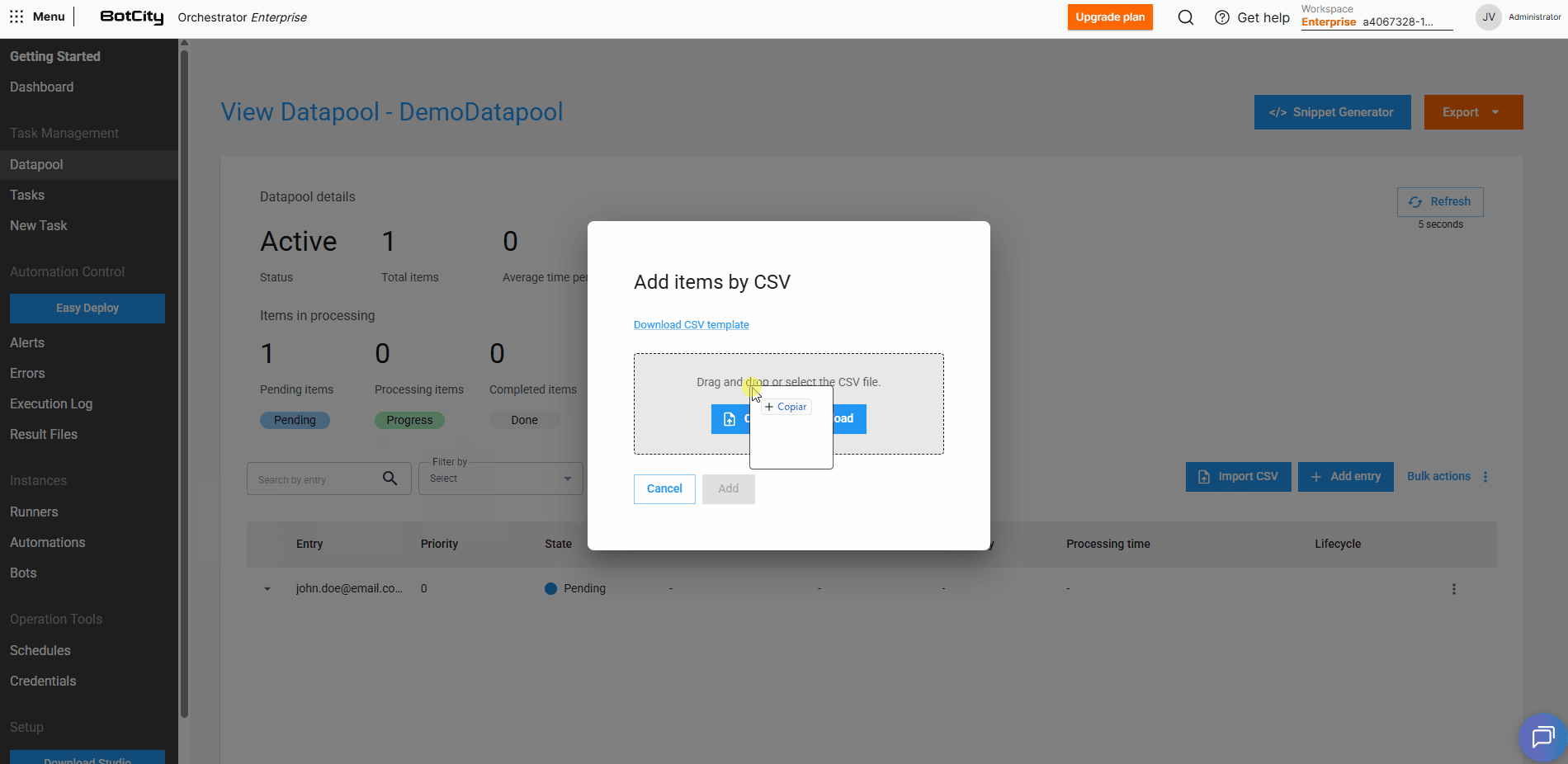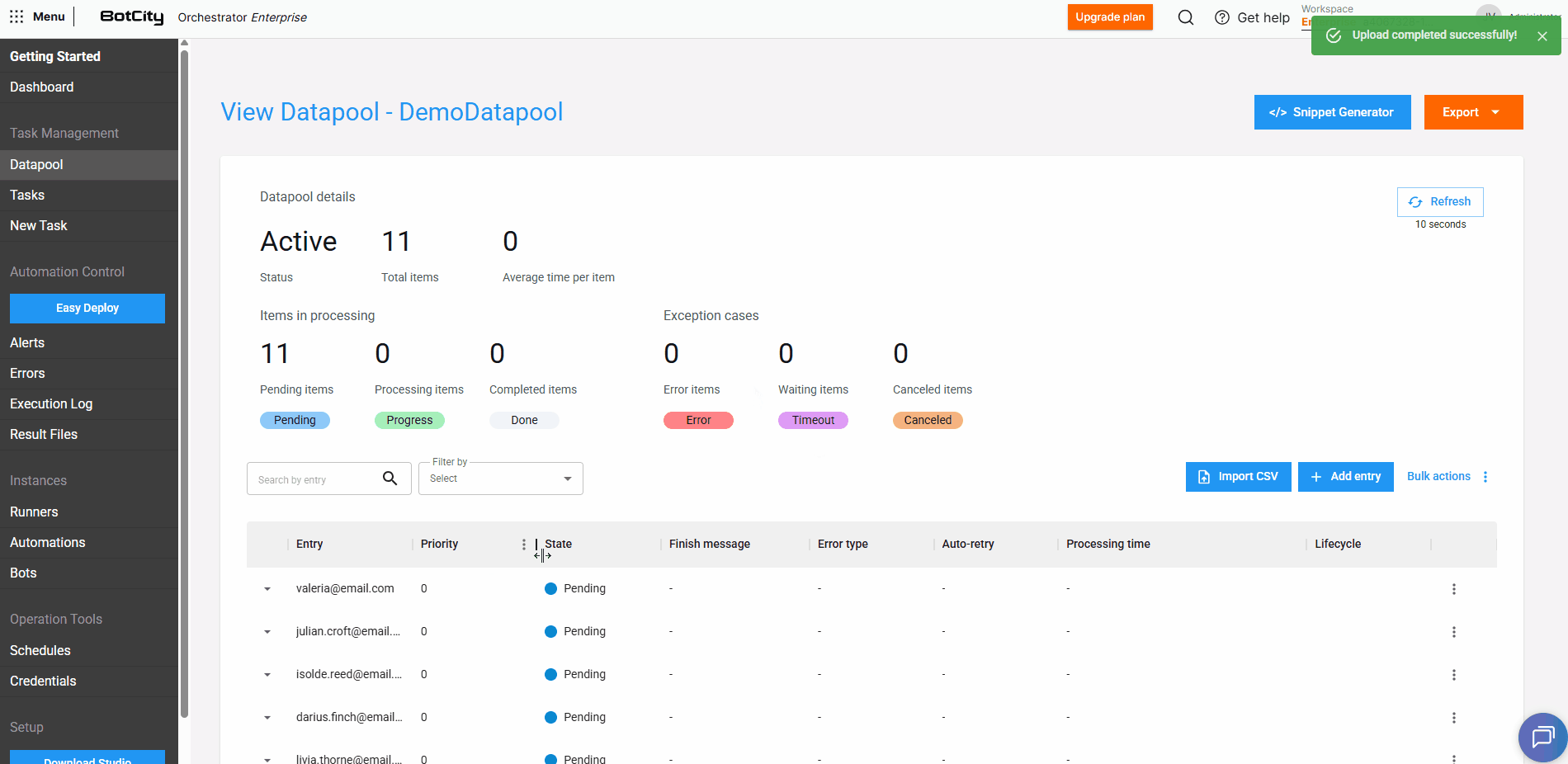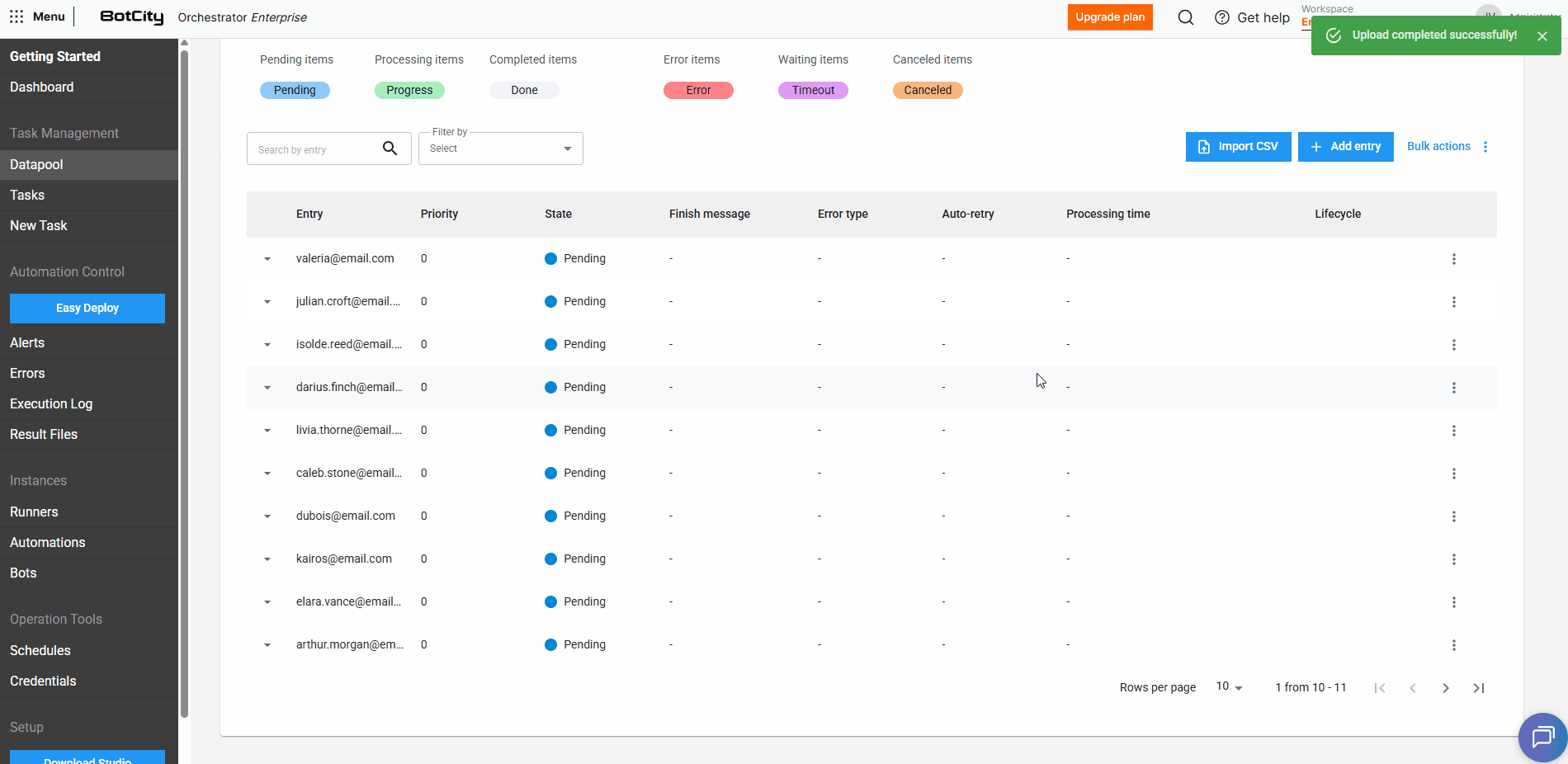
Feito isso, basta subir o arquivo e clicar em Adicionar para que os itens sejam carregados automaticamente.
Dica
Você também pode adicionar novos itens ao Datapool via código, através do BotCity Maestro SDK ou utilizando a BotCity Orquestrador API.
Manipulando os itens do Datapool¶
Uma vez que os itens foram adicionados ao Datapool, é possível realizarmos diversas operações.
O funcionamento básico consiste em consumir os itens da fila, realizar o processamento via código e reportar o estado final.
Dica
Explore o  para obter exemplos de código que facilitam as manipulações do Datapool.
para obter exemplos de código que facilitam as manipulações do Datapool.
Acesse e aprenda como adicionar, consumir e manipular itens do Datapool via código.
Consumindo os itens da fila¶
Após adicionar os itens no Datapool, eles ficarão pendentes na fila aguardando o processamento.
Consumindo os itens da fila no código da automação
Importante
O consumo dos itens pendentes será feito utilizando o BotCity Maestro SDK, através do código da sua automação.
Veja mais detalhes sobre como consumir os itens do Datapool na seção Integrações com o SDK.
# Consumindo o próximo item disponível e reportando o estado de finalização ao final
datapool = maestro.get_datapool(label="Items-To-Process")
while datapool.has_next():
# Busca o próximo item do Datapool
item = datapool.next(task_id=execution.task_id)
if item is None:
# O item poderia ser 'None', caso outro processo o consumisse antes
break
try:
# Processando o item...
# Exemplo de como obter o valor de um campo específico
value1 = item["<LABEL_CAMPO_1>"]
value2 = item["<LABEL_CAMPO_2>"]
# Finalizando como 'CONCLUÍDO' após o processamento
item.report_done(finish_message="Processado com sucesso!")
except Exception:
# Finalizando o processamento do item como 'ERRO'
item.report_error(error_type=ErrorType.SYSTEM, finish_message="Falha no processamento.")
// Consumindo o próximo item disponível e reportando o estado de finalização ao final
Datapool datapool = await maestro.GetDatapoolAsync("Items-To-Process");
while (await dataPool.HasNextAsync()) {
// Busca o próximo item do Datapool
DatapoolEntry item = await datapool.NextAsync(execution.TaskId);
if (item == null) {
// O item poderia ser 'null', caso outro processo o consumisse antes
break;
}
try {
// Processando o item...
