Primeros Pasos¶
Creando un Datapool¶
Para crear un nuevo Datapool, simplemente haz clic en + Nuevo Datapool y configúralo en 4 pasos simples:
Paso 1 - Información Básica¶
En este paso, debes proporcionar la información inicial sobre el Datapool que se está creando.
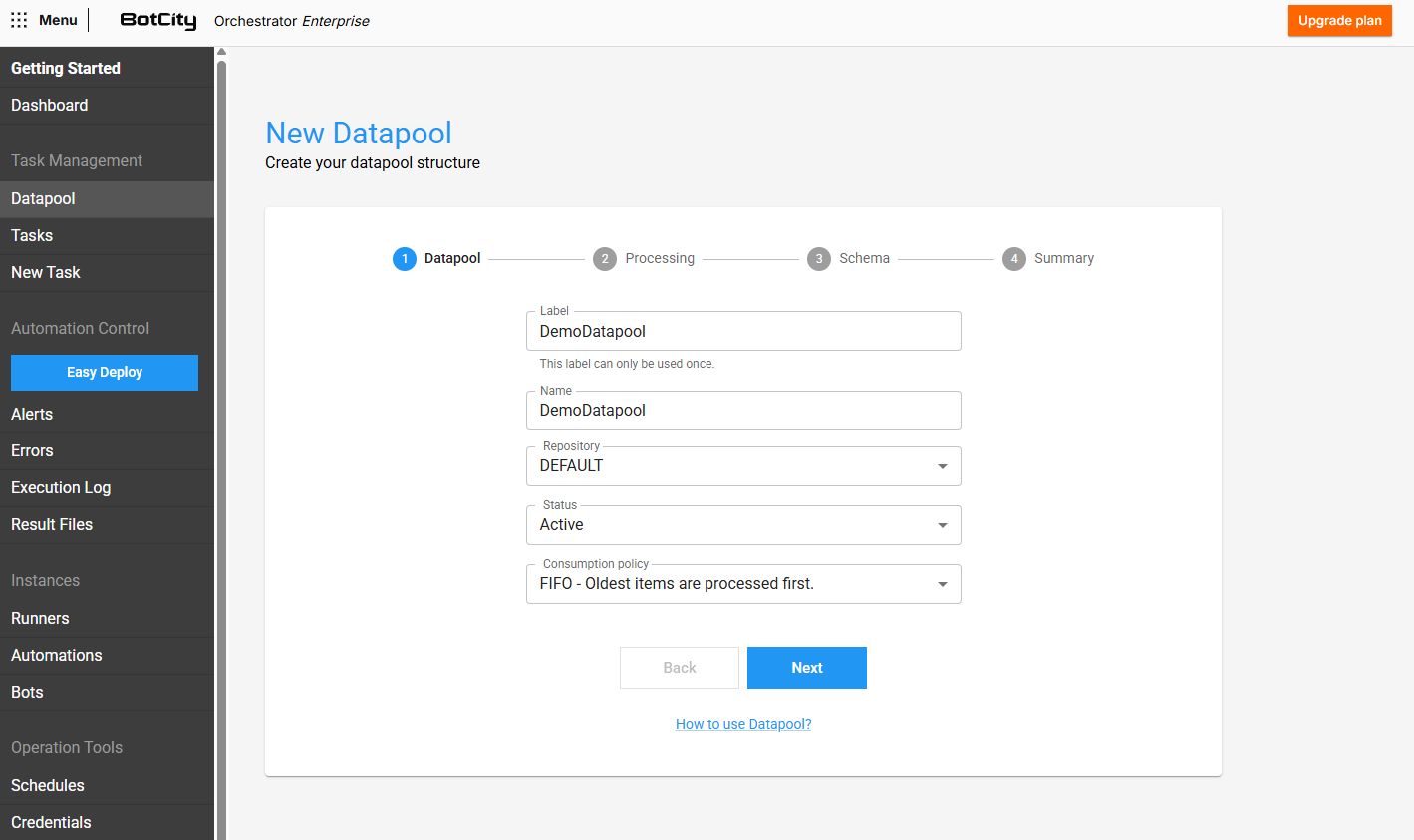
- Etiqueta: El identificador único que se utilizará para acceder al Datapool.
- Nombre: El nombre de visualización que se utilizará para identificar el Datapool.
- Repositorio: El repositorio del espacio de trabajo donde estará contenido el Datapool.
- Estado: Si está
ACTIVO, el Datapool estará disponible para ser accedido y consumido. - Política de consumo: Puedes elegir entre dos políticas de consumo:
- FIFO: El primer elemento que se agregue al Datapool también será el primer elemento en ser procesado.
