Primeiros Passos¶
Criando um Datapool¶
Para criar um novo Datapool basta clicar em + Novo Datapool e realizar a configuração em 4 etapas simples:
Etapa 1 - Informações Básicas¶
Nessa etapa, você deve fornecer as informações iniciais sobre o Datapool que está sendo criado.
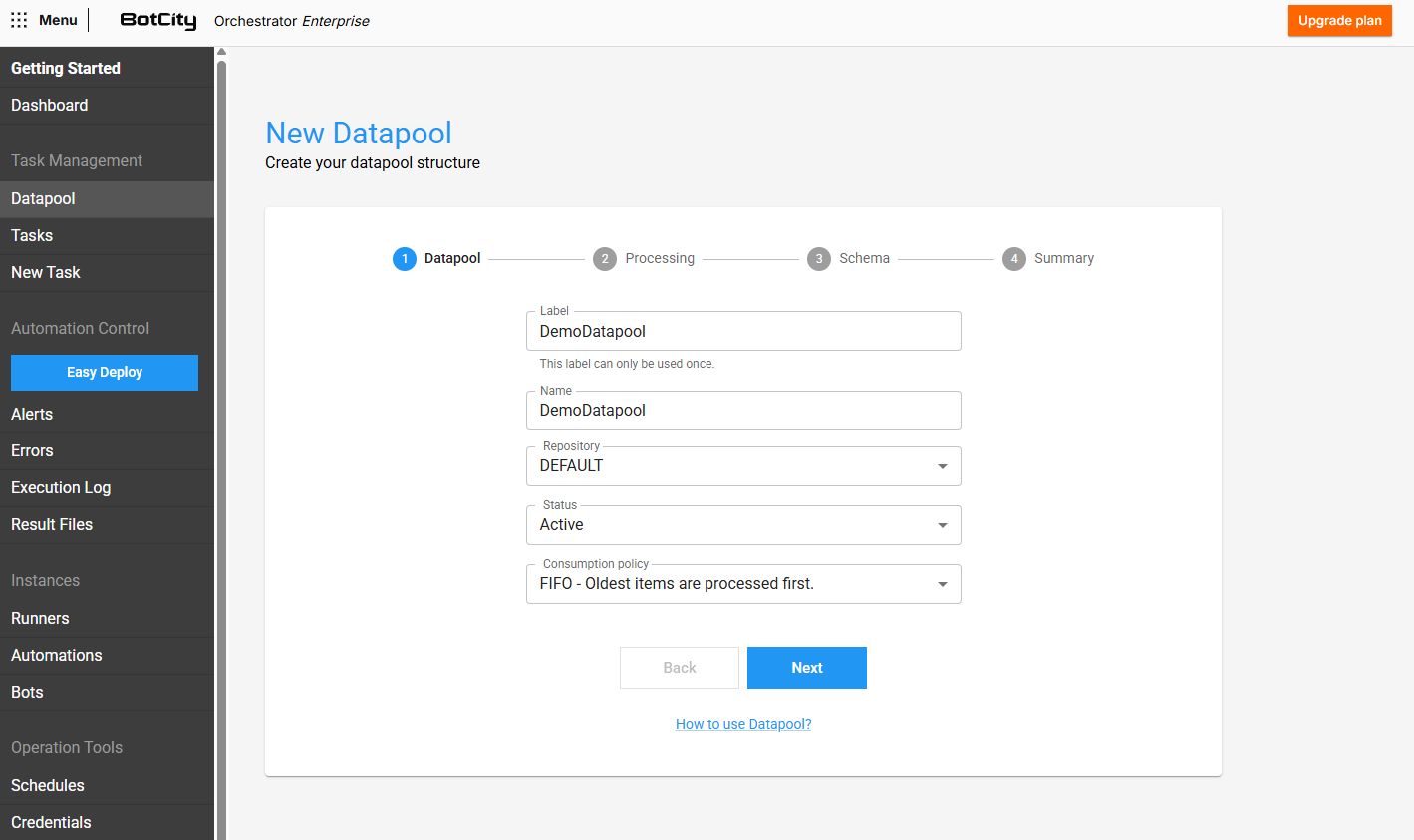
- Label: O identificador único que será utilizado para acessar o Datapool.
- Nome: O nome de exibição que será utilizado para identificar o Datapool.
- Repositório: O repositório do workspace onde o Datapool estará contido.
- Status: Se
ATIVO, o Datapool estará disponível para ser acessado e consumido. - Política de consumo: Você pode escolher entre duas políticas de consumo:
- FIFO: O primeiro item a ser adicionado ao Datapool também será o primeiro item a ser processado.