// Exemplo de como obter o valor de um campo específico
string value1 = await item.GetValueAsync("<LABEL_CAMPO_1>");
string value2 = await item.GetValueAsync("<LABEL_CAMPO_2>");
// Finalizando como 'CONCLUÍDO' após o processamento
await item.ReportDoneAsync();
} catch (Exception ex) {
// Finalizando o processamento do item como 'ERRO'
await item.ReportErrorAsync();
}
}
Abaixo você irá ver mais detalhes sobre o gerenciamento dos itens e como funcionam os estados de processamento.
Visualizando as informações¶
Para cada item adicionado no Datapool, podemos visualizar as seguintes informações:
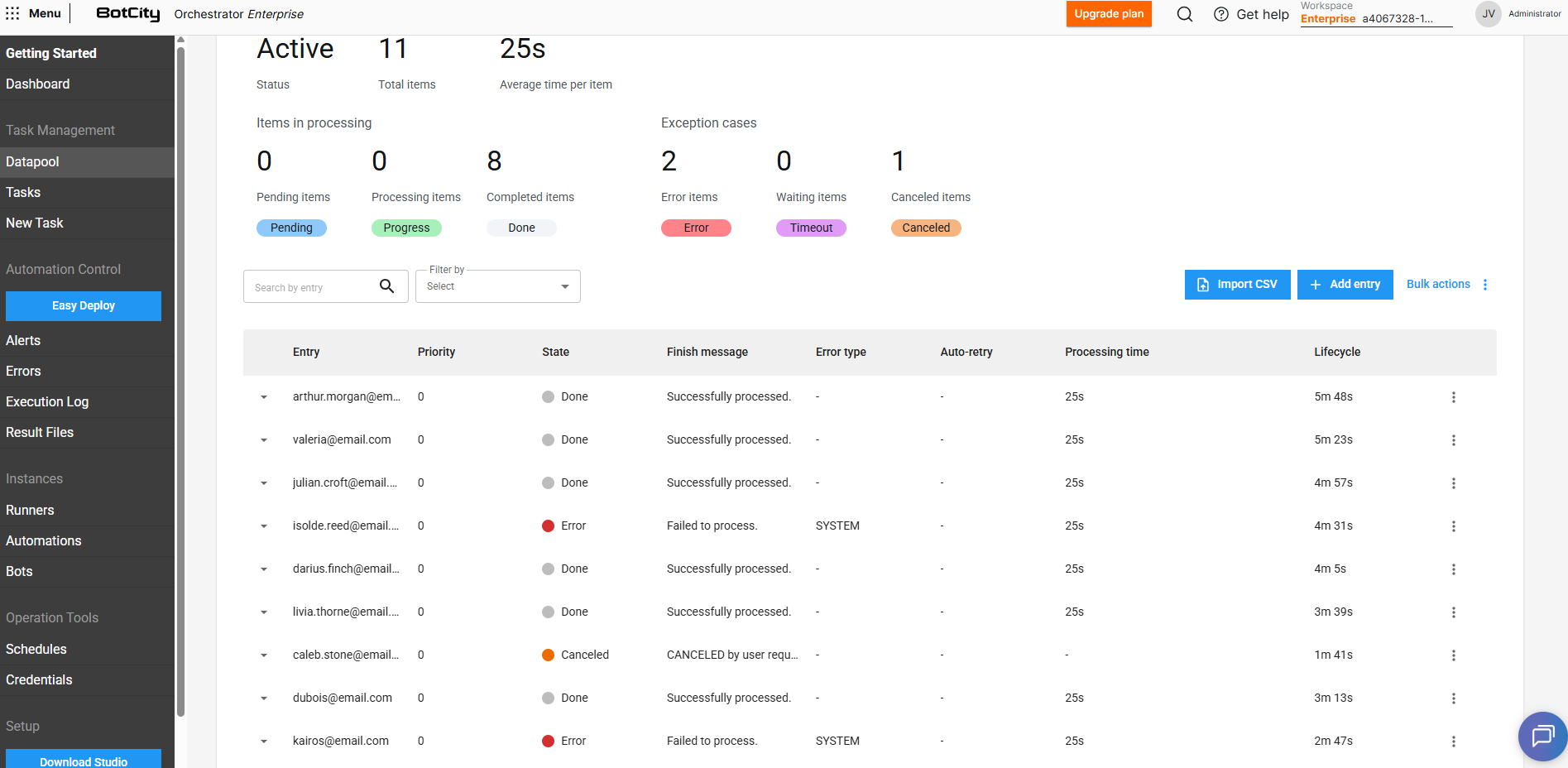
- Entrada: O identificador único do item ou uma combinação dos campos que foram marcados no
Schemapara serem exibidos (veja a seção que explica sobre a criação do Schema). - Prioridade: A prioridade definida para o item, itens com prioridades mais altas serão processados primeiro.
- Estado: O estado atual do item no Datapool.
- Mensagem de finalização: A mensagem de finalização opcional reportada via código ao final do processamento.
- Tipo de erro: O tipo de erro reportado via código ao final do processamento, caso o item tenha sido processado com falha.
- SYSTEM: Sinaliza que o erro no processamento foi causado por um erro de sistema. Esse será o tipo padrão caso não seja especificado no reporte.
- BUSINESS: Sinaliza que o erro no processamento foi causado por uma falha de negócio, ou seja, o item finalizou com erro devido a alguma regra de negócio específica.
- Auto-retry: Representa qual é o índice da tentativa de processamento, em caso de itens que foram reprocessados.
- Tempo de processamento: O tempo gasto no processamento do item.
- Ciclo de vida: O tempo que foi levado desde a criação do item no Datapool até a finalização do processamento.
