Septiembre¶
Datapool¶
Estamos felices de anunciar las novedades del proyecto que llamamos internamente Datapool 2.0. Después de meses de investigación profunda con los usuarios y un ciclo de desarrollo e implementación dedicado, presentamos una serie de nuevas características diseñadas cuidadosamente para ayudar a los usuarios a procesar elementos con mayor eficiencia y obtener información más detallada sobre sus datos.
Creación y Configuración de Datapools¶
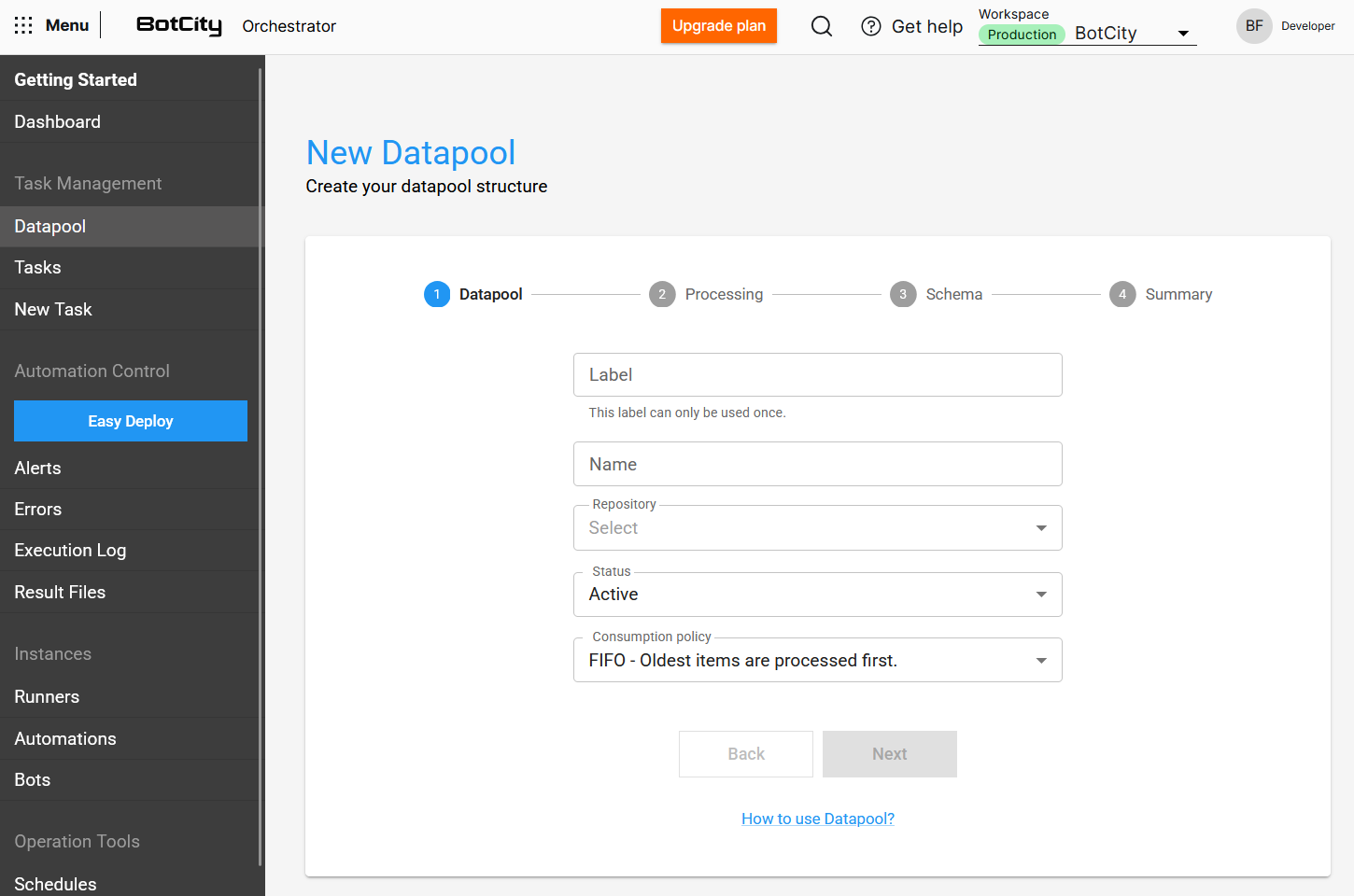
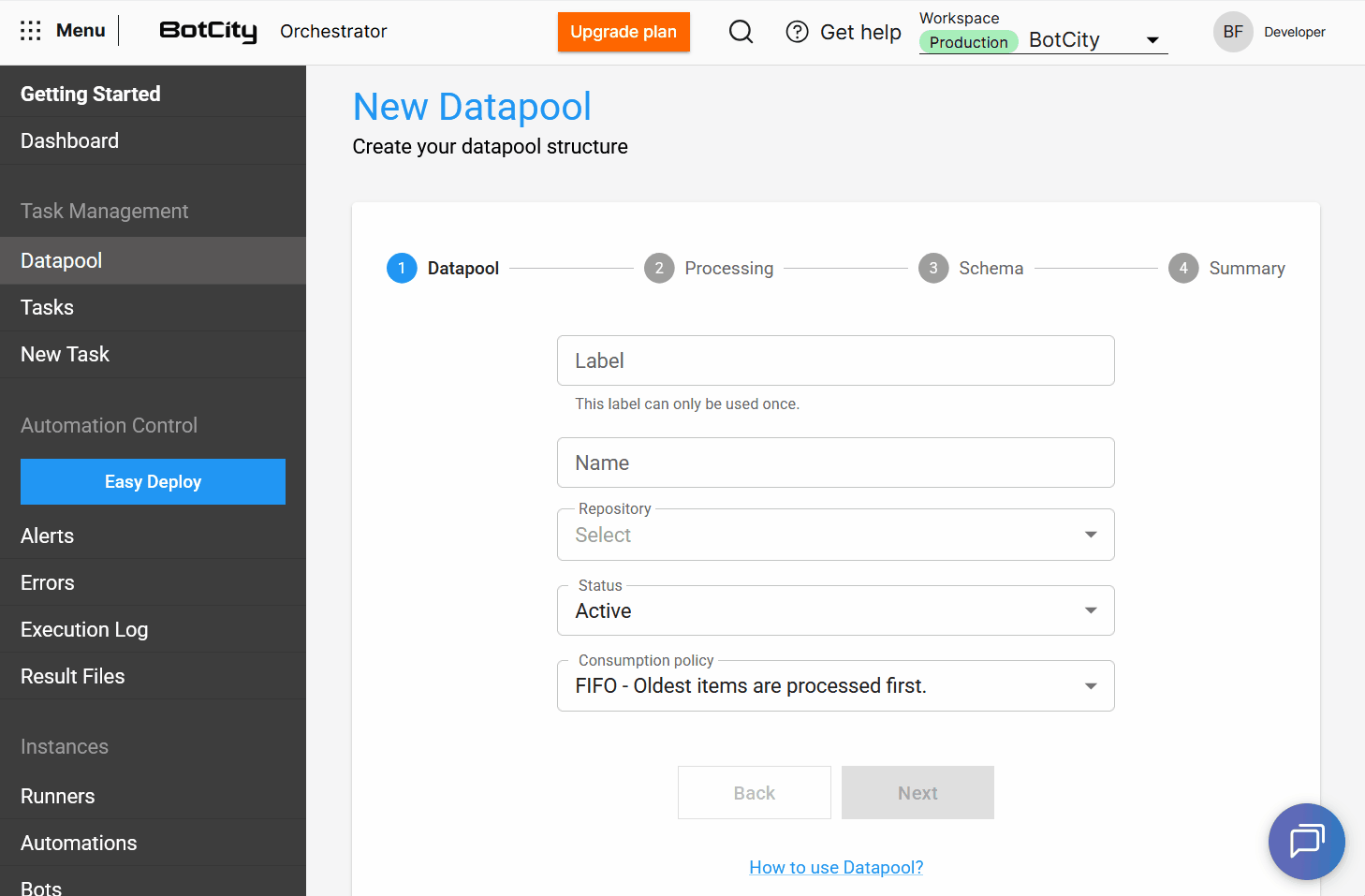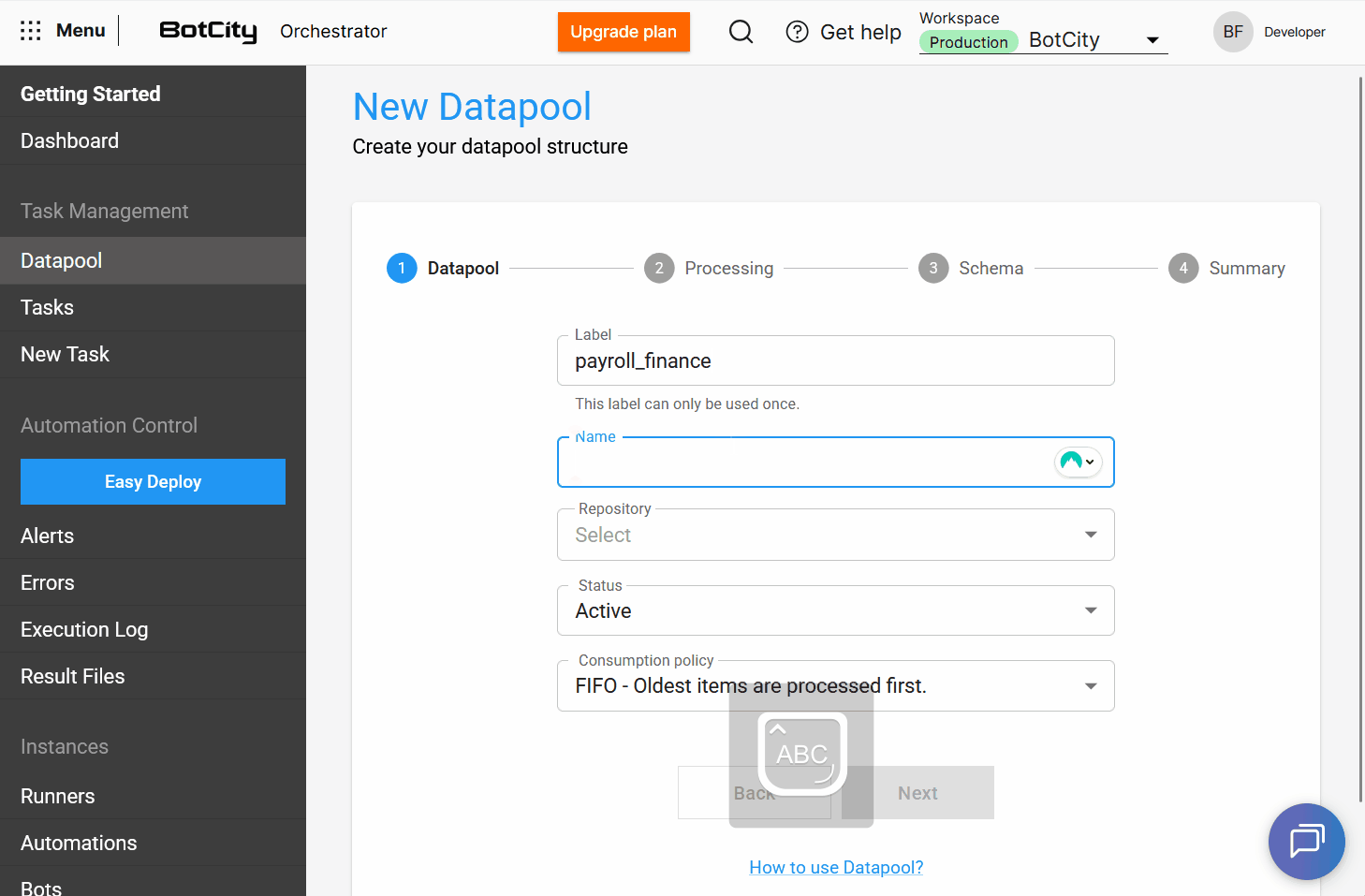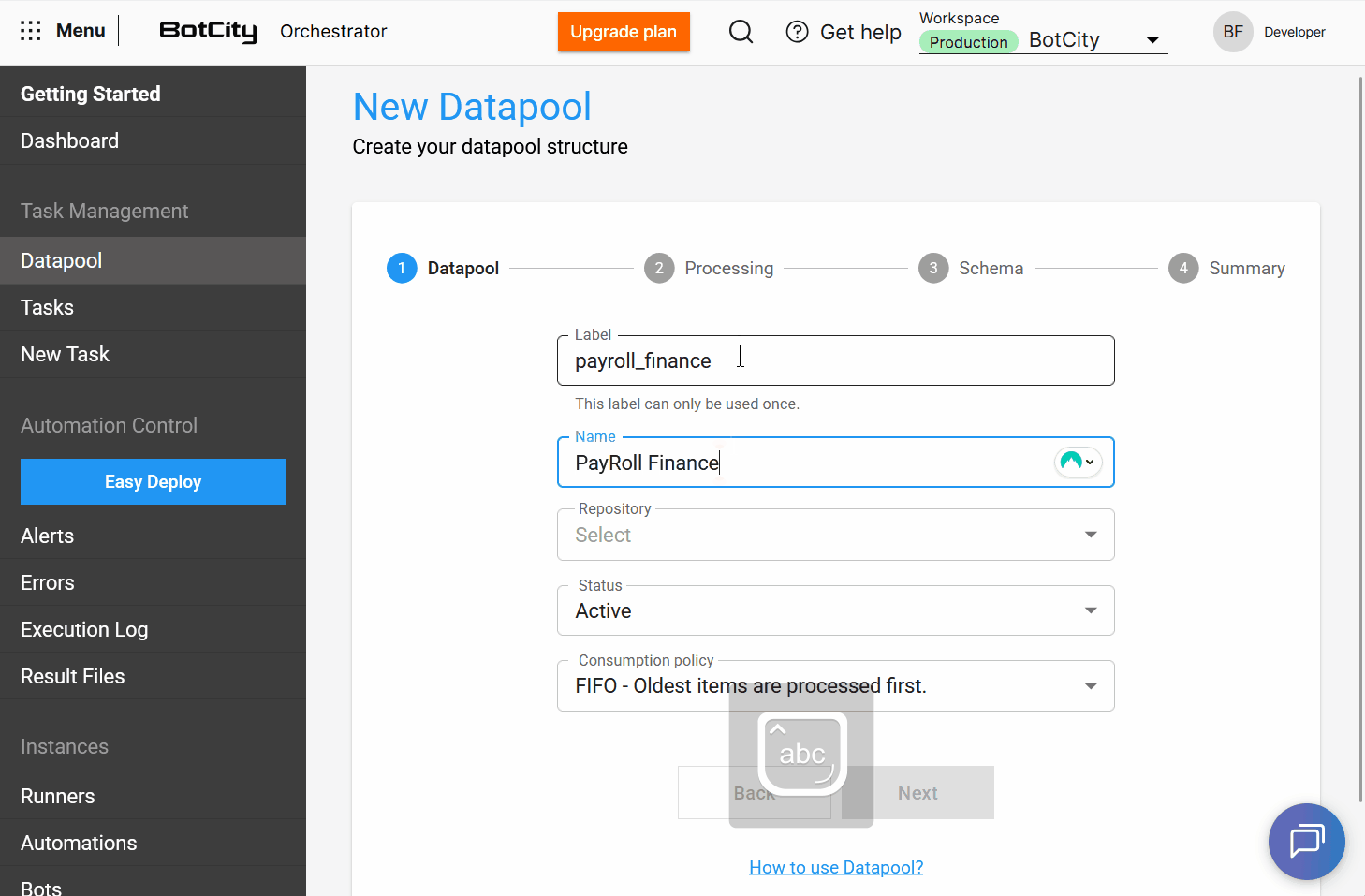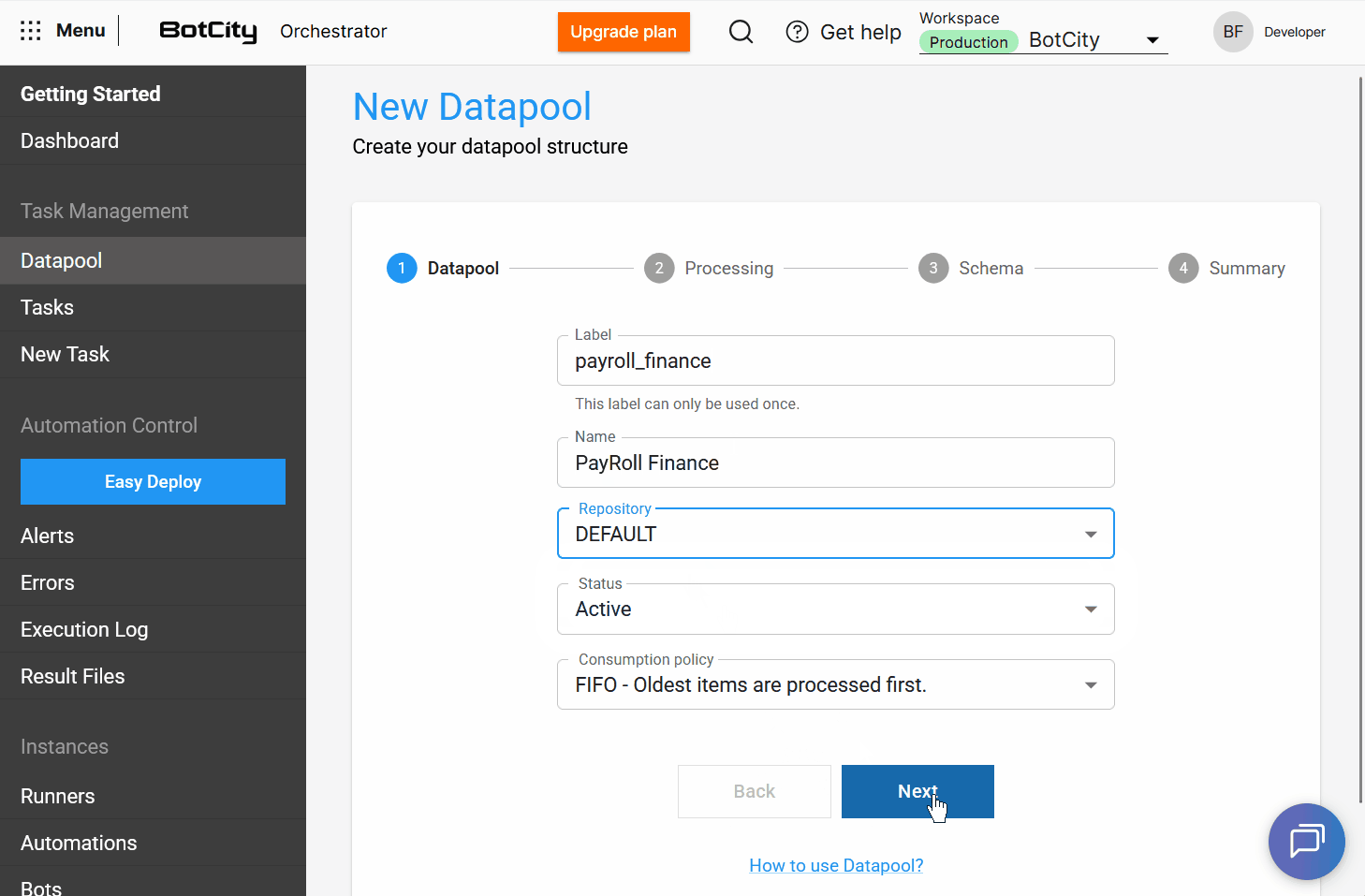
La creación de un nuevo Datapool ahora es un proceso intuitivo, guiado por pasos que garantizan una configuración completa y precisa. Además de las mejoras en la interfaz, se han añadido características que hacen que el Datapool sea más robusto y flexible.