- LIFO: El último elemento que se agregue al Datapool será el primer elemento en ser procesado.
Paso 2 - Configuraciones de Procesamiento¶
En este paso, debes configurar el comportamiento del Datapool durante el procesamiento de elementos.
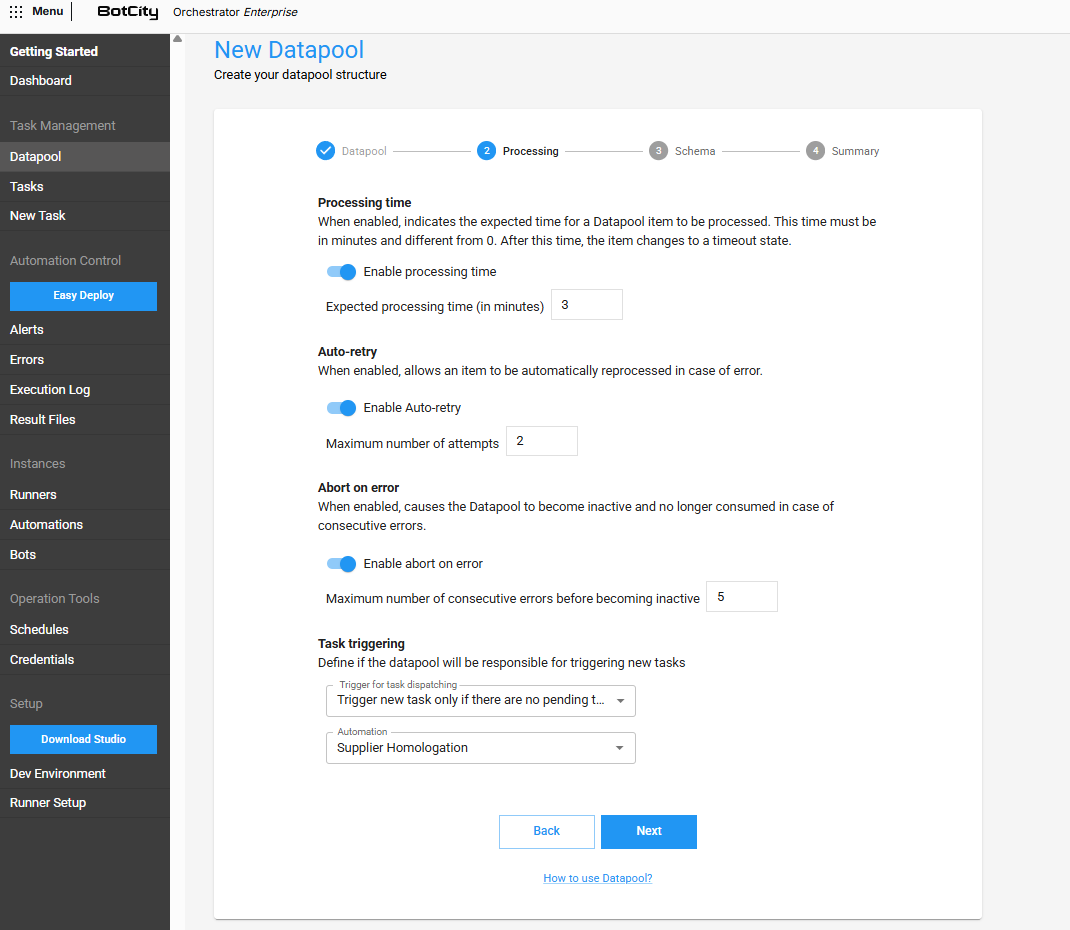
Tiempo de procesamiento¶
Cuando está habilitado, permite definir el tiempo esperado (en minutos) para que un elemento del Datapool sea procesado en condiciones normales.
Auto-reintento¶
Si está habilitado, permite que un elemento sea reprocesado automáticamente en caso de error.
- Número máximo de intentos: El número máximo de intentos para que un elemento sea procesado exitosamente.
Importante
Solo los elementos con error de tipo SYSTEM serán considerados para este escenario.
Abortar en caso de error¶
Si está habilitado, hace que el Datapool se vuelva inactivo y ya no sea consumido en caso de errores consecutivos.
- Número máximo de errores consecutivos hasta quedar inactivo: Cantidad máxima de elementos procesados con error de forma consecutiva que serán tolerados hasta que el Datapool se vuelva
INACTIVO.