Ao expandir os detalhes de um item clicando em ▼, podemos visualizar as seguintes informações adicionais:
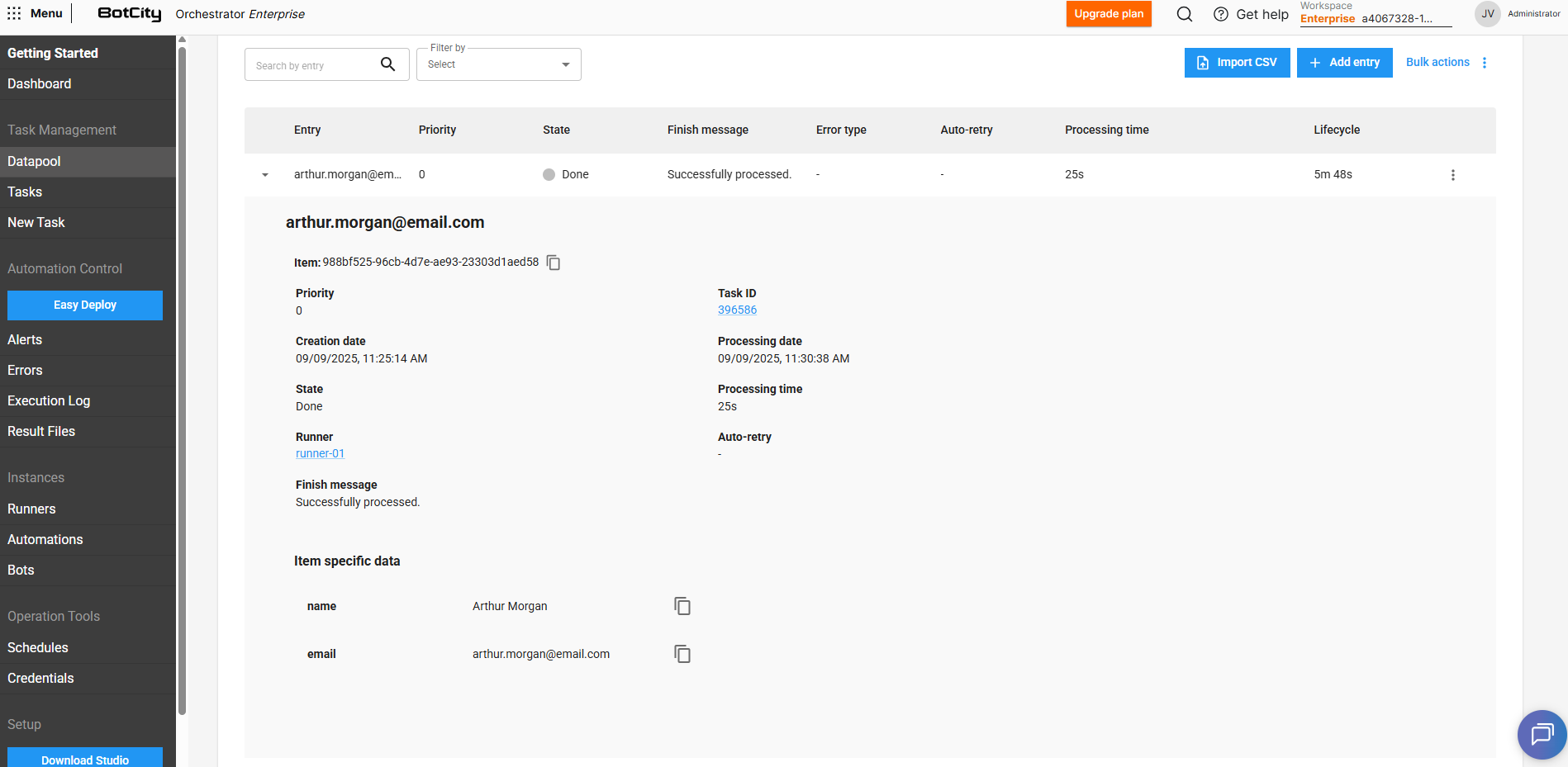
- Item: O identificador único do item.
- Prioridade: A prioridade definida para o item.
- Task Id: O identificador da tarefa responsável por acessar e consumir aquele item do Datapool.
- Data de criação: A data em que o item foi adicionado ao Datapool.
- Data de processamento: A data em que o item foi puxado para ser processado.
- Estado: O estado atual do item no Datapool.
- Tempo de processamento: O tempo gasto no processamento do item.
- Runner: O Runner responsável pela execução da tarefa que consumiu o item.
- Auto-retry: Representa qual é o índice da tentativa de processamento, em caso de itens que foram reprocessados.
- Mensagem de finalização: A mensagem de finalização opcional reportada via código ao final do processamento.
- Dados específicos do item: Os conjuntos de chave/valor que compõem o item do Datapool.
Editando dados de itens pendentes¶
Para itens que estão no estado PENDENTE, podemos editar os valores preenchidos e adicionar novos campos.
Ao expandir os detalhes de um item e clicar em Editar, é possível ajustar os valores definidos previamente.
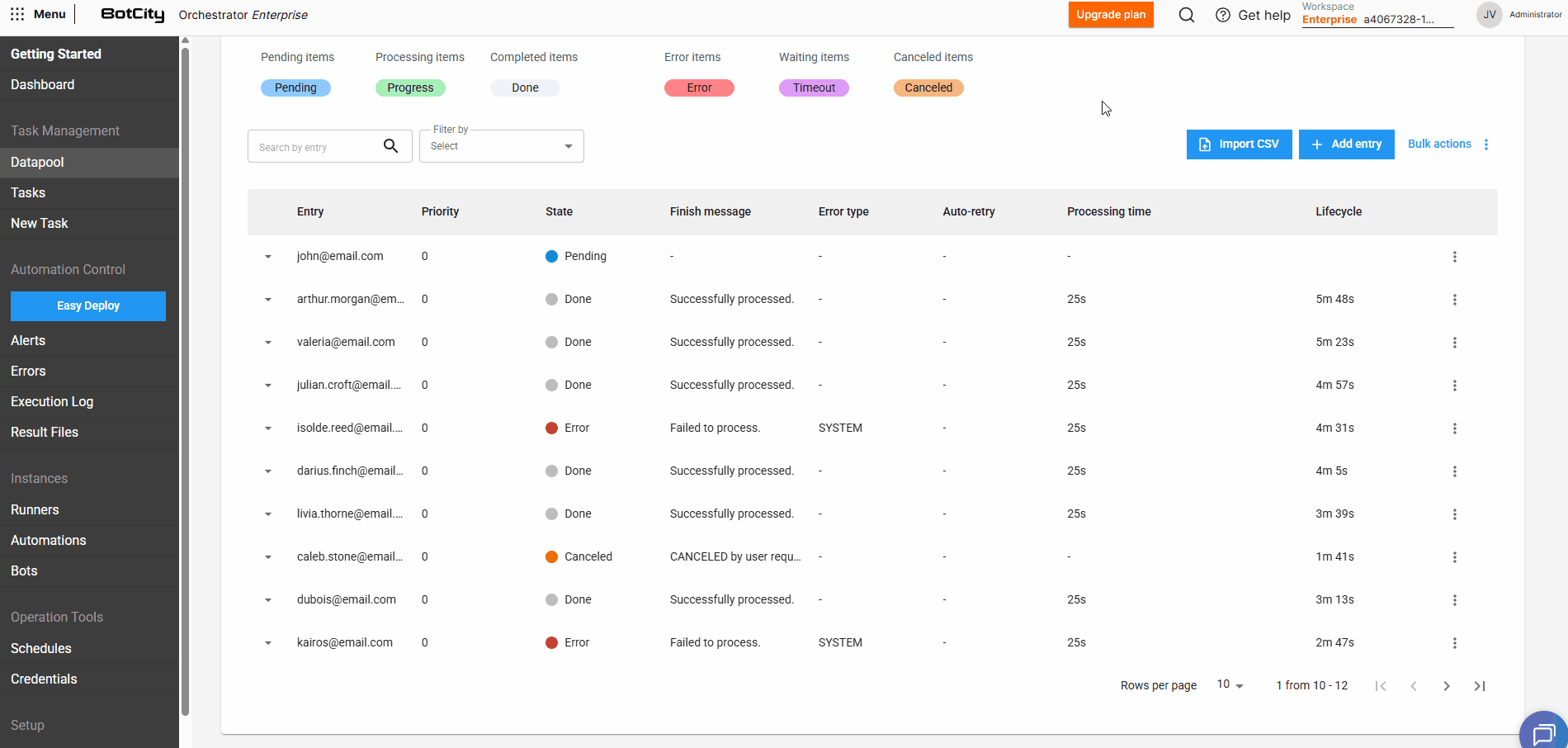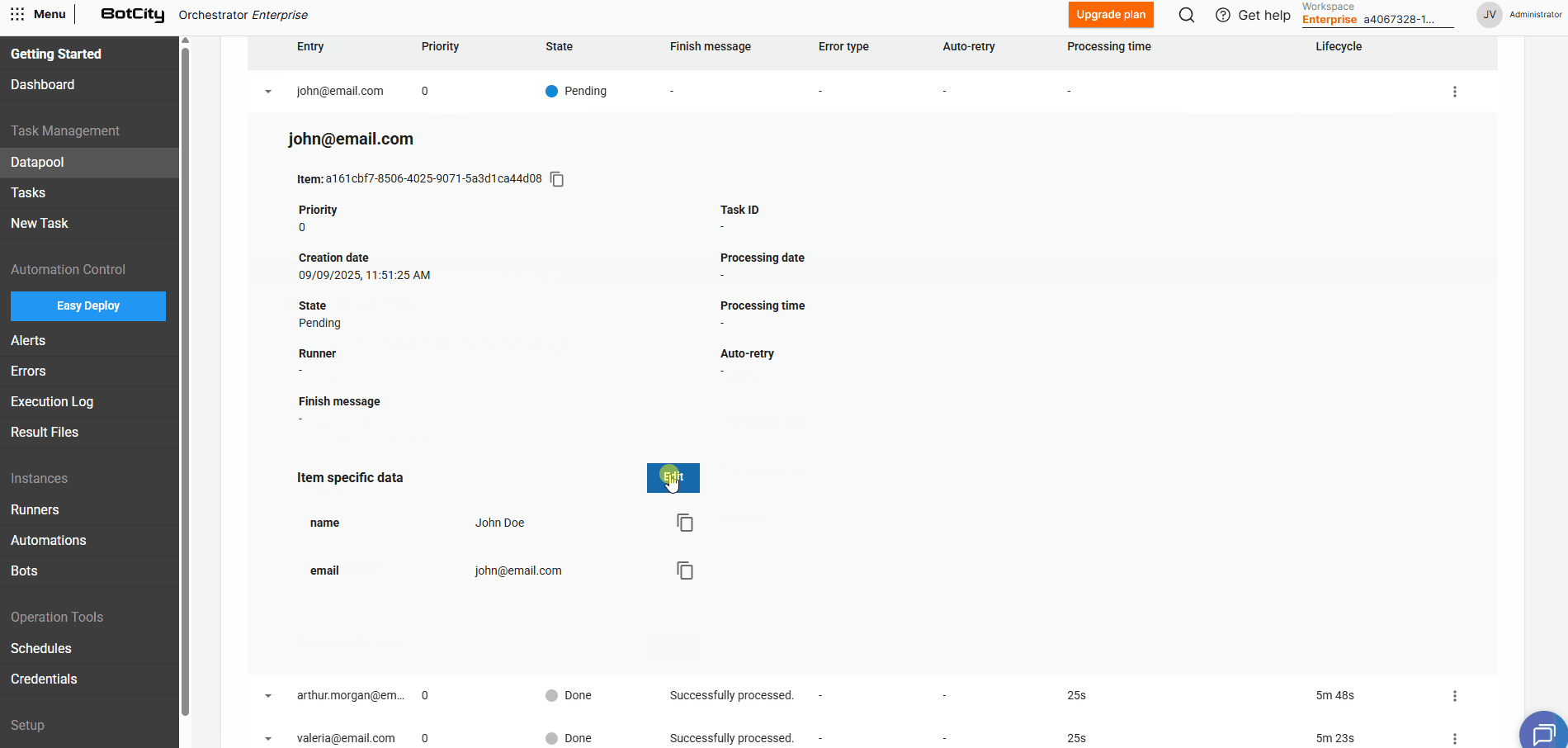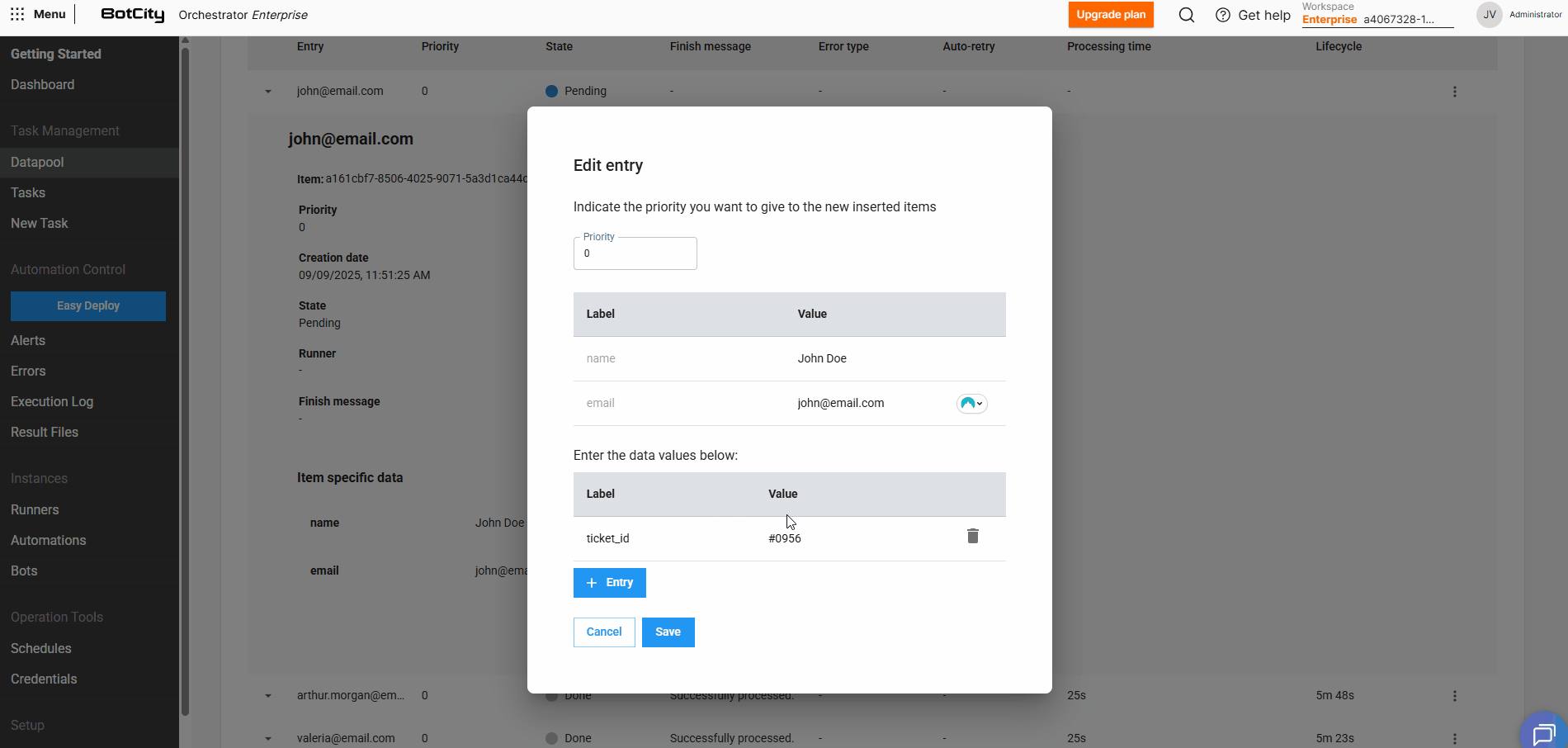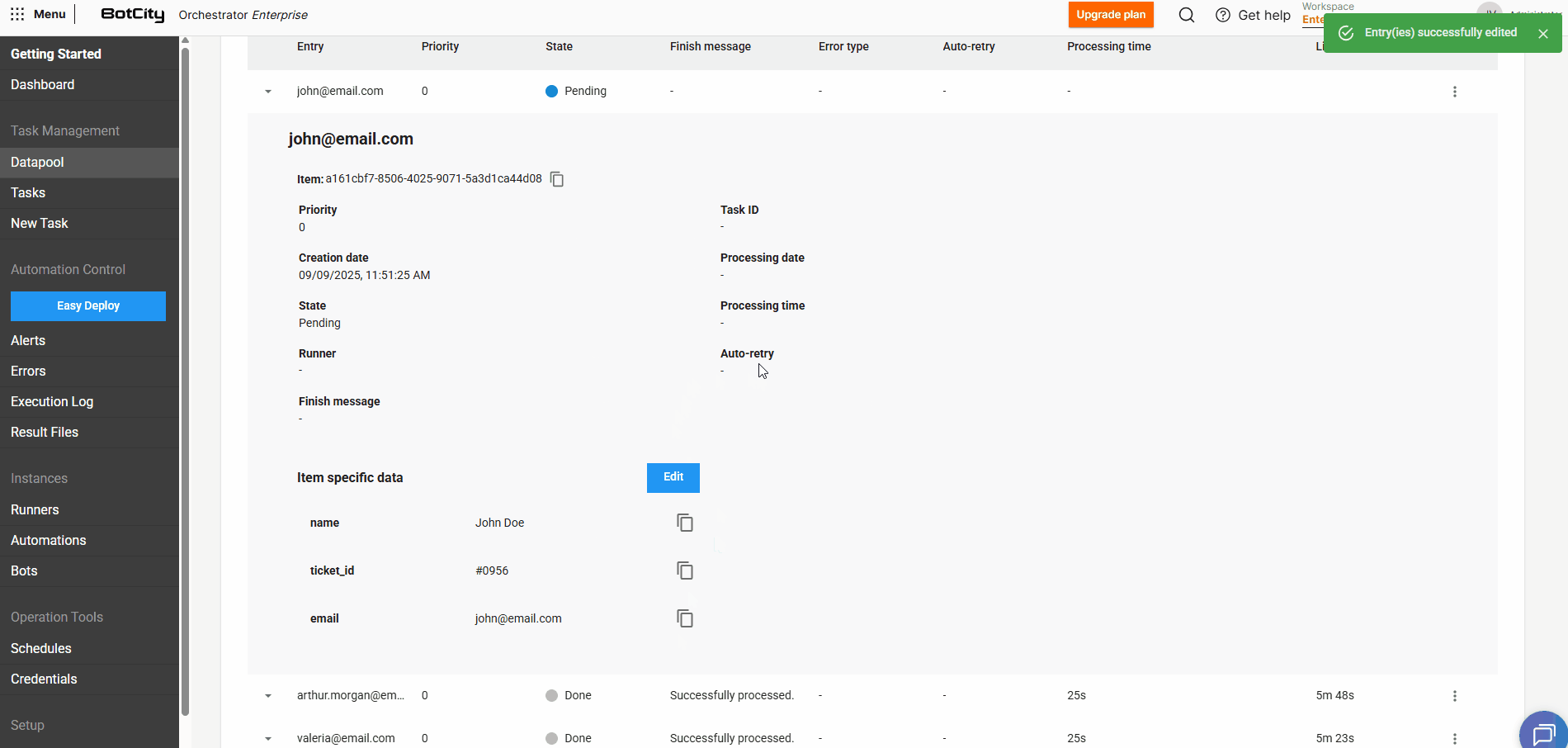