Proceso de Creación por Pasos¶
La interfaz de creación se ha reestructurado en un flujo paso a paso para facilitar la configuración:
- Datapool: Configure la información básica del Datapool.
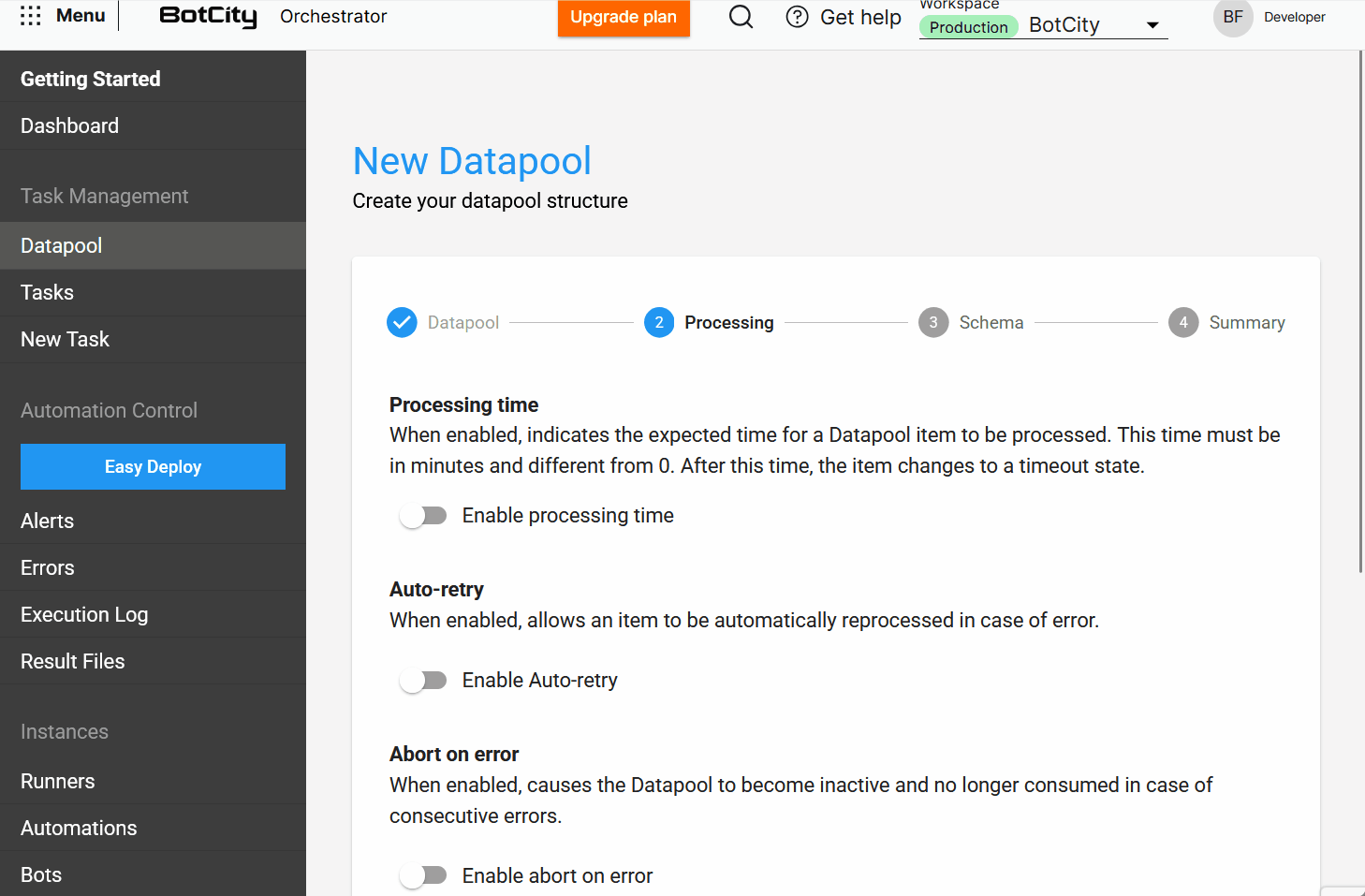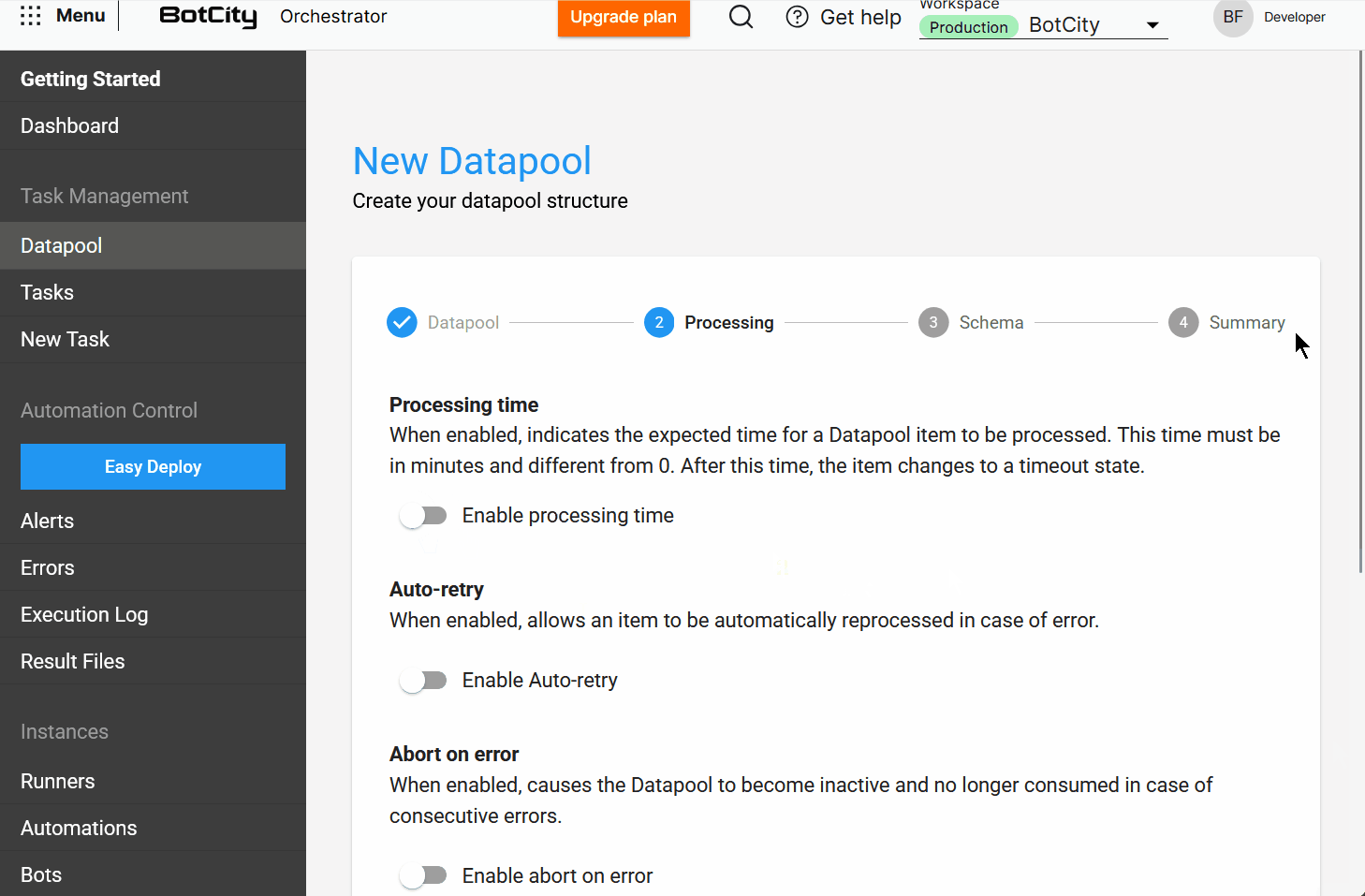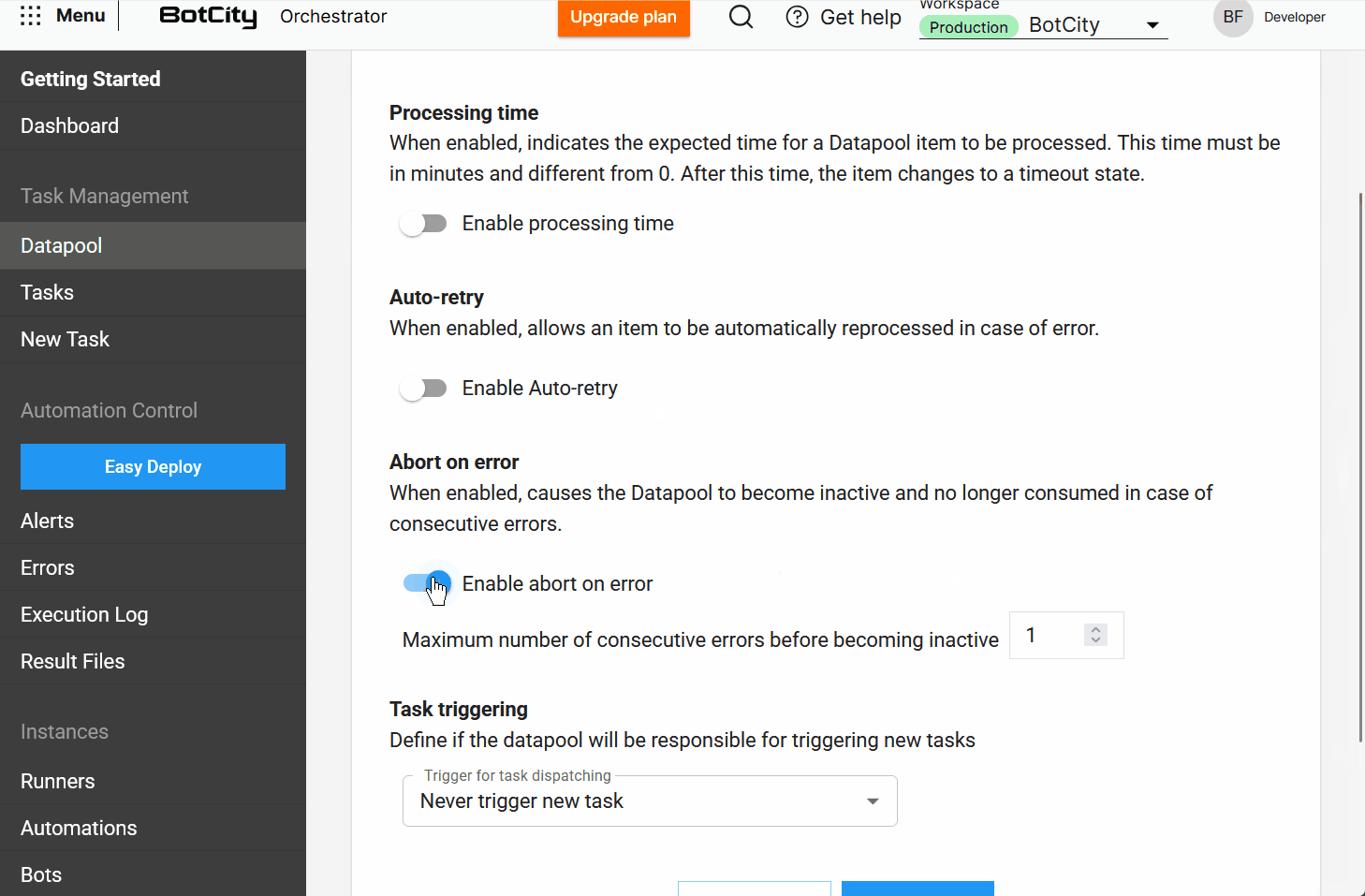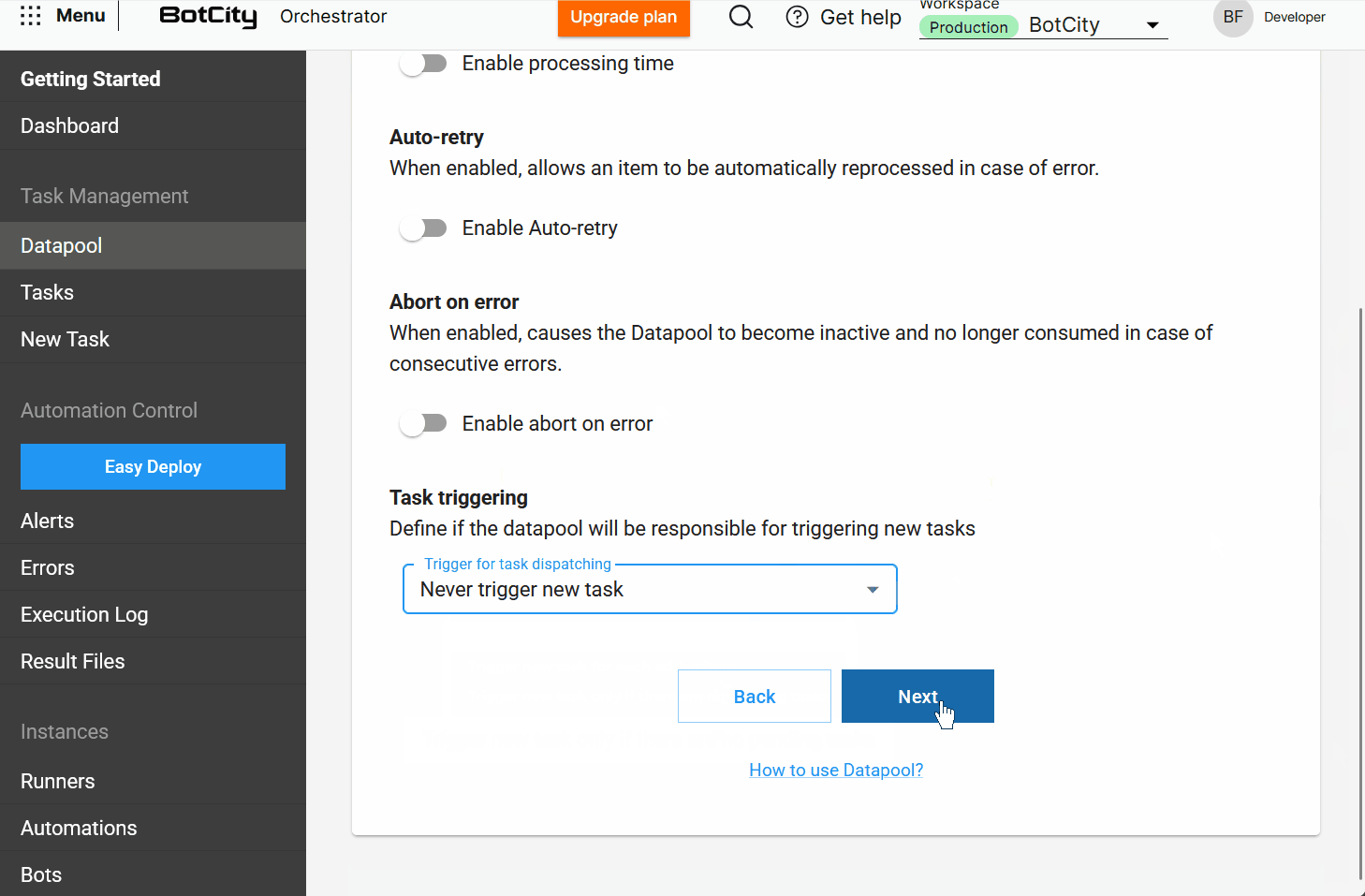
- Procesamiento: Defina cómo se procesarán los elementos. Aquí, el usuario encuentra opciones como
tiempo de procesamiento,auto-reintento,abortar en caso de errorydisparo de tareas. - Esquema: Configure la estructura de datos para procesar los elementos.
- Resumen: Revise todas las elecciones realizadas antes de finalizar la creación del Datapool.
Características de Configuración¶
