Setembro¶
Datapool¶
Estamos felizes em anunciar as novidades, do projeto que chamamos internamente de Datapool 2.0. Após meses de pesquisa aprofundada com os usuários e um ciclo de desenvolvimento e implementação dedicado, apresentamos uma série de novos recursos que foram cuidadosamente pensados para ajudar os usuários a processar itens com maior eficiência e obter informações mais detalhadas sobre seus dados.
Criação e Configuração de Datapools¶
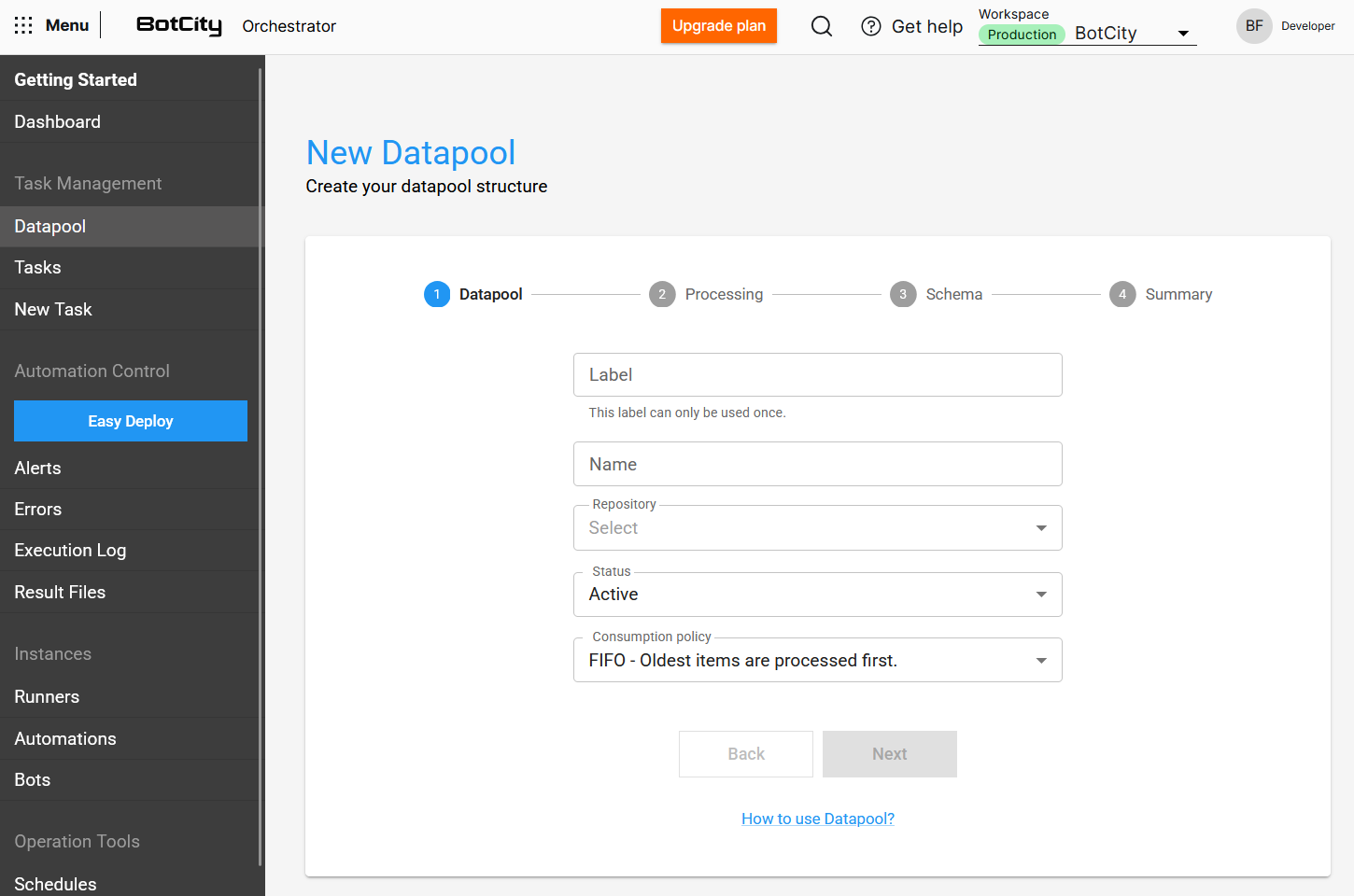
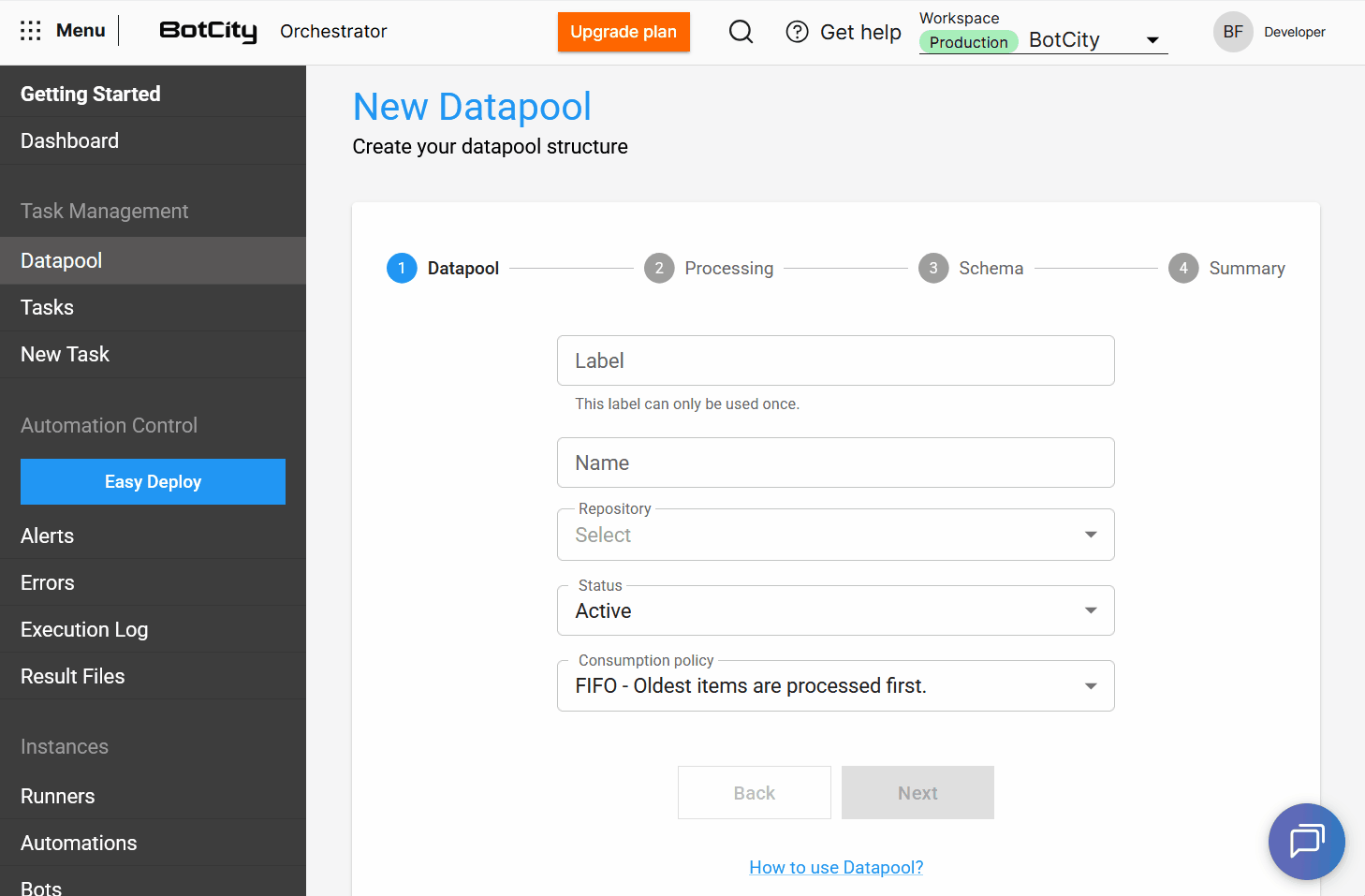