- LIFO: O último item a ser adicionado ao Datapool será o primeiro item a ser processado.
Etapa 2 - Configurações de Processamento¶
Nessa etapa, você deve configurar o comportamento do Datapool durante o processamento dos itens.
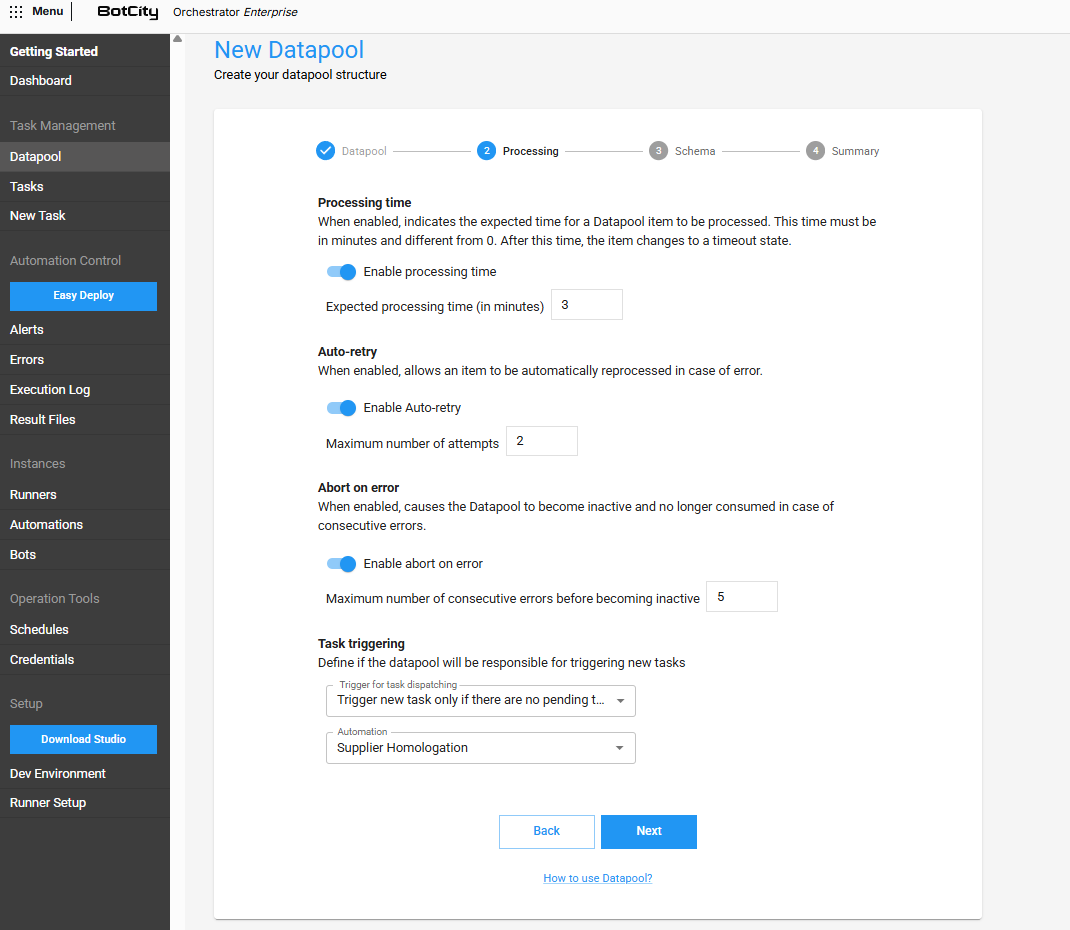
Tempo de processamento¶
Quando habilitado, permite definir qual o tempo esperado (em minutos) para que um item do Datapool seja processado em condições normais.
Auto-retry¶
Se habilitado, permite que um item seja reprocessado automaticamente em caso de erro.
- Número máximo de tentativas: O número máximo de tentativas para que um item seja processado com sucesso.
Importante
Somente itens com erro do tipo SYSTEM serão considerados para esse cenário.
Abortar em caso de erro¶
Se habilitado, faz com o que o Datapool fique inativo e não seja mais consumido em caso de erros consecutivos.
- Número máximo de erros consecutivos até ficar inativo: Quantidade máxima de itens processados com erro de forma consecutiva que serão tolerados até que o Datapool fique
INATIVO.
Importante
Somente itens com erro do tipo SYSTEM serão contabilizados para esse cenário.