A partir de esta actualización, el Datapool permite a los usuarios asignar una etiqueta y un nombre a su estructura.
etiqueta: es un identificador único en el sistema y no puede repetirse.nombre: es una identificación amigable para la lista principal de Datapools y puede repetirse si la estructura se recrea.
Línea de Texto Explicativa en todas las características del Datapool, con una línea de texto explicativa que describe la funcionalidad y el propósito de cada opción, ayudando al usuario en la configuración.
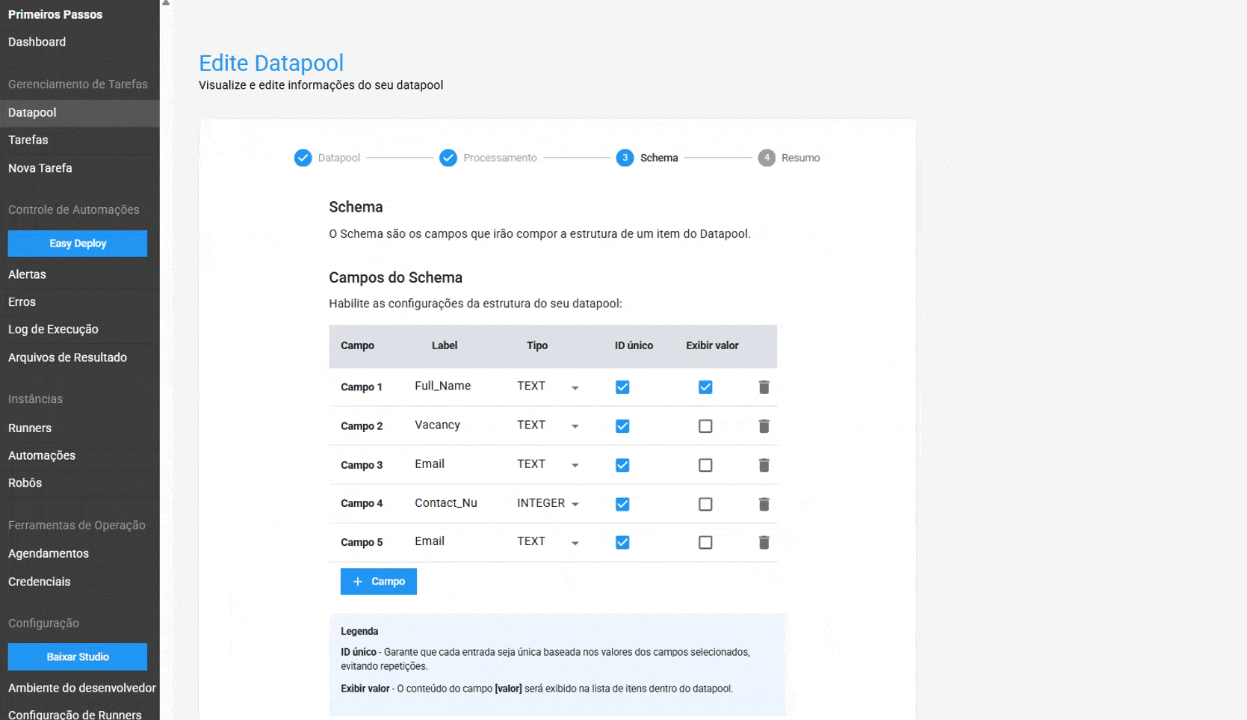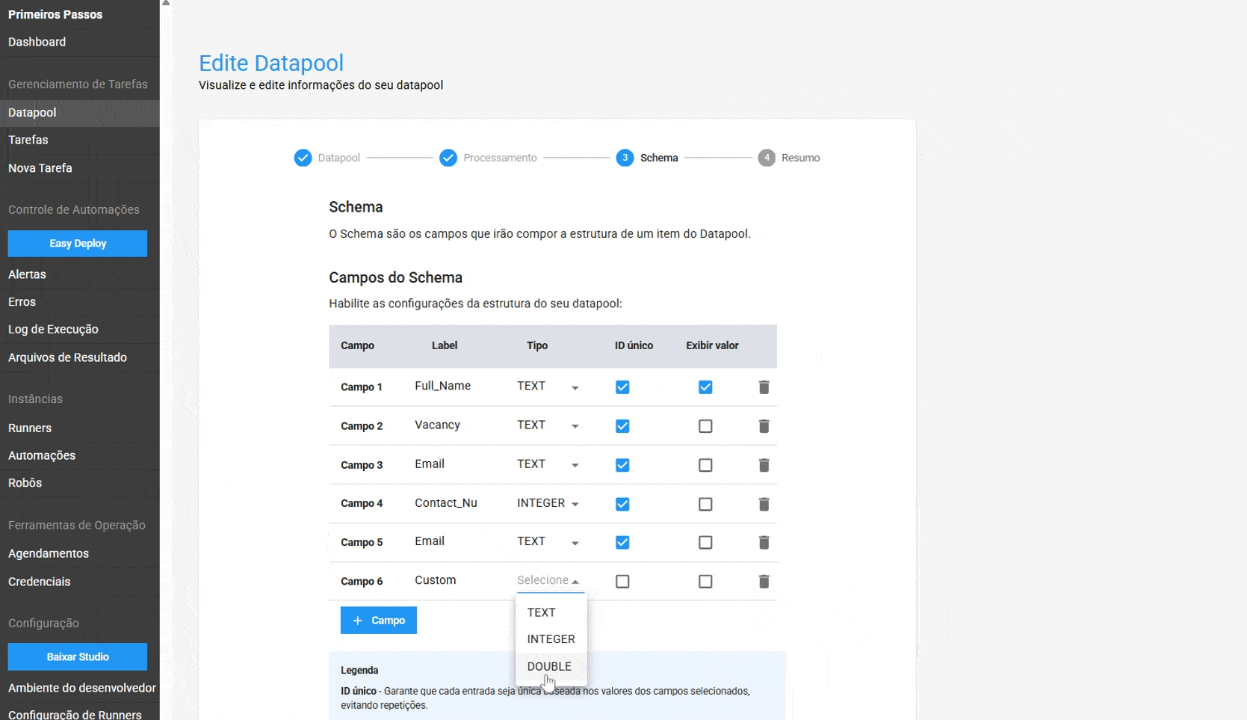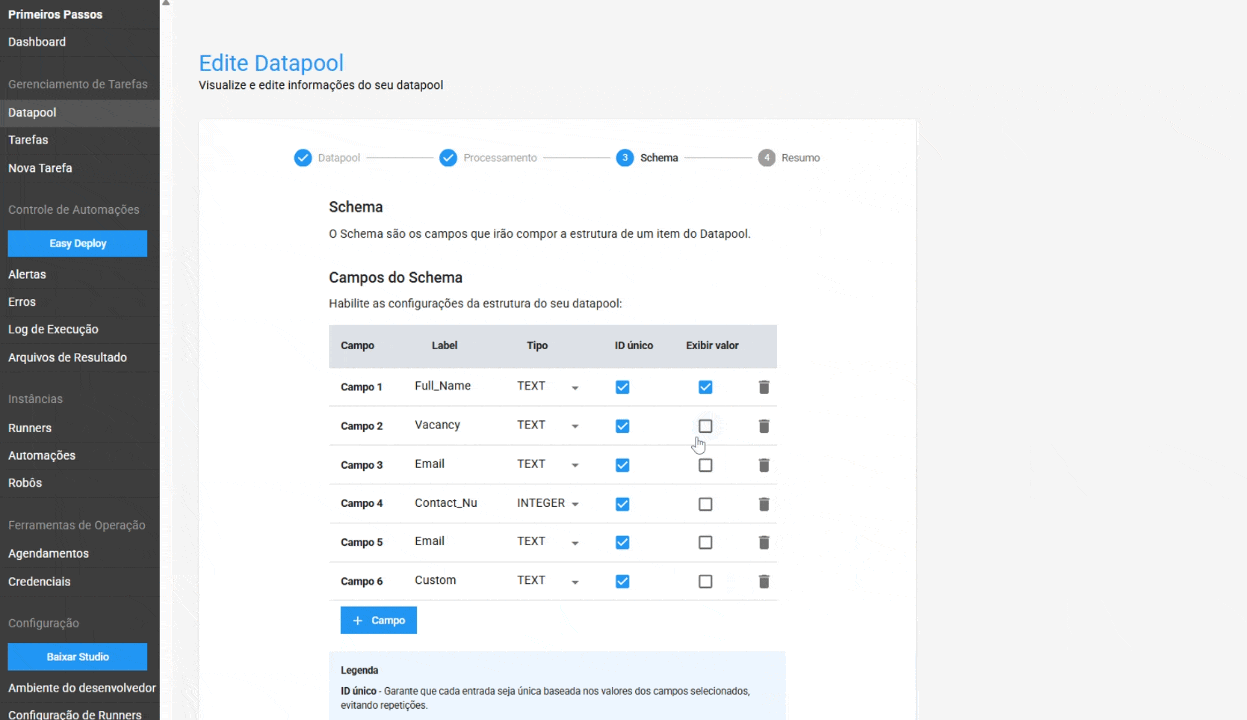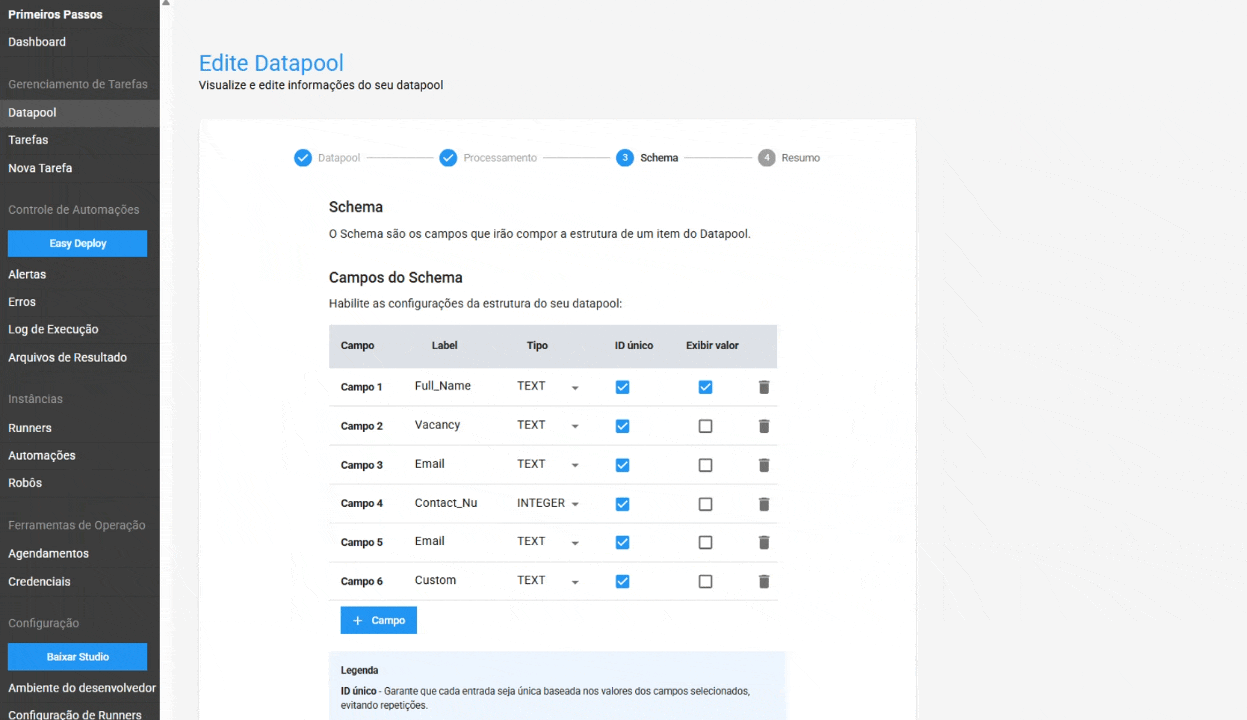
En el Esquema, se han añadido configuraciones para:
- ID Único en el Esquema: al activar esta opción, el Datapool garantiza que cada entrada sea única, basada en los valores de los campos seleccionados. Esto ayuda a evitar la duplicación de datos y garantiza la integridad de la información. Esta característica es opcional.