Importante
Solo los elementos con error de tipo SYSTEM serán contabilizados para este escenario.
Disparadores y activación de tareas¶
Puedes definir si el Datapool creado también será responsable de activar nuevas tareas:
- Nunca disparar nueva tarea: El Datapool nunca será responsable de activar tareas de un proceso de automatización.
- Disparar nueva tarea por cada elemento añadido: Cada vez que se agregue un nuevo elemento al Datapool, se creará una nueva tarea de un proceso de automatización específico.
- Disparar nueva tarea solo si no hay tareas pendientes: Cada vez que se agregue un nuevo elemento, el Datapool activará una nueva tarea de un proceso de automatización solo si no hay tareas de este proceso siendo ejecutadas o pendientes.
- Automatización: El proceso de automatización que será utilizado por el Datapool para activar nuevas tareas, si se está utilizando algún disparador.
Paso 3 - Creación del Esquema¶
En este paso, puedes definir la estructura de los elementos que serán agregados al Datapool, es decir, qué campos compondrán cada elemento.
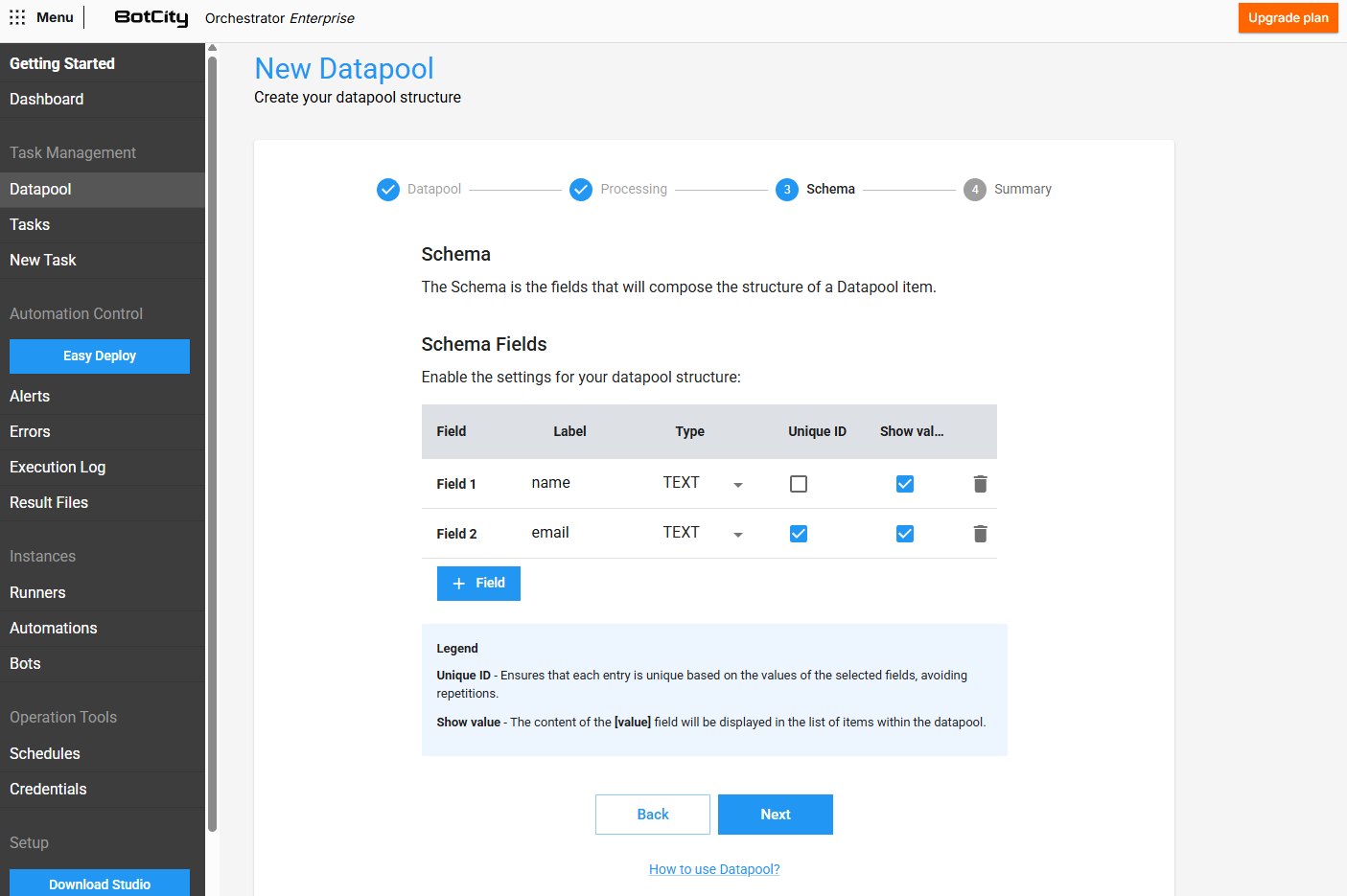
Para cada nuevo campo agregado, puedes definir:
- Etiqueta: El identificador único que se utilizará para acceder a este campo.