Clicando em + Entrada, você consegue incluir quantos campos adicionais forem necessários para aquele item em específico.
Ciclo de vida e estados de processamento¶
Como vimos anteriormente, ao adicionar um novo item ao Datapool, ele inicialmente ficará com o estado PENDENTE.
Podemos entender os estados que um item pode assumir durante o seu ciclo de vida da seguinte maneira:
PENDENTE: O item está aguardando o processamento, nesse ponto ele estará disponível para ser acessado e consumido.
PROCESSANDO: O item foi puxado para execução e está na fase de processamento.
CONCLUÍDO: O processamento do item foi concluído com sucesso.
ERRO: O processamento do item foi concluído com erro.
SYSTEM: Indica que o erro no processamento foi causado por um erro de sistema.BUSINESS: Indica que o erro no processamento foi causado por uma falha nas regras de negócio. Erros do tipoBUSINESSnão são considerados nos cenários de Auto-retry e Abortar em casos de erro.
CANCELADO: O item foi cancelado e não será puxado para processamento.
TIMEOUT: O processamento do item está em uma fase de timeout (isso pode ocorrer quando o estado de finalização do item não é reportado via código).
Entendendo o estado de TIMEOUT¶
O estado de TIMEOUT é baseado no tempo que foi definido na propriedade Tempo de processamento ao criar o Datapool.
Caso o processamento de um item exceda o tempo máximo definido, seja por falta do reporte indicando o estado do item ou algum travamento na execução do processo que impeça que o reporte seja feito, automaticamente o Datapool irá indicar que aquele item entrou em um estado de TIMEOUT.
Isso não significa necessariamente um erro, pois um item ainda pode sair do estado de TIMEOUT para um estado de CONCLUÍDO ou ERRO.
Porém, caso o processo não se recupere (em caso de eventuais travamentos) e o reporte do estado do item não seja feito, o Datapool automaticamente vai considerar o status daquele item como ERRO após um período de 24 horas.
Reportando o estado de um item¶
A etapa de reportar o estado de finalização de um item é crucial para que os estados e contadores do Datapool sejam atualizados corretamente.
Para isso, é necessário que o estado de processamento de cada item (CONCLUÍDO ou ERRO) seja reportado via código dentro da lógica do processo.
Reportando o estado de um item no código da automação
Importante
Itens reportados com erros do tipo BUSINESS não serão considerados para os cenários de auto-retry e abortar em caso de erros.
Para esses cenários, somente itens com erro do tipo SYSTEM serão considerados.