- Visualización de valor en la tabla de elementos: permite al usuario mostrar el contenido de un campo específico directamente en la tabla de elementos del Datapool, facilitando la localización y gestión de un elemento. Esta es una característica opcional.
Gestión y Manipulación de Elementos¶
Las mejoras en la gestión y manipulación de elementos se han actualizado para dar a los usuarios más control y visibilidad sobre el procesamiento de sus datos.
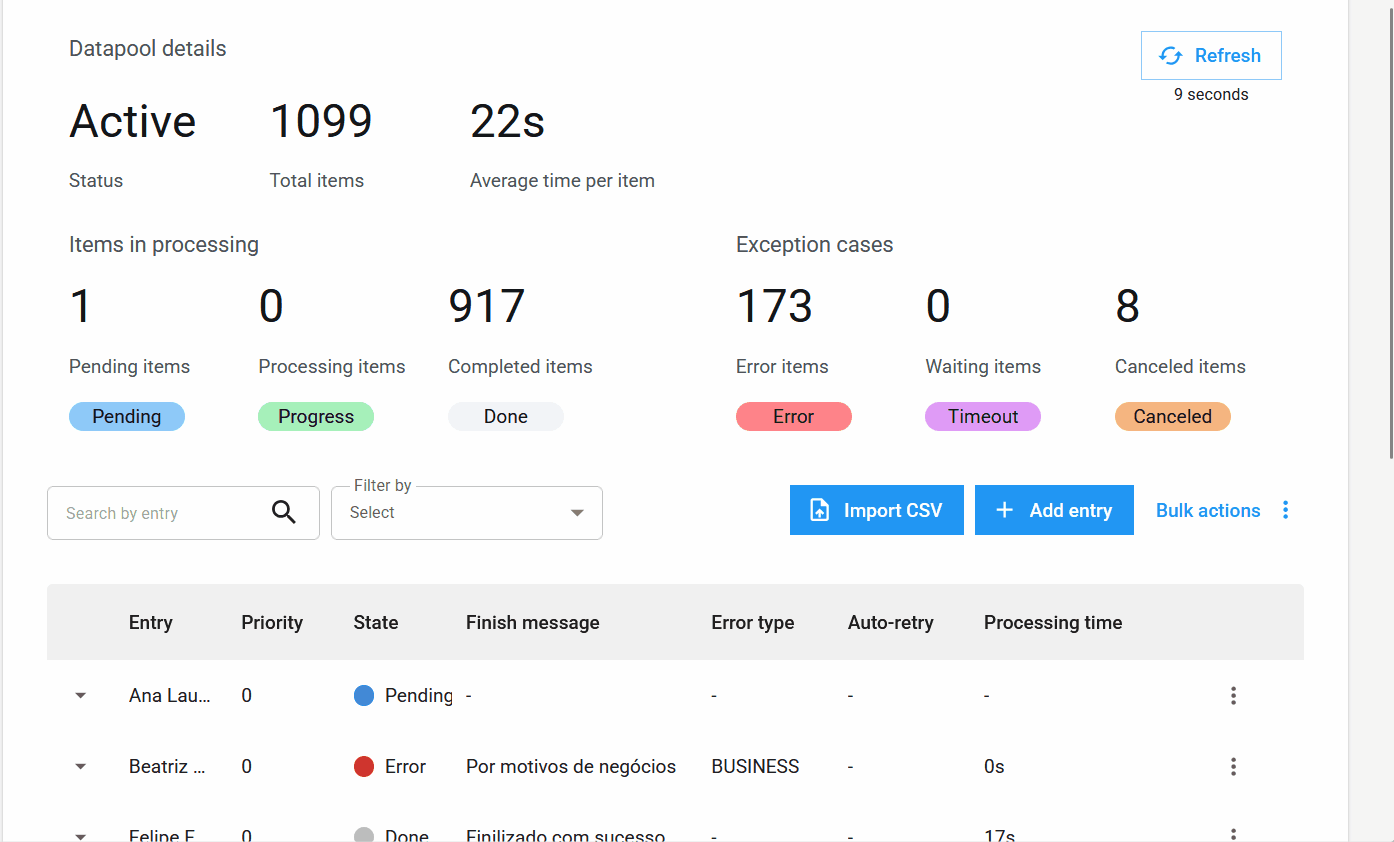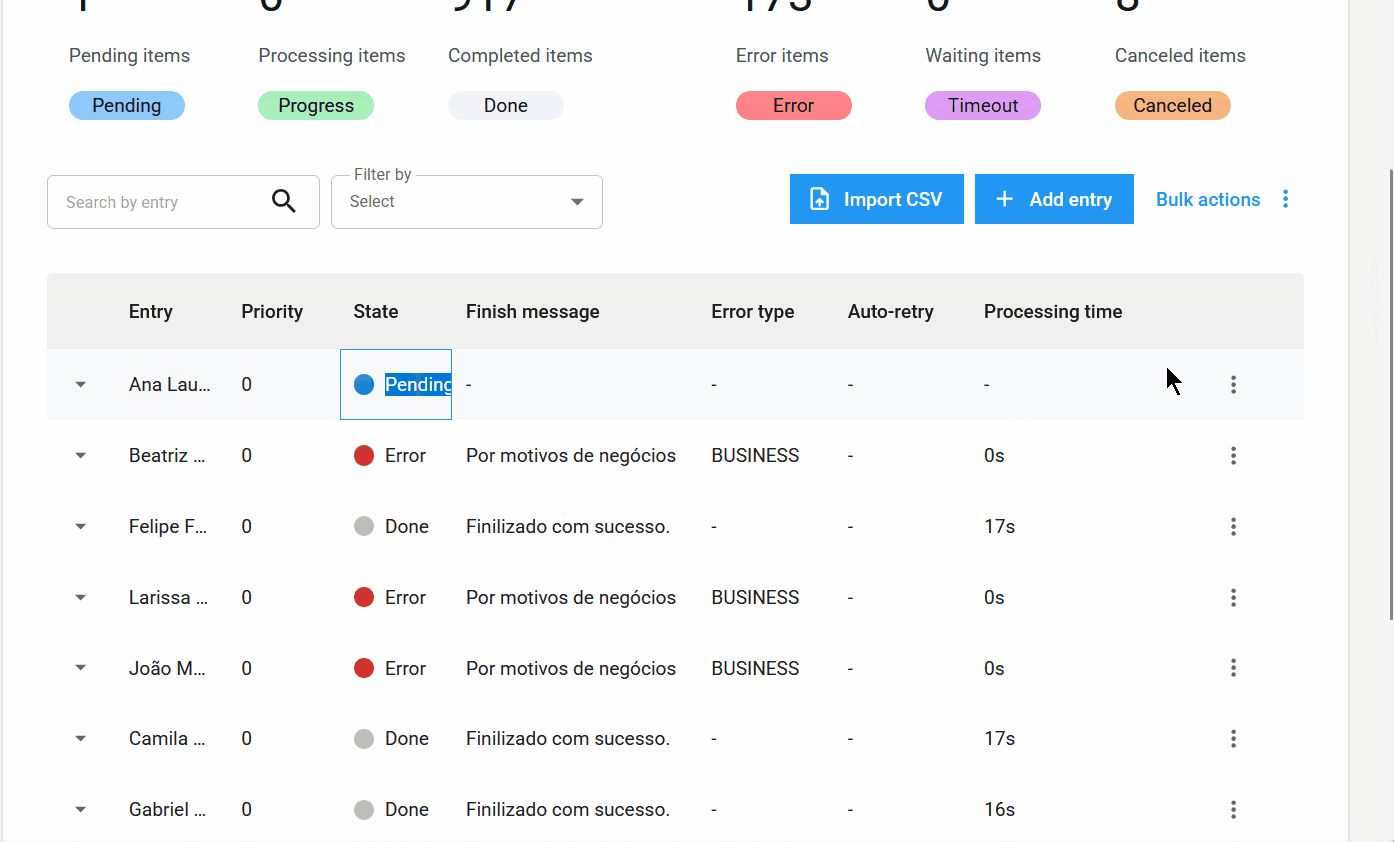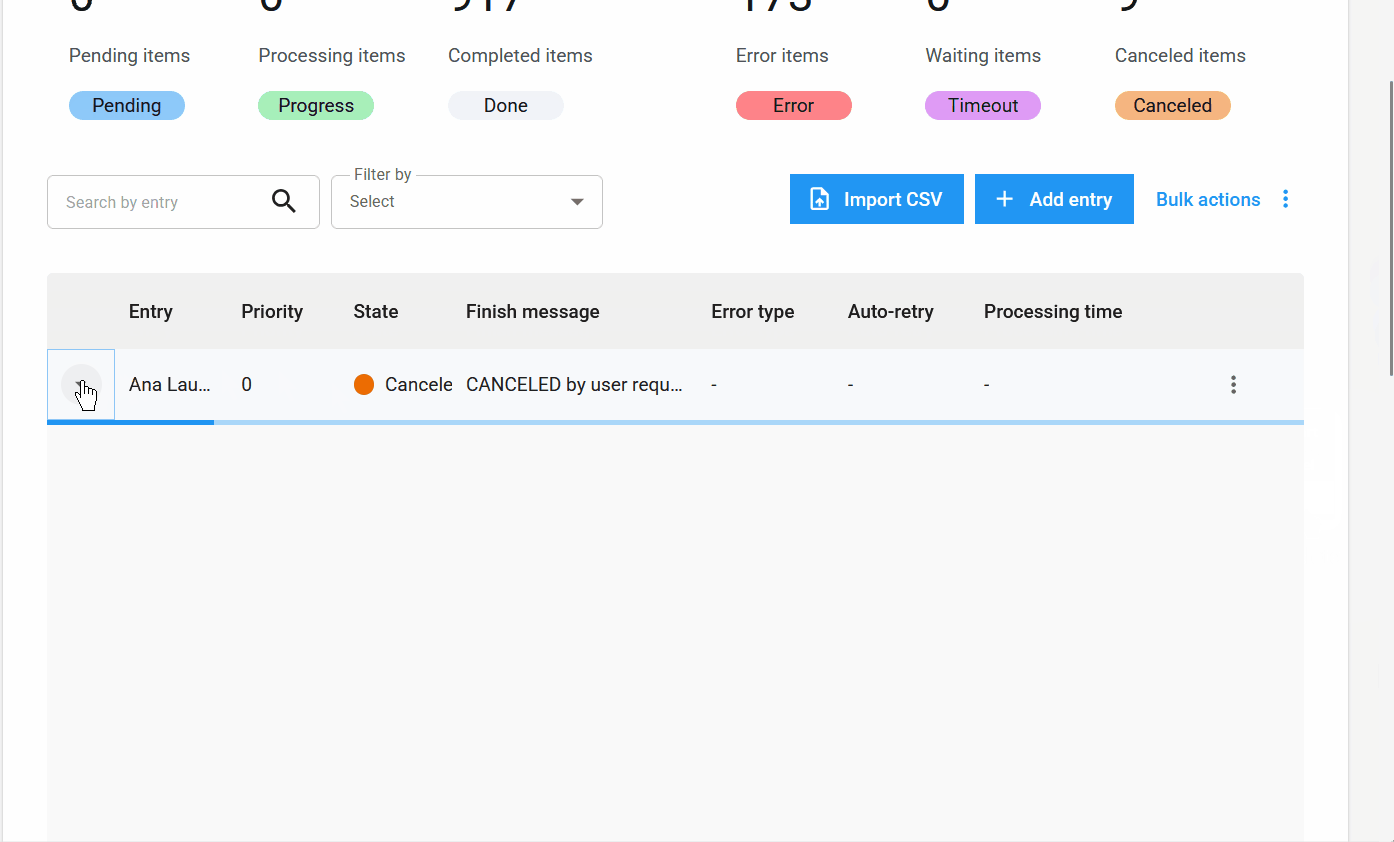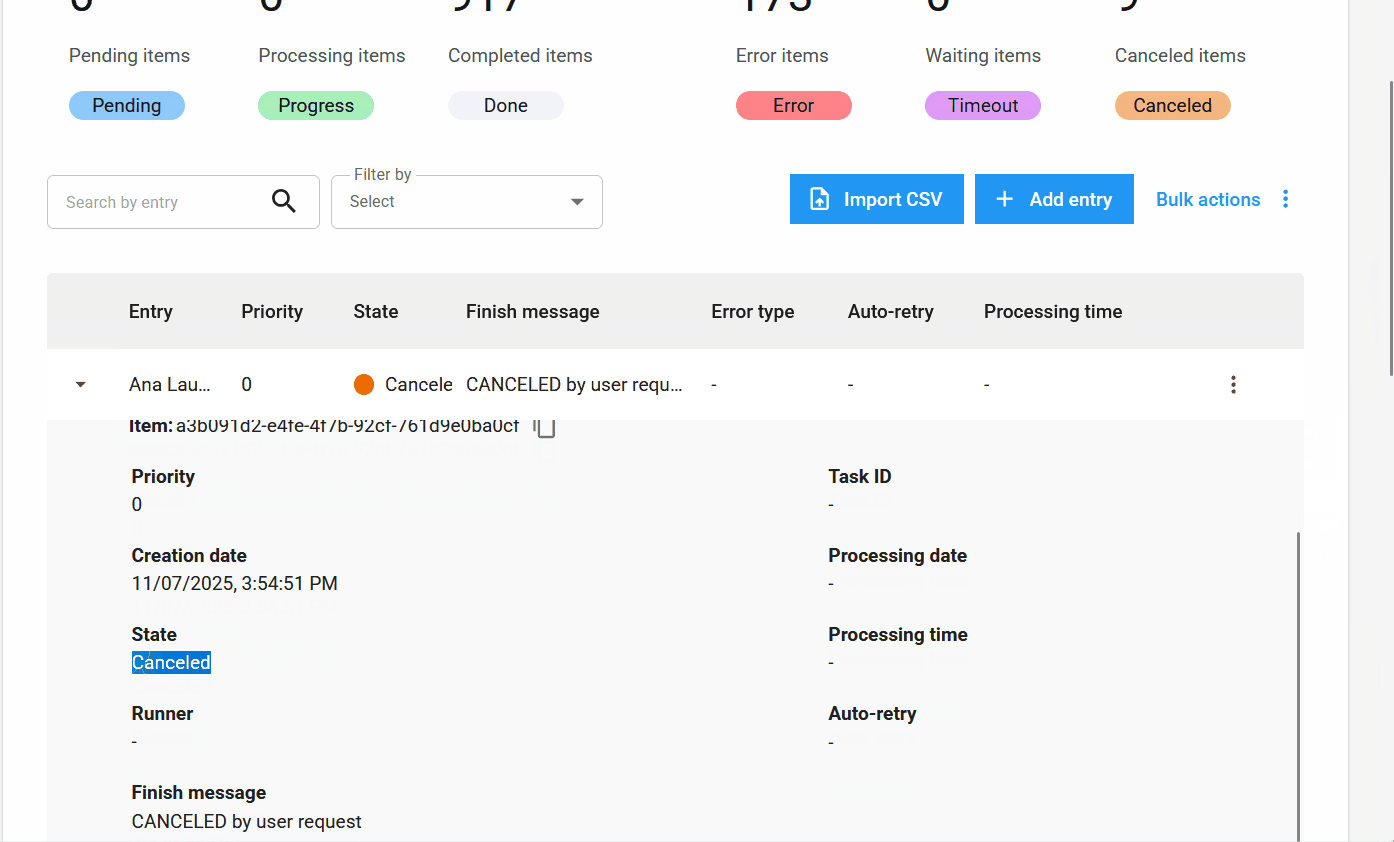
Nuevas columnas en la Tabla de Procesamiento¶
La tabla de elementos se ha ampliado para incluir columnas esenciales para el monitoreo:
- Entrada: Refleja el identificador del elemento, que puede ser único, un valor de campo o un hash.
- Prioridad: La prioridad definida para el procesamiento.
- Estado: El estado actualizado del elemento.
- Mensaje de Finalización: Mensajes de conclusión, error o cancelación que ofrecen información sobre el resultado del procesamiento.
- Tipo de Error: Indica si el error fue de negocio o del sistema.
- Auto-reintento: Muestra si el elemento es un reintento automático y cuál es su conteo actual.
- Tiempo de Procesamiento: El tiempo empleado en el procesamiento de un elemento.
- Ciclo de Vida: El tiempo total desde la creación del elemento hasta su finalización.
Nuevos Estados e Información de Elementos¶
Nuevo estado de elemento: Cancelado.
Además de los estados Pendiente, Procesando, Completado, Error y Timeout, se añade el nuevo estado Cancelado. Este se aplica cuando el usuario cancela un elemento antes de que sea procesado.
Acciones en Masa y Mejoras de Usabilidad¶
- Eliminación de Elementos en Masa: Los usuarios pueden eliminar elementos en los estados
Pendientes,Completados,Error,TimeoutyCanceladosmediante el botón de acciones en masa. Tenga en cuenta: la eliminación de un elemento es irreversible.
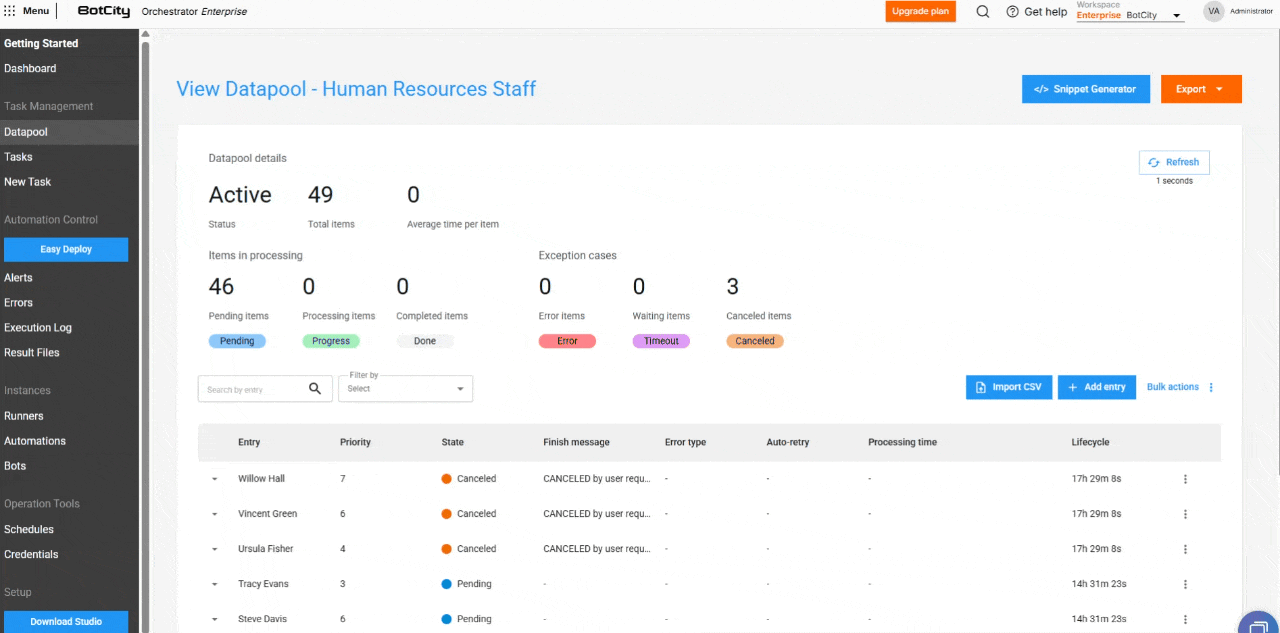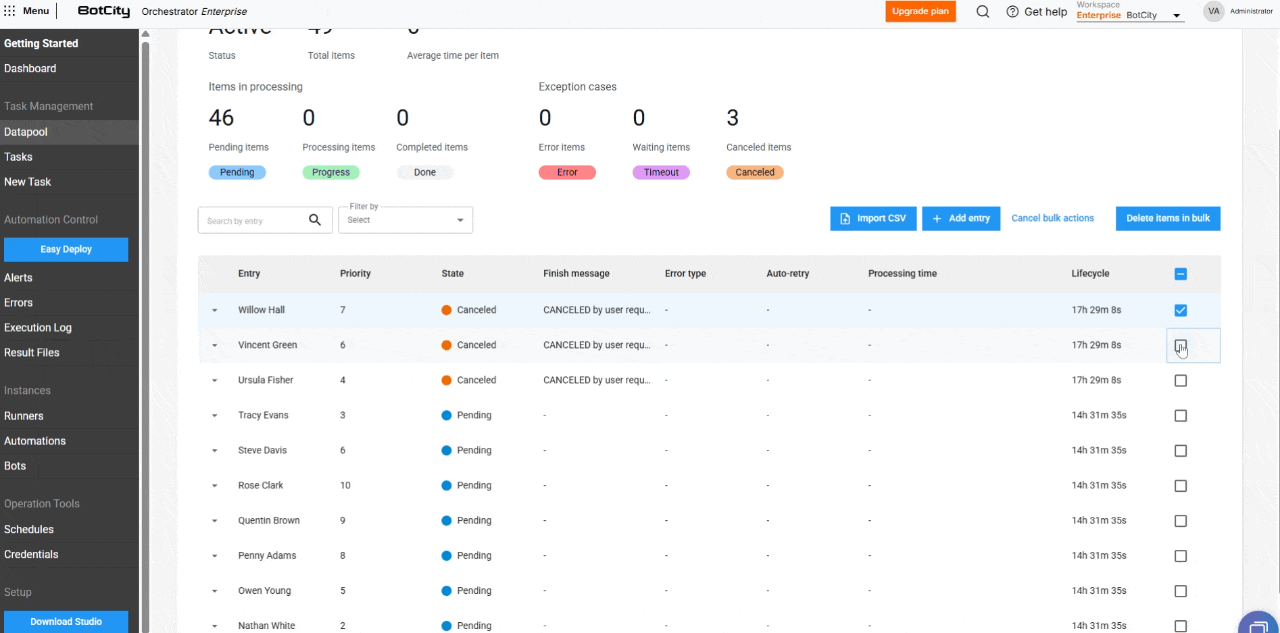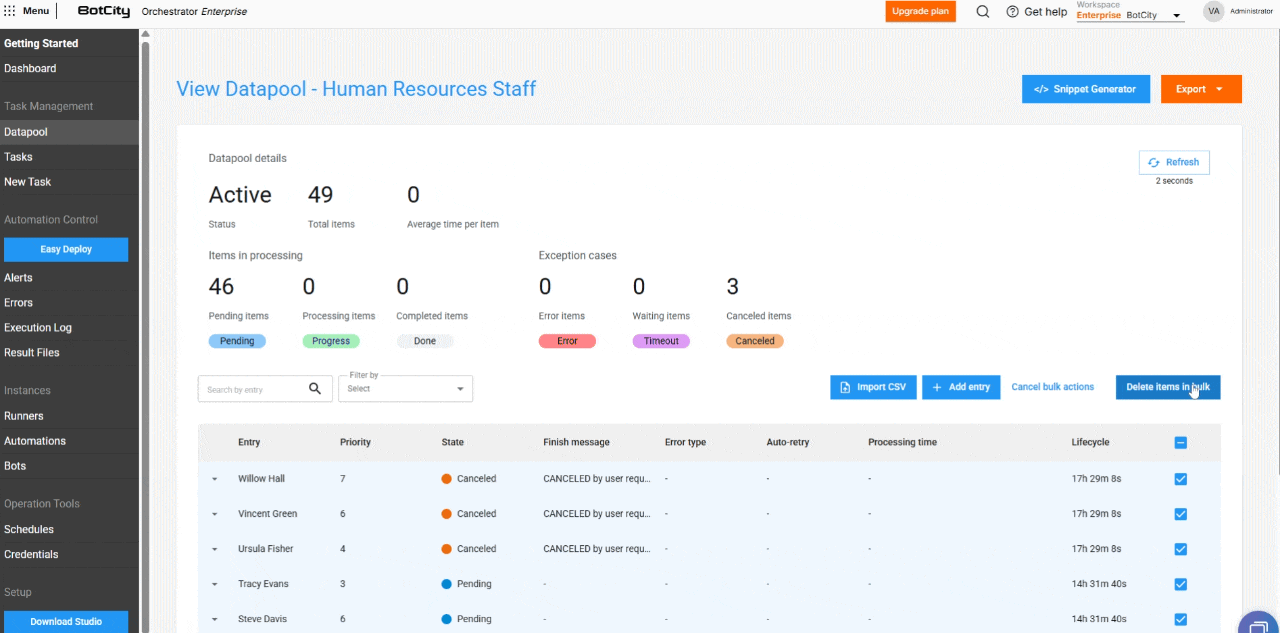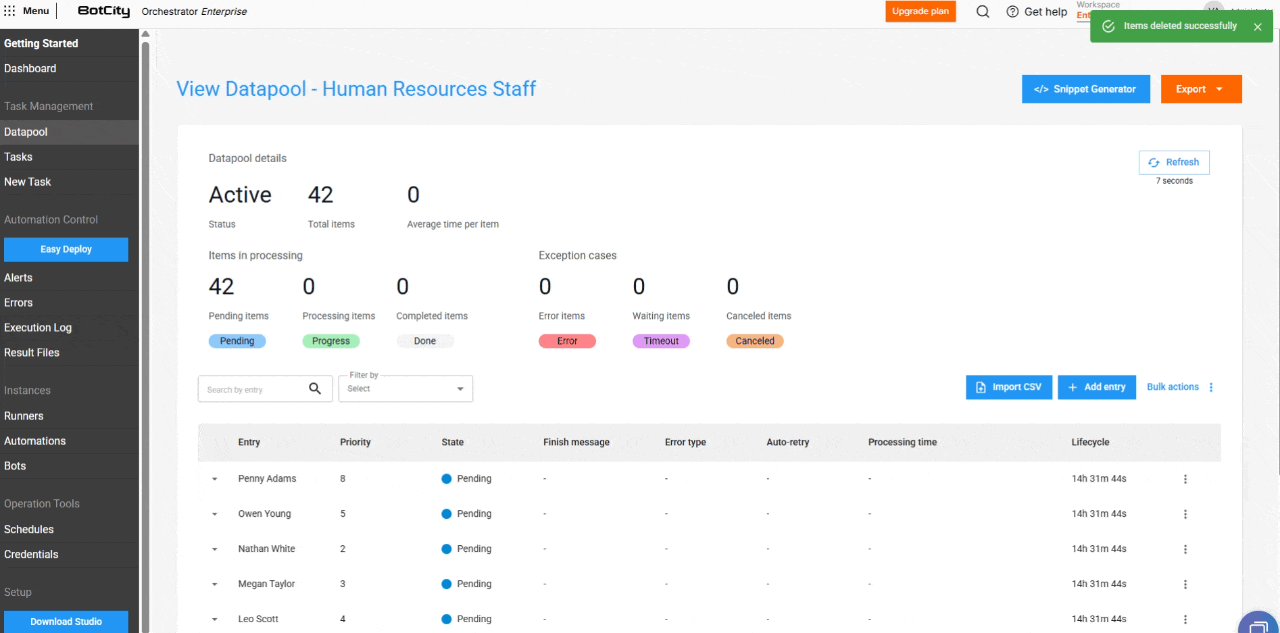
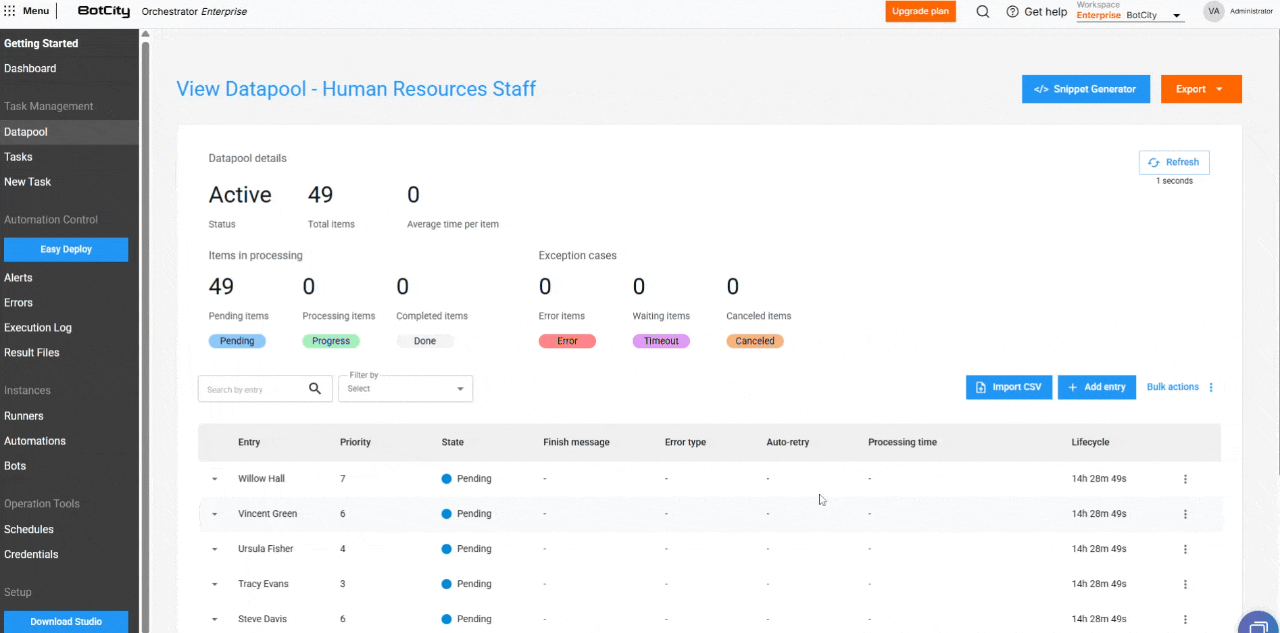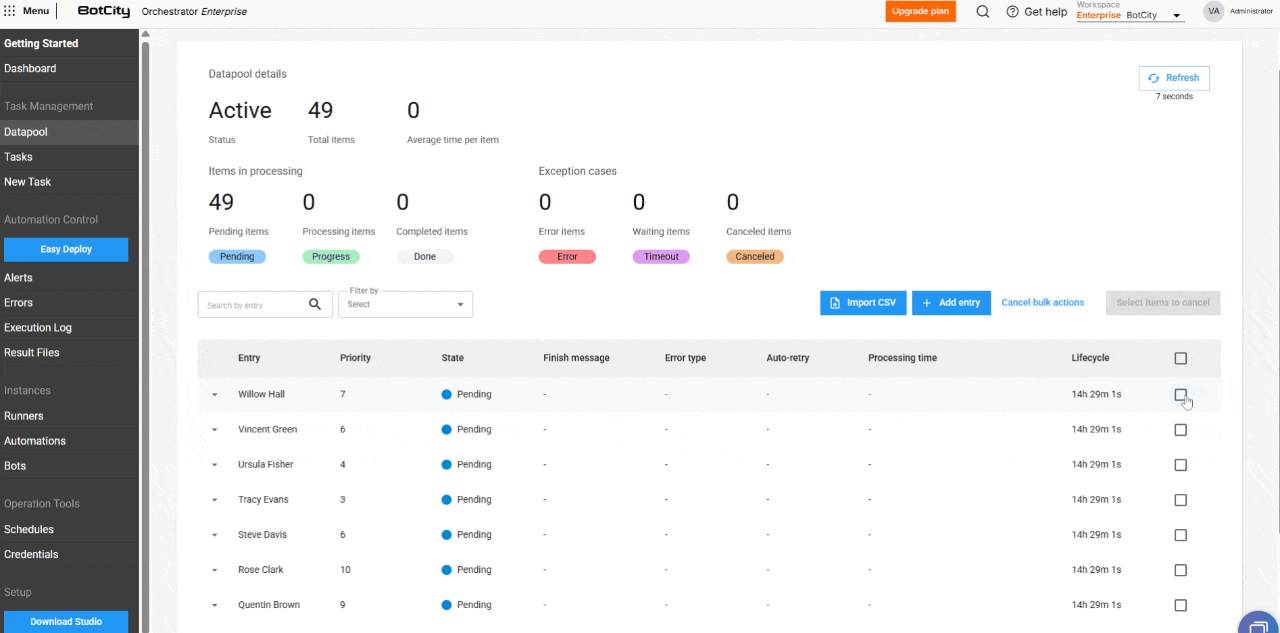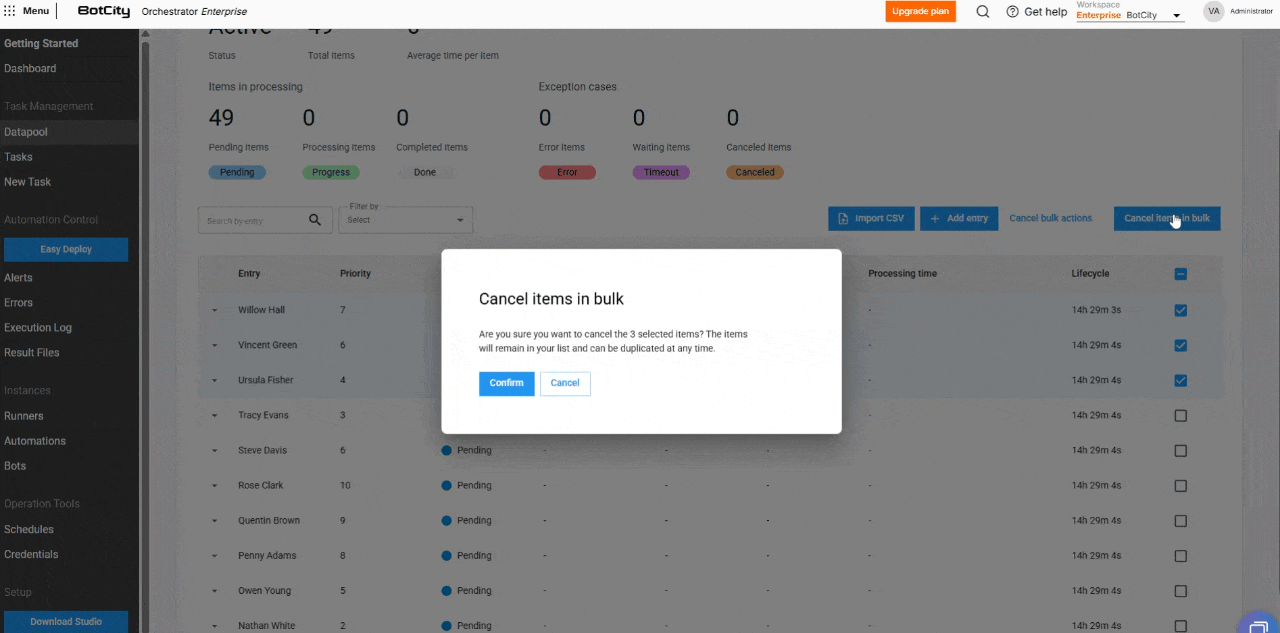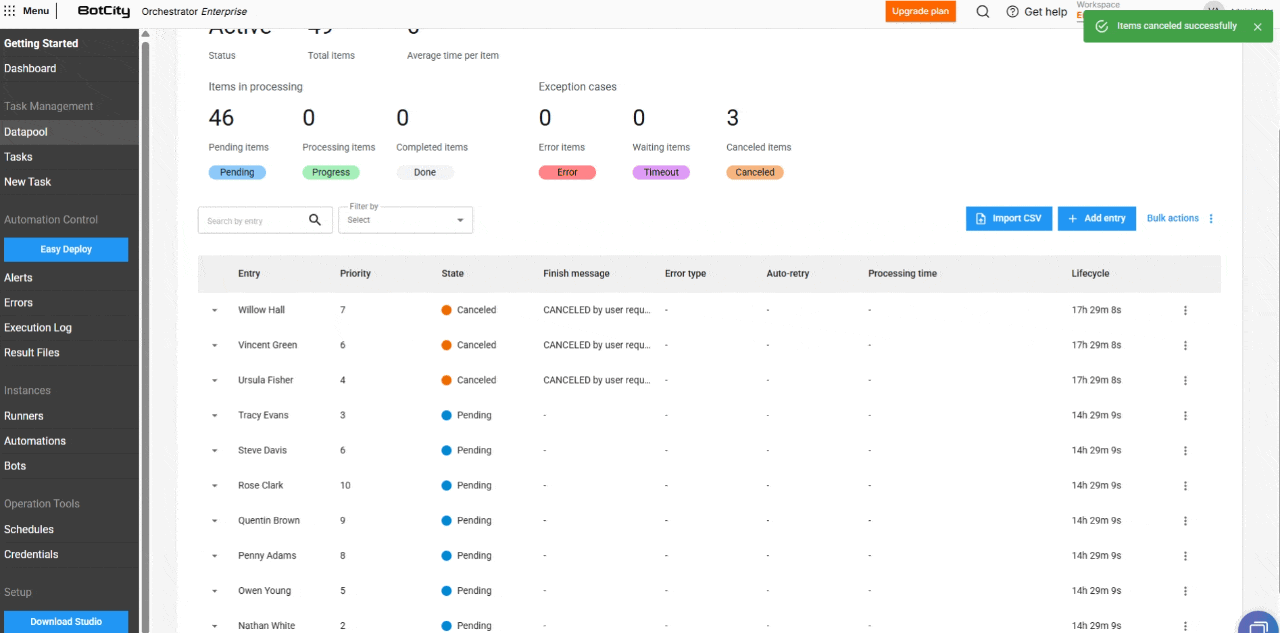
- Cancelación de elementos en masa: los elementos con estado
Pendientepueden cancelarse en masa, permitiendo que el usuario detenga el procesamiento de grandes volúmenes de datos.