Gatilhos e disparo de tarefas¶
Você pode definir se o Datapool criado também vai ser responsável por disparar novas tarefas:
- Nunca disparar nova tarefa: O Datapool nunca será responsável por disparar tarefas de um processo de automação.
- Disparar nova tarefa a cada item adicionado: Sempre que um novo item for adicionado ao Datapool, uma nova tarefa de um determinado processo de automação será criada.
- Disparar nova tarefa apenas se não houver tarefas pendentes: Sempre que um novo item for adicionado, o Datapool irá disparar uma nova tarefa de um processo de automação somente se não existirem tarefas desse processo sendo executadas ou pendentes.
- Automação: O processo de automação que será utilizado pelo Datapool para disparar novas tarefas, se algum gatilho estiver sendo utilizado.
Etapa 3 - Criação do Schema¶
Nessa etapa, você pode definir a estrutura dos itens que serão adicionados ao Datapool, ou seja, quais campos irão compor cada item.
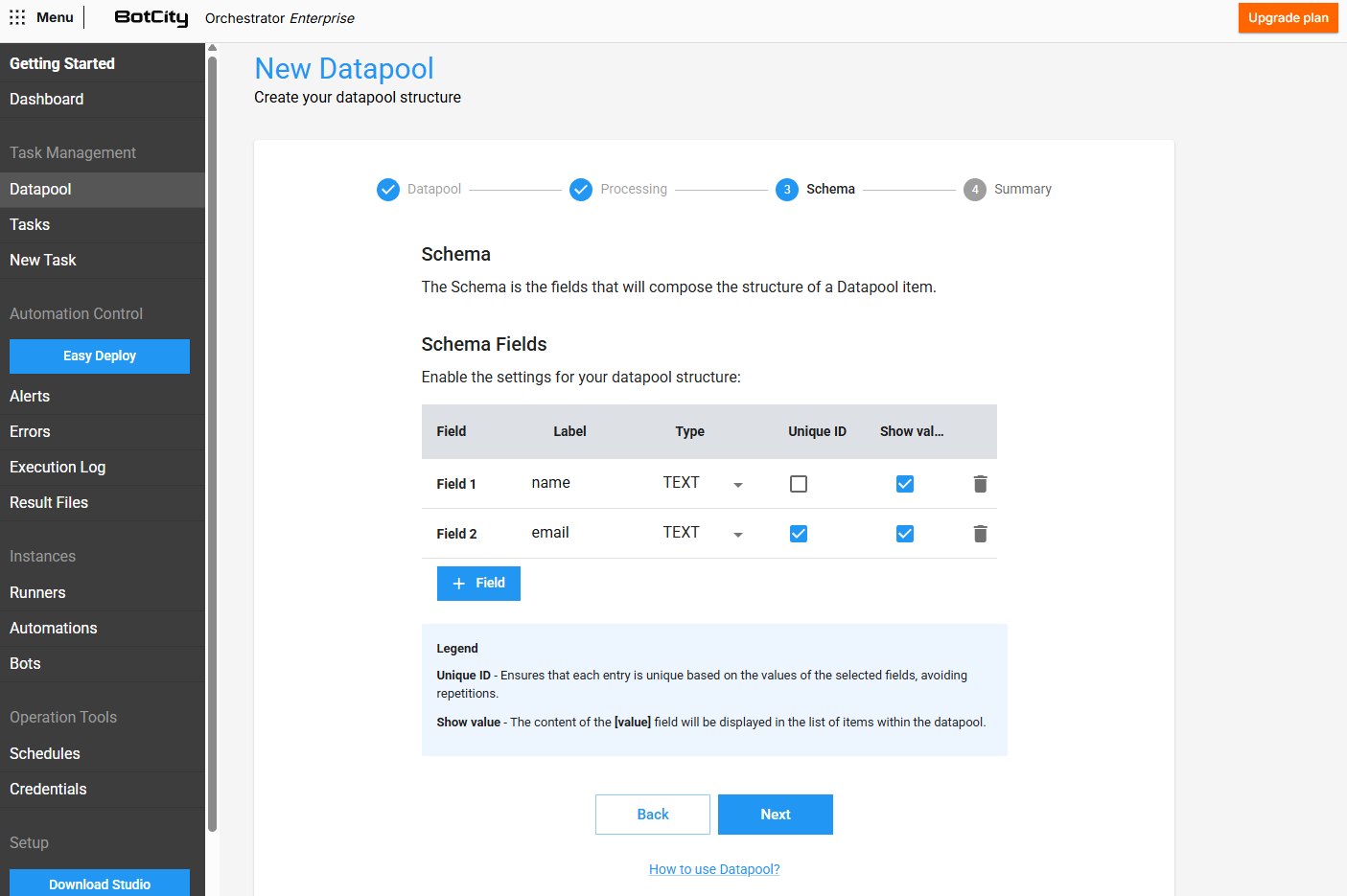
Para cada novo campo adicionado, você pode definir:
- Label: O identificador único que será utilizado para acessar esse campo.