Veja mais detalhes sobre o reporte de itens na seção Integrações com o SDK.
# Busca o próximo item disponível do Datapool
item = datapool.next(task_id=execution.task_id)
# Finalizando como 'CONCLUÍDO' após o processamento
item.report_done(finish_message="Processado com sucesso!")
# Finalizando o processamento do item indicando um erro de sistema
item.report_error(error_type=ErrorType.SYSTEM, finish_message="Sistema indisponível.")
# Finalizando o processamento do item indicando um erro de negócio
item.report_error(error_type=ErrorType.BUSINESS, finish_message="Dados inválidos.")
Caso o estado de processamento do item não seja reportado por algum motivo, e o tempo de processamento ultrapassar o valor que foi definido na propriedade Tempo de processamento, isso fará com que o Datapool atribua automaticamente um estado de TIMEOUT para aquele item.
Datapool <> BotCity Insights
O reporte de itens no Datapool NÃO possui impacto direto nas métricas calculadas pelo BotCity Insights.
Para ter as métricas atualizadas, é estritamente necessário:
- Garantir que os dados financeiros das automações estejam devidamente configurados na seção Entrada de Dados dentro do Insights.
- Garantir que o reporte dos itens processados esteja sendo feito corretamente na finalização da tarefa, ao final da execução.
Veja mais detalhes na seção BotCity Insights.
Operações com itens do Datapool¶
Além de visualizar as informações, podemos realizar algumas operações ao acessar o menu de ações de cada item:
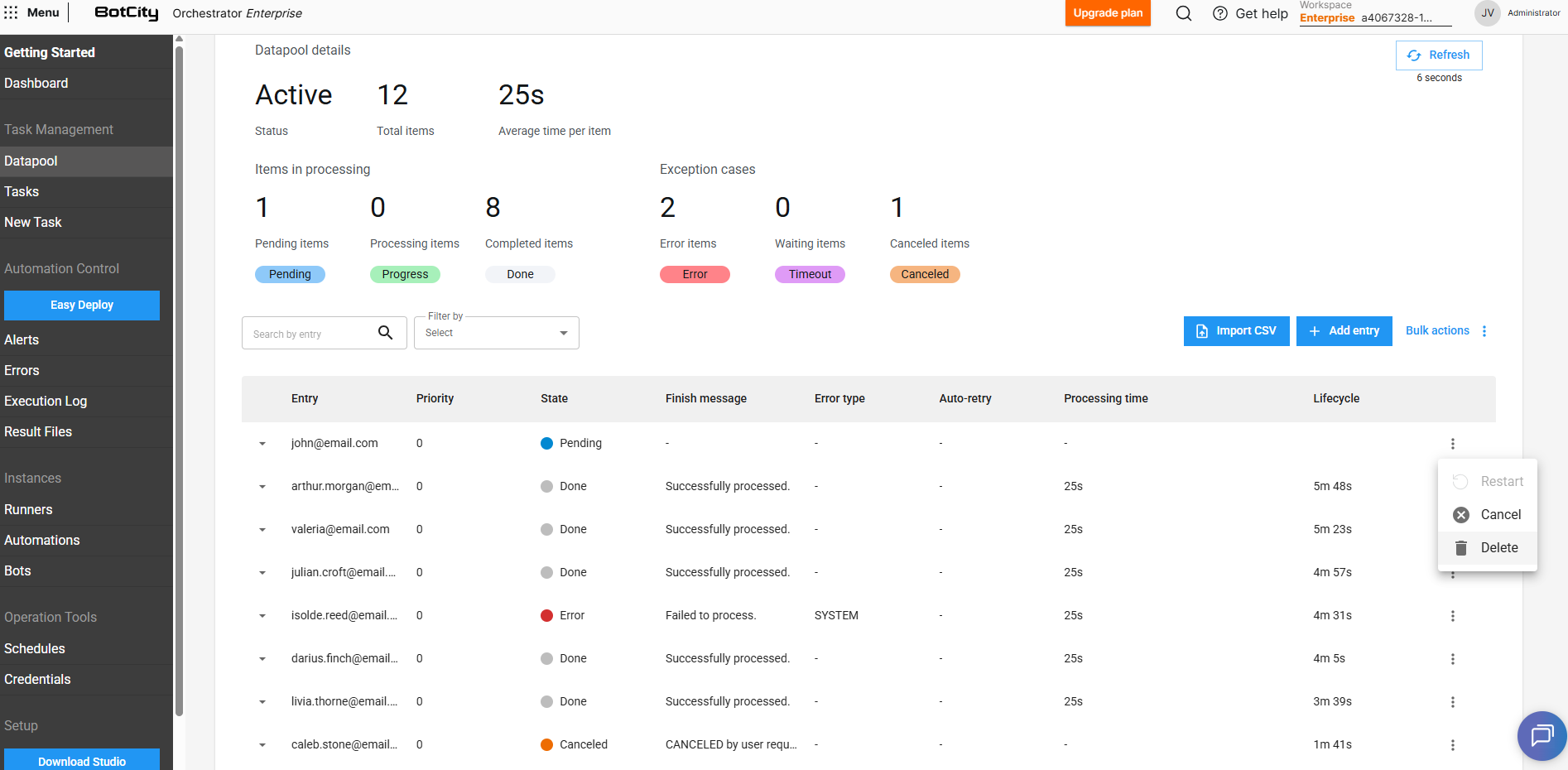
Reiniciar
Insere uma cópia do item atual no Datapool para que ele seja processado novamente.
Reiniciando itens que possuem campos de ID único
Caso você esteja utilizando campos com função de ID único, não será possível reiniciar um item que já tenha sido processado.
Nesse caso, é necessário que o item existente seja excluído para que um novo item que utiliza o mesmo ID único possa ser inserido no Datapool.
Cancelar
Cancela um item que ainda não foi puxado para processamento (PENDENTE). Nesse caso, o item será ignorado durante o consumo da fila.
Deletar
Remove o item da fila e do histórico do Datapool. Não é possível excluir itens que estão no estado de PROCESSANDO ou TIMEOUT.
Dica
Através do recurso Ações em massa também é possível cancelar ou deletar múltiplos itens, caso você precise realizar essas operações para um grande volume de entradas.
Filtrando itens na fila¶
O Datapool possui um recurso de filtro, que permite buscarmos itens da fila filtrando pela data ou estado atual.
Além disso, também é possível buscarmos por um item específico utilizando os valores da entrada como filtros.