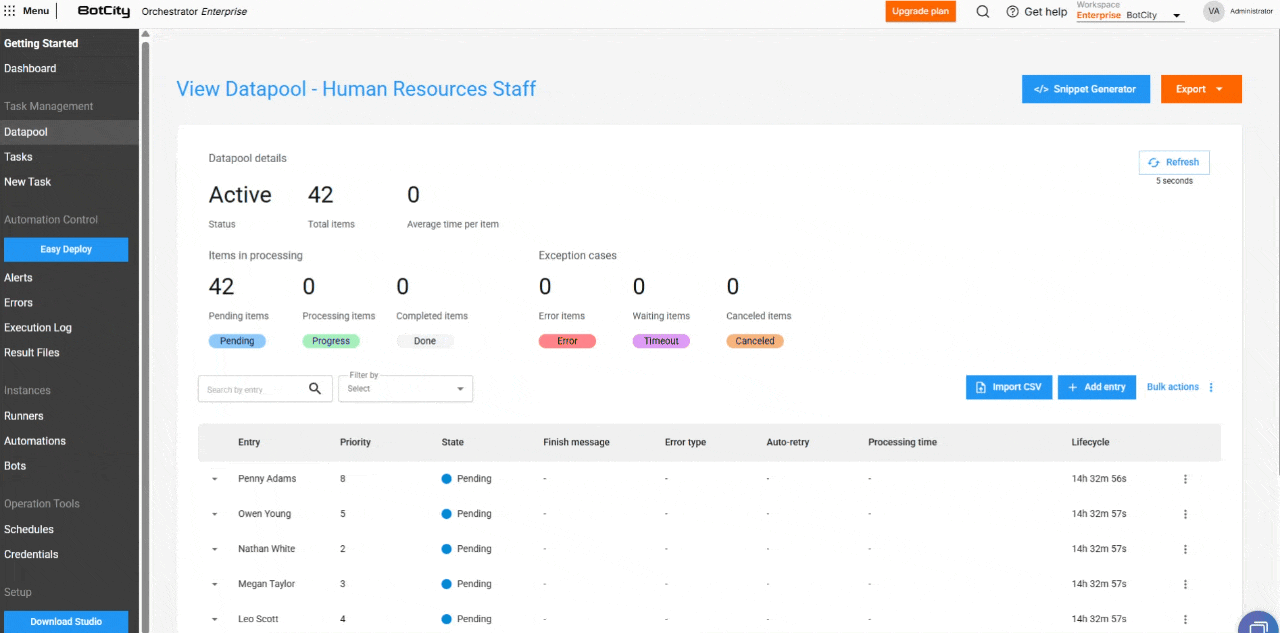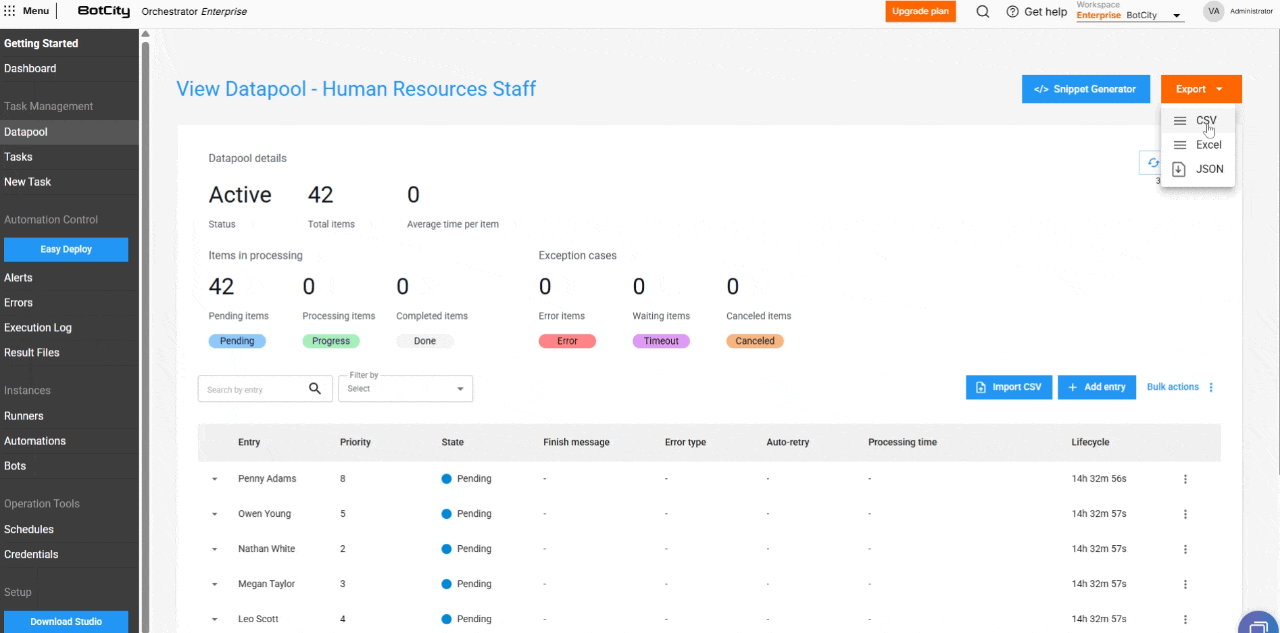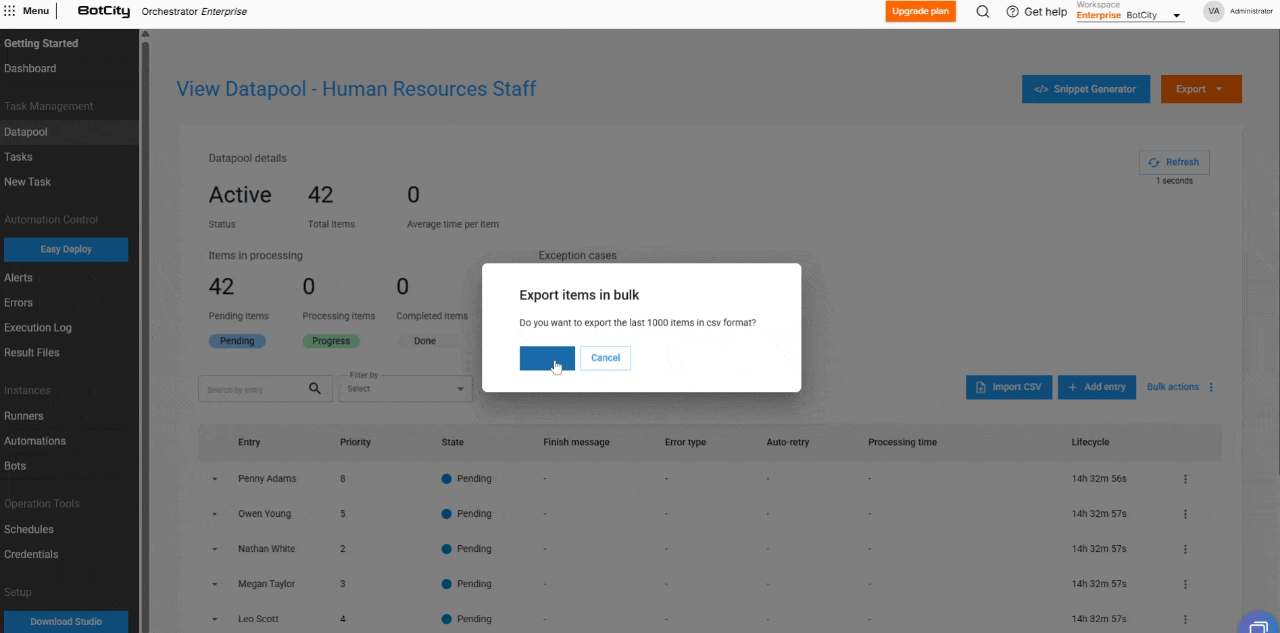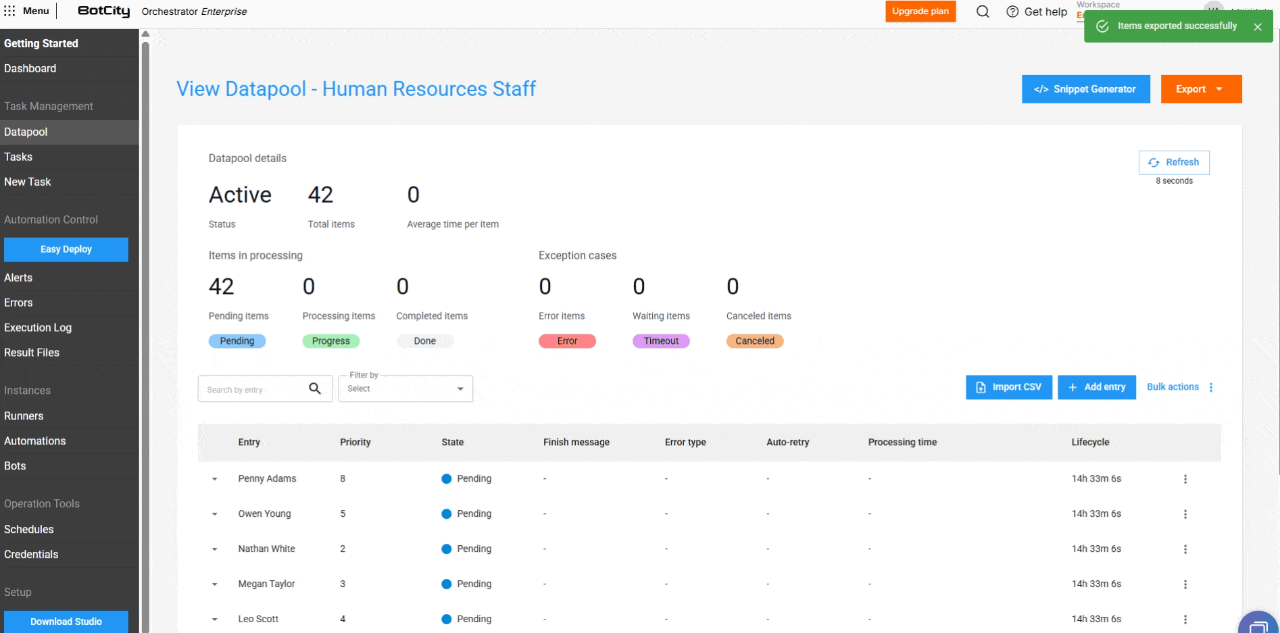
- Exportación de elementos: El usuario puede exportar los últimos 1,000 elementos más recientes en los formatos
CSV,XLSXoJSON.