- Tipo: O tipo esperado para o valor desse campo (
TEXT,INTEGER,DOUBLE). - ID único: Se marcado, o campo irá representar uma "chave única" para o item, ou seja, não será permitido adicionar itens duplicados que tenham o mesmo valor para esse campo em específico.
- Exibir valor: Se marcado, o valor desse campo será exibido na lista de itens do Datapool, servindo como um identificador visual para os itens em questão.
Etapa 4 - Resumo¶
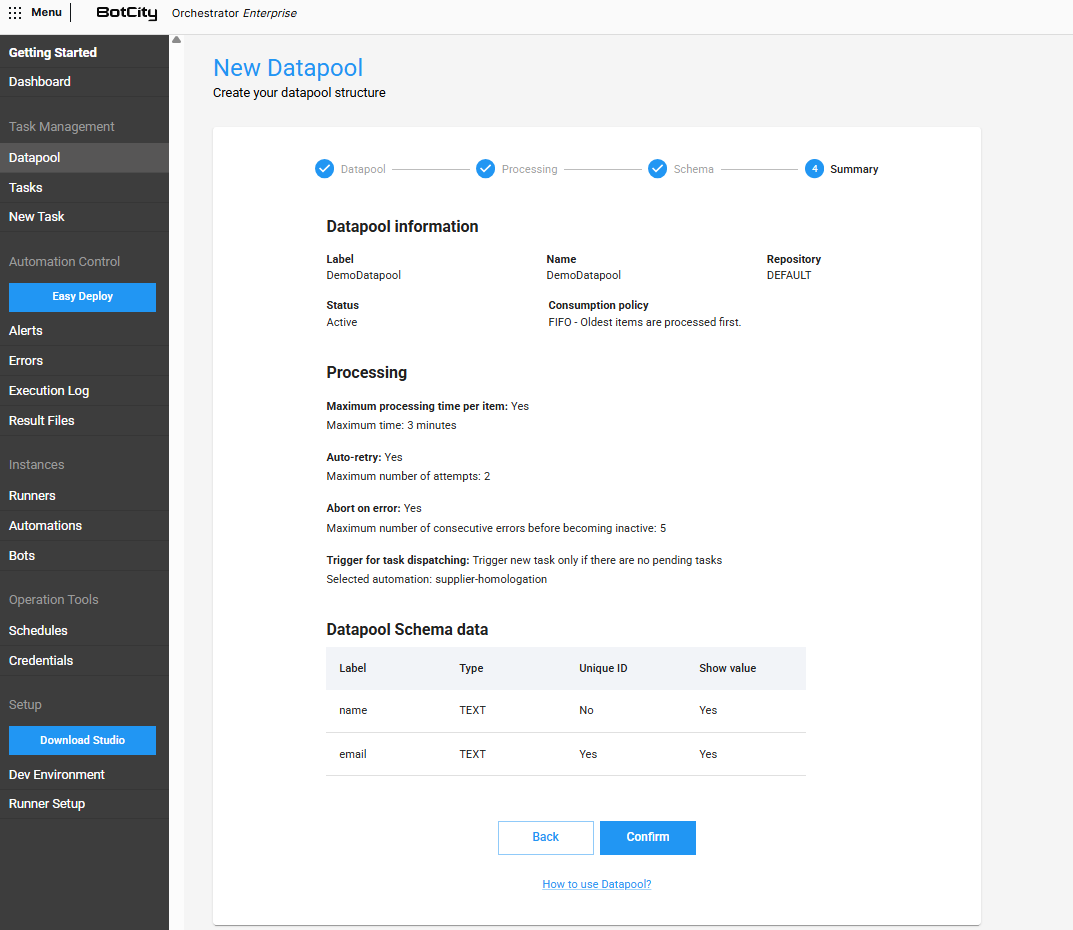
Nessa última etapa, você pode revisar todas as informações que foram definidas nas etapas anteriores e, se necessário, realizar ajustes antes de criar o Datapool.