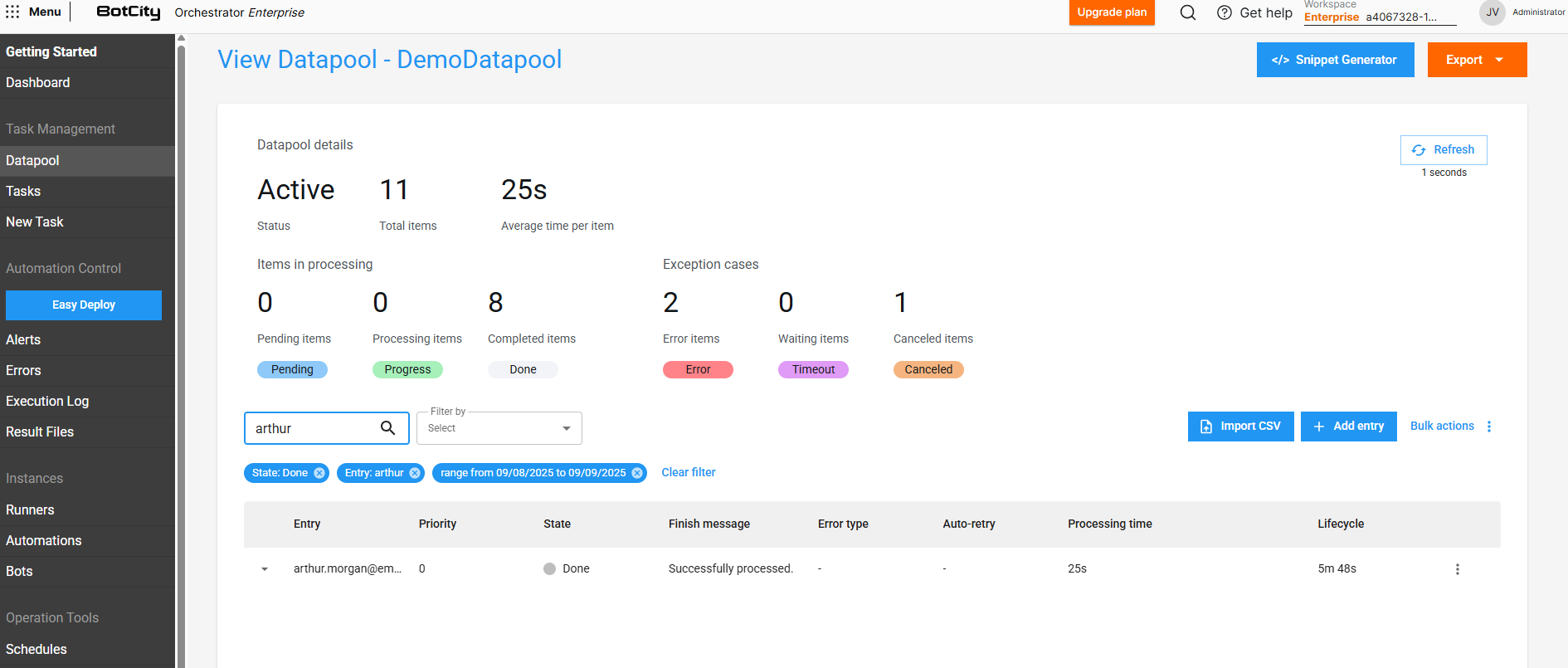
Importante
Para que um campo possa ser usado na busca, é necessário que a opção Exibir valor esteja marcada na configuração do campo dentro do Schema.
Exportando dados dos itens¶
No painel principal do Datapool podemos exportar facilmente os itens da fila.
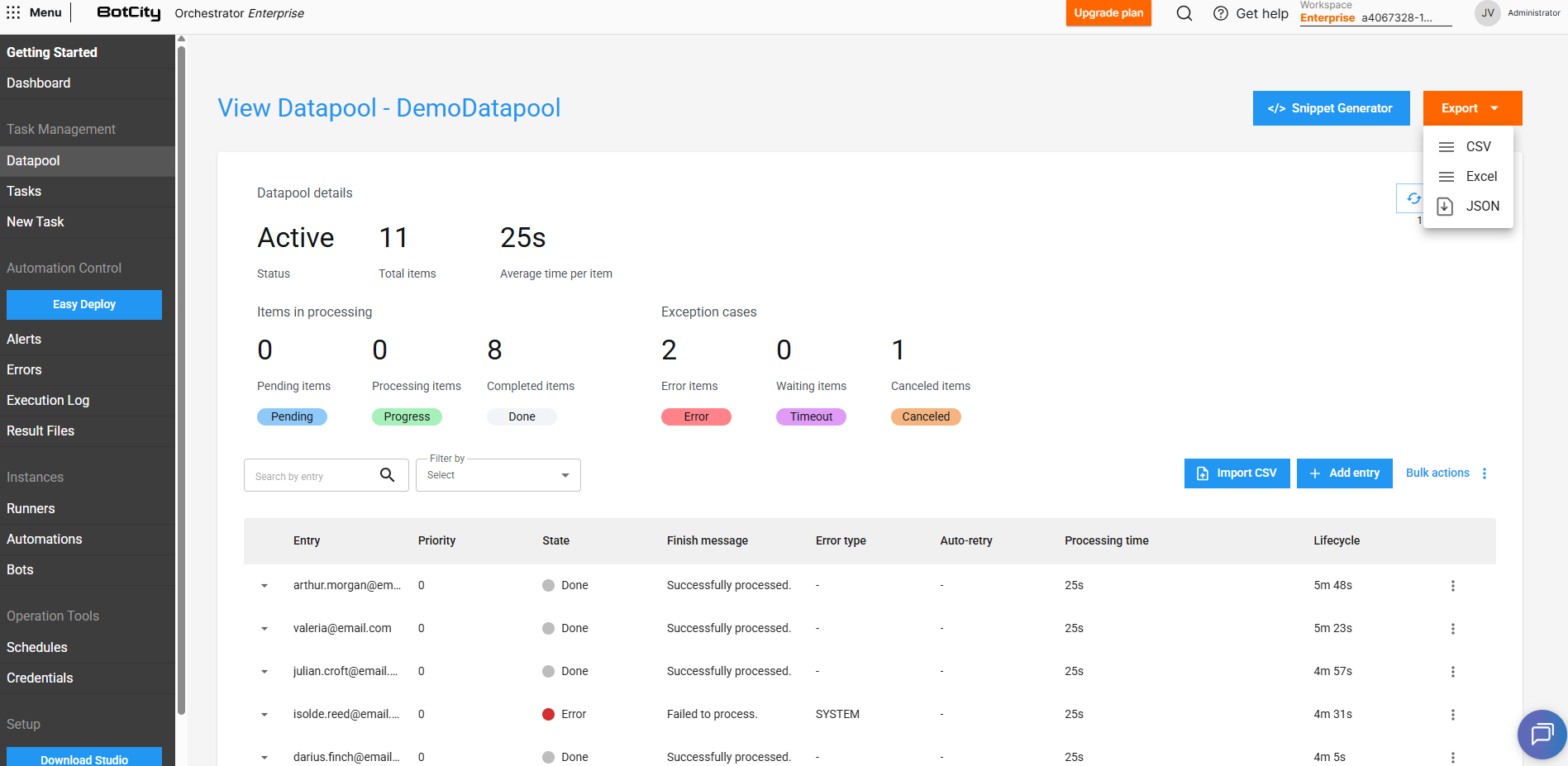
Através do botão Exportar podemos escolher o formato mais adequado e desse modo obter de forma fácil os dados referentes ao histórico de processamento dos itens.