- Tipo: El tipo esperado para el valor de este campo (
TEXT,INTEGER,DOUBLE). - ID único: Si está marcado, el campo representará una "clave única" para el elemento, lo que significa que no se permitirá añadir elementos duplicados que tengan el mismo valor para este campo específico.
- Mostrar valor: Si está marcado, el valor de este campo se mostrará en la lista de elementos del Datapool, sirviendo como un identificador visual para los elementos en cuestión.
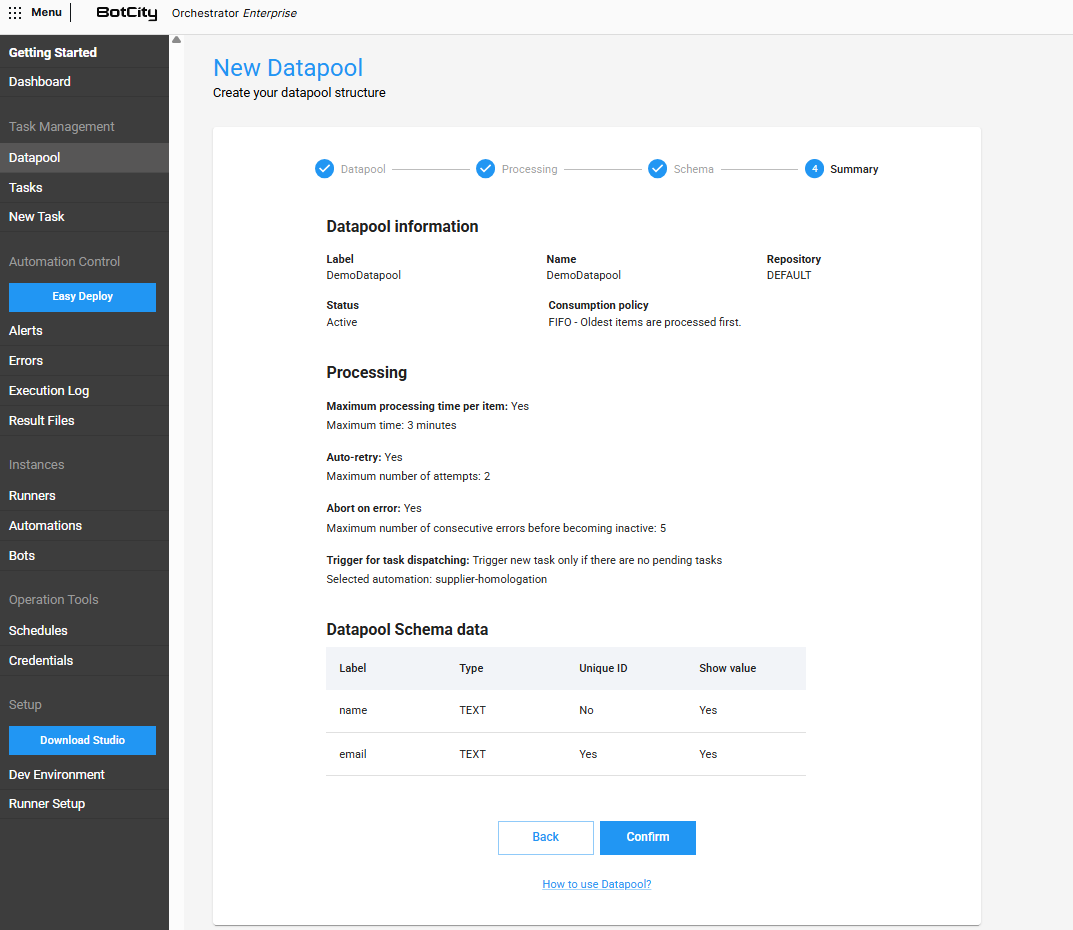
Paso 4 - Resumen¶
En este paso final, puedes revisar toda la información que fue definida en los pasos anteriores y, si es necesario, realizar ajustes antes de crear el Datapool.