Operações com o Datapool¶
Além da criação, você também pode realizar outras operações com o Datapool. Através do menu de ações, é possível:
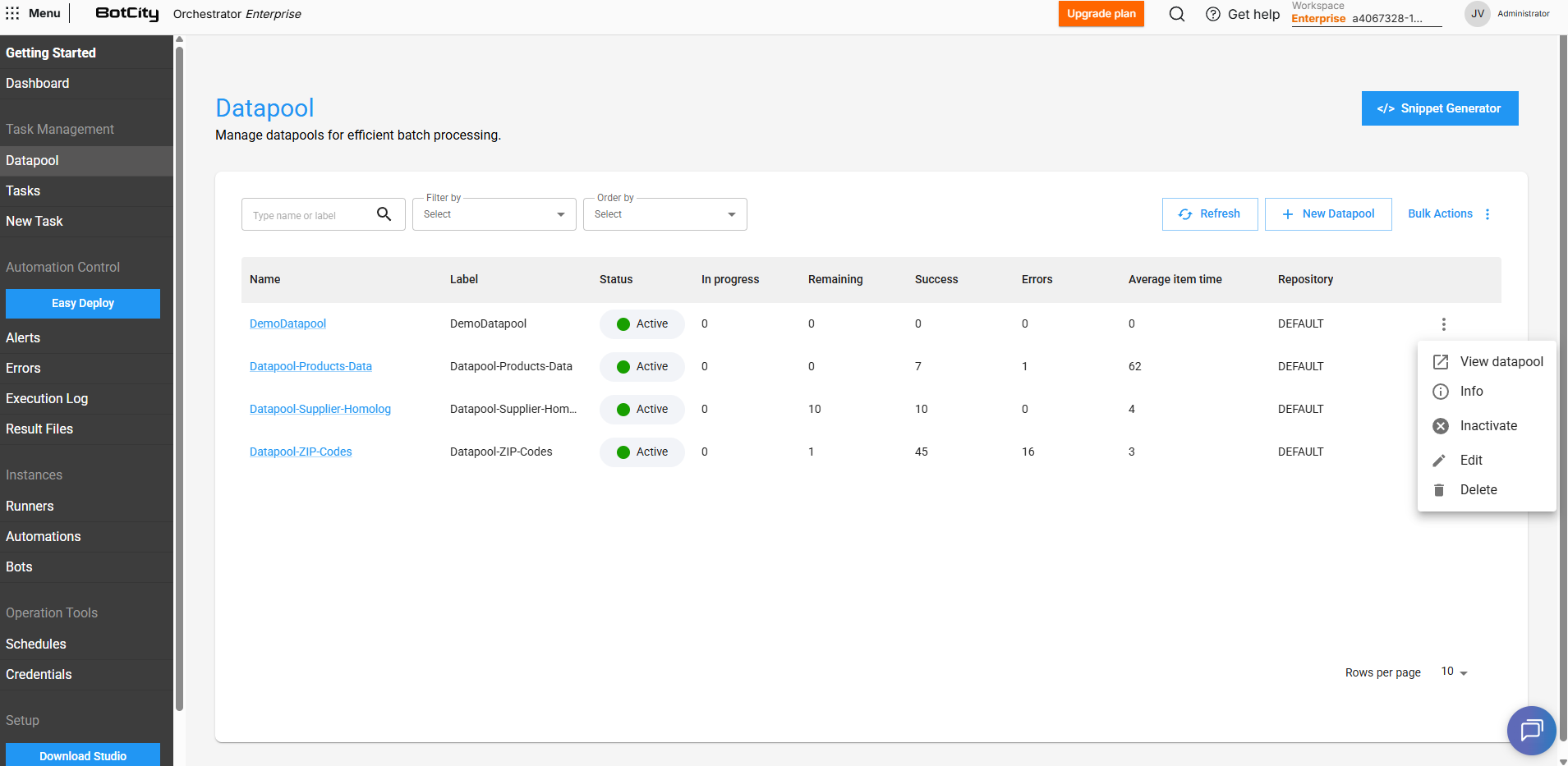
- Visualizar o painel principal e as informações atualmente configuradas para o Datapool.
- Ativar ou deixar o Datapool inativo, ou seja, permitir que os itens adicionados sejam consumidos ou não.
- Editar as configurações que foram definidas anteriormente.
- Excluir o Datapool, removendo-o permanentemente do workspace no Orquestrador.
Próximos Passos¶
Com a estrutura do Datapool criada e configurada, o próximo passo é começarmos a adicionar os itens que serão processados.