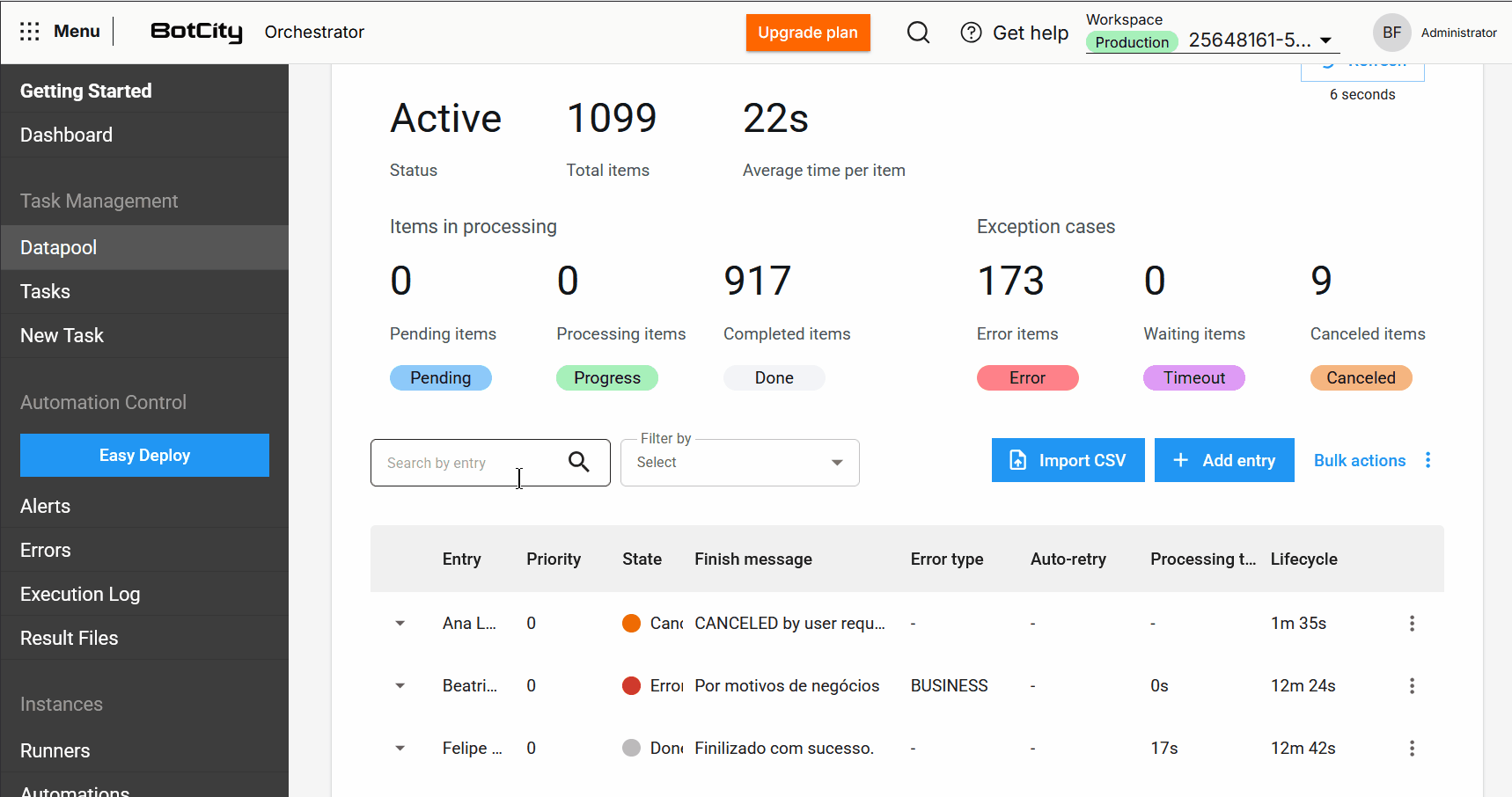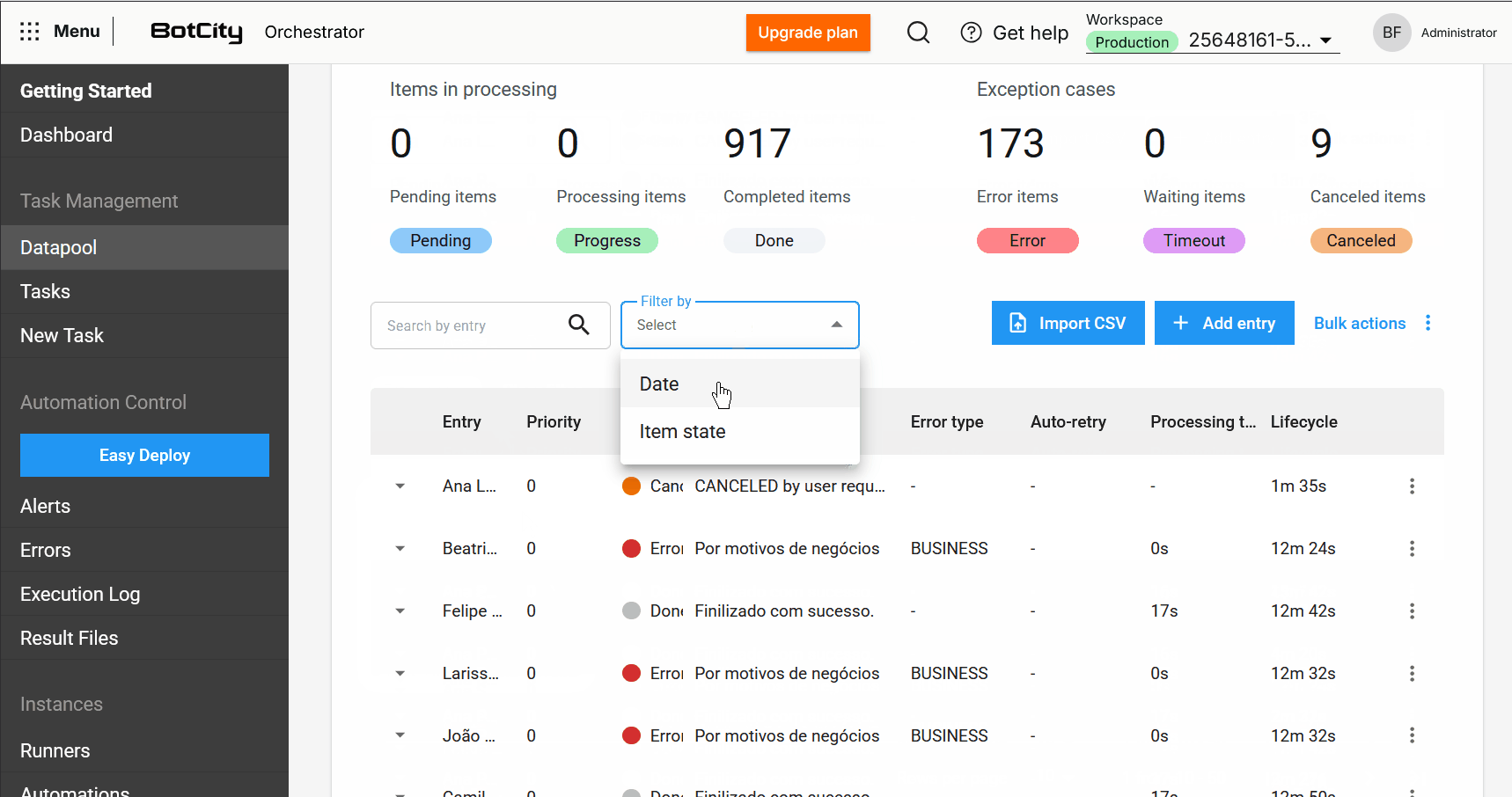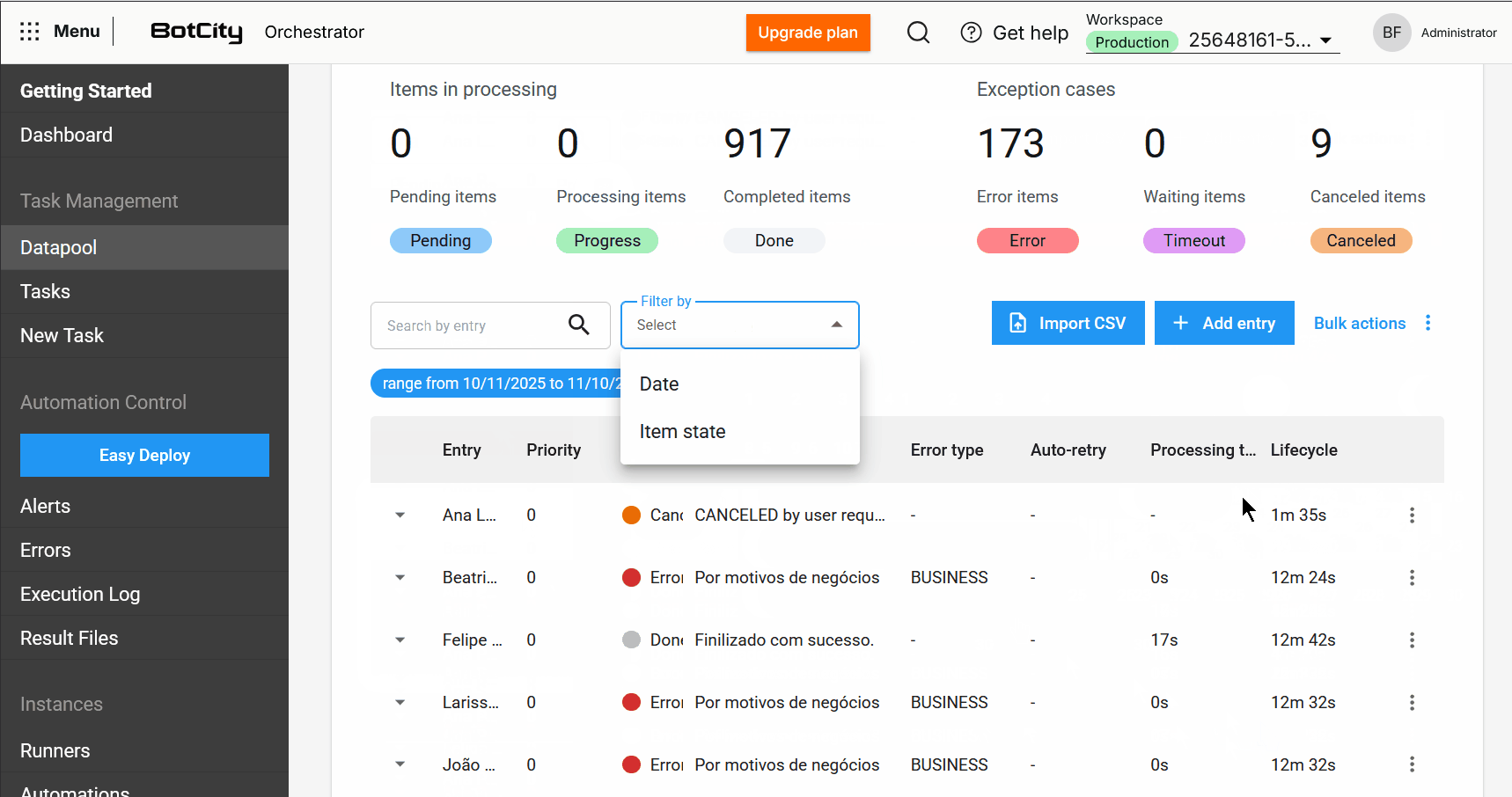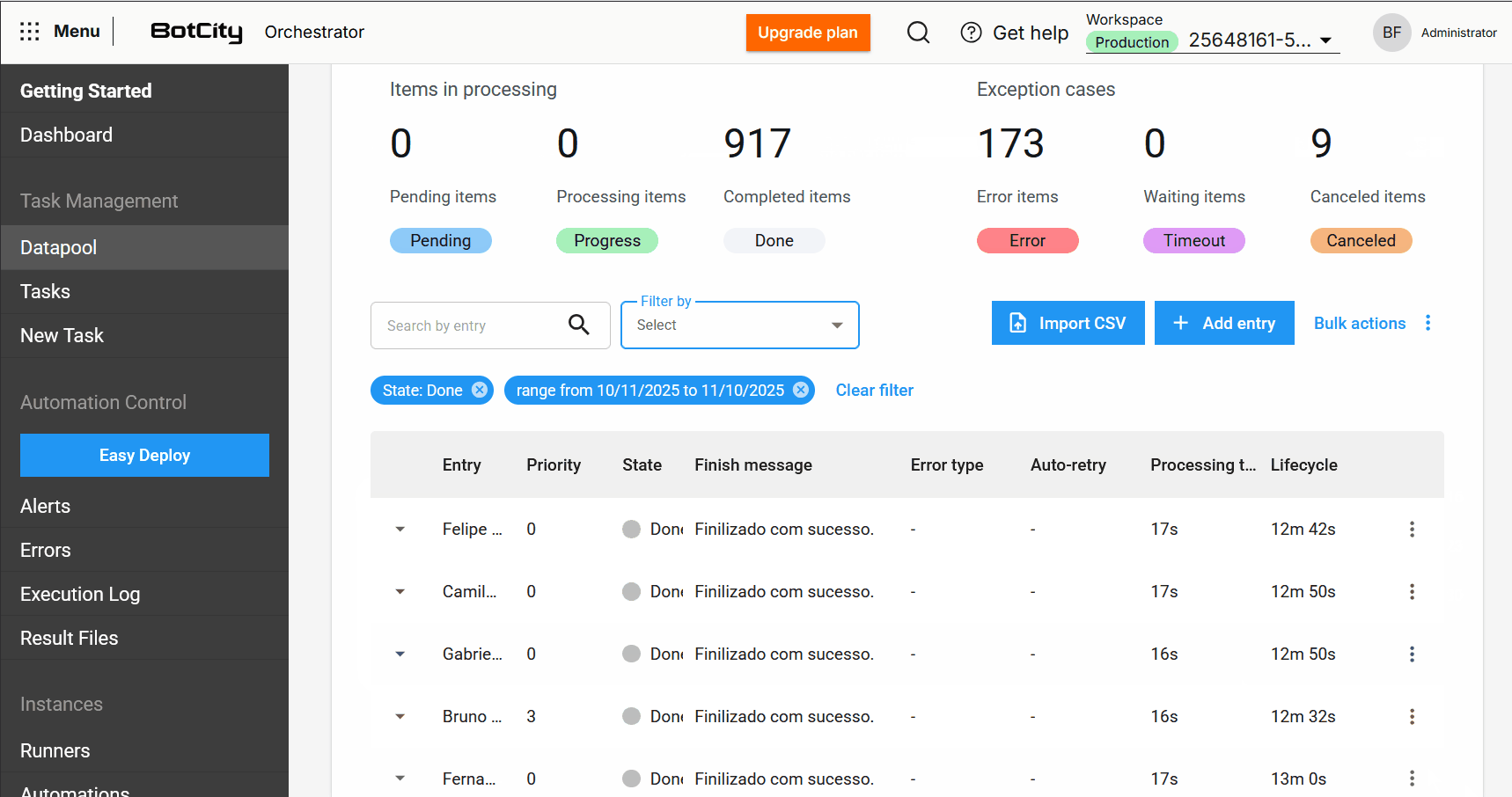
- Búsqueda y filtros mejorados: Ahora es posible buscar elementos por la columna de entrada y filtrar por un período específico o rango de días, facilitando la localización de elementos.
El Datapool 2.0 representa un avance significativo en la forma en que los usuarios pueden gestionar y procesar datos en lote. Estas mejoras se han implementado para proporcionar más control, transparencia y eficiencia.
Si tiene alguna duda sobre la transición a esta nueva versión o necesita asistencia para aprovechar al máximo las nuevas características, puede consultar nuestra documentación oficial y contar con nuestro equipo de soporte.