Operaciones del Datapool¶
Además de la creación, también puedes realizar otras operaciones con el Datapool. A través del menú de acciones, es posible:
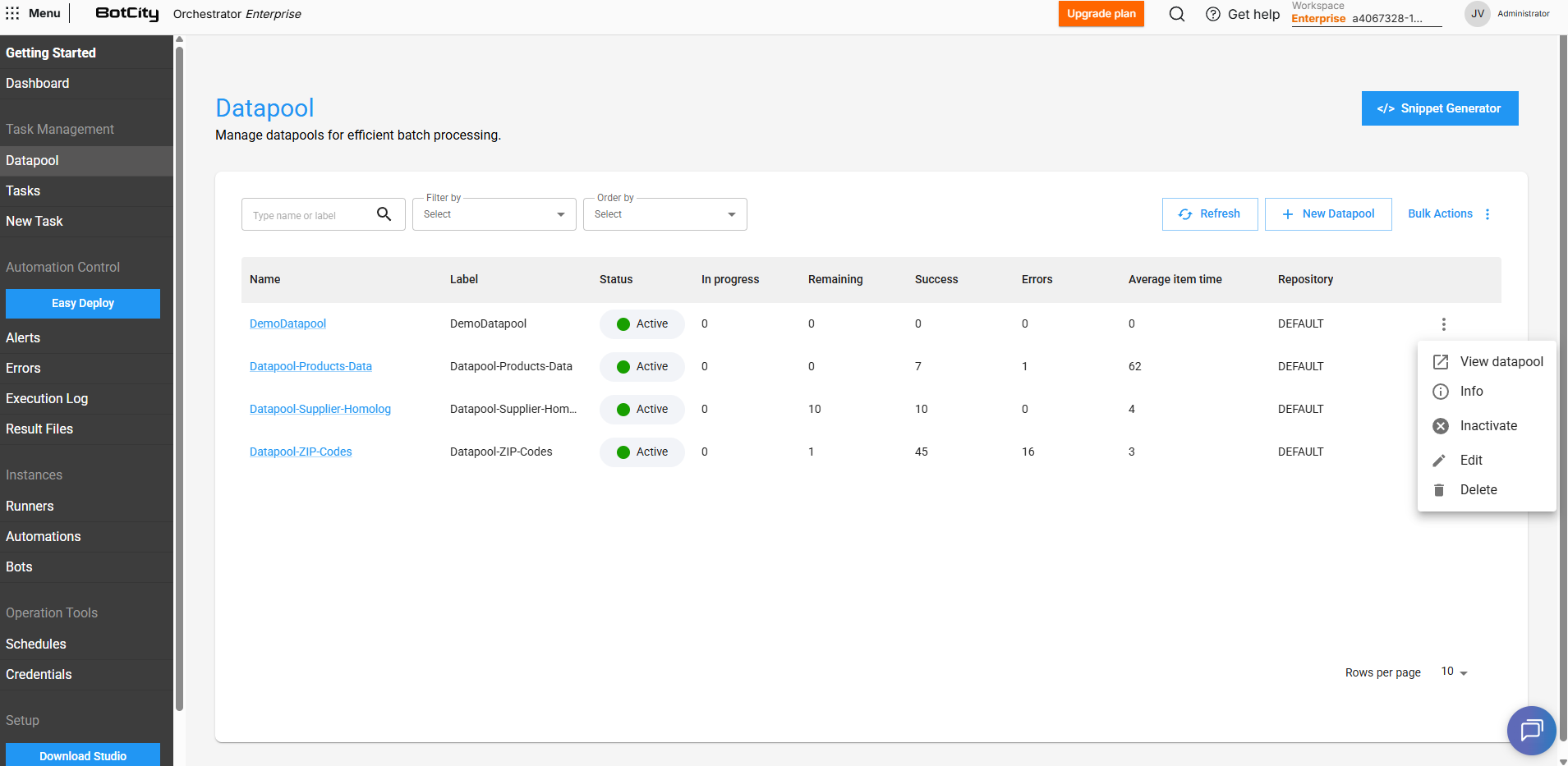
- Ver el panel principal y la información actualmente configurada para el Datapool.
- Activar o desactivar el Datapool, es decir, permitir que los elementos agregados sean consumidos o no.
- Editar las configuraciones que fueron definidas previamente.
- Eliminar el Datapool, removiéndolo permanentemente del espacio de trabajo en el Orquestador.
Próximos Pasos¶
Con la estructura del Datapool creada y configurada, el próximo paso es comenzar a añadir los elementos que serán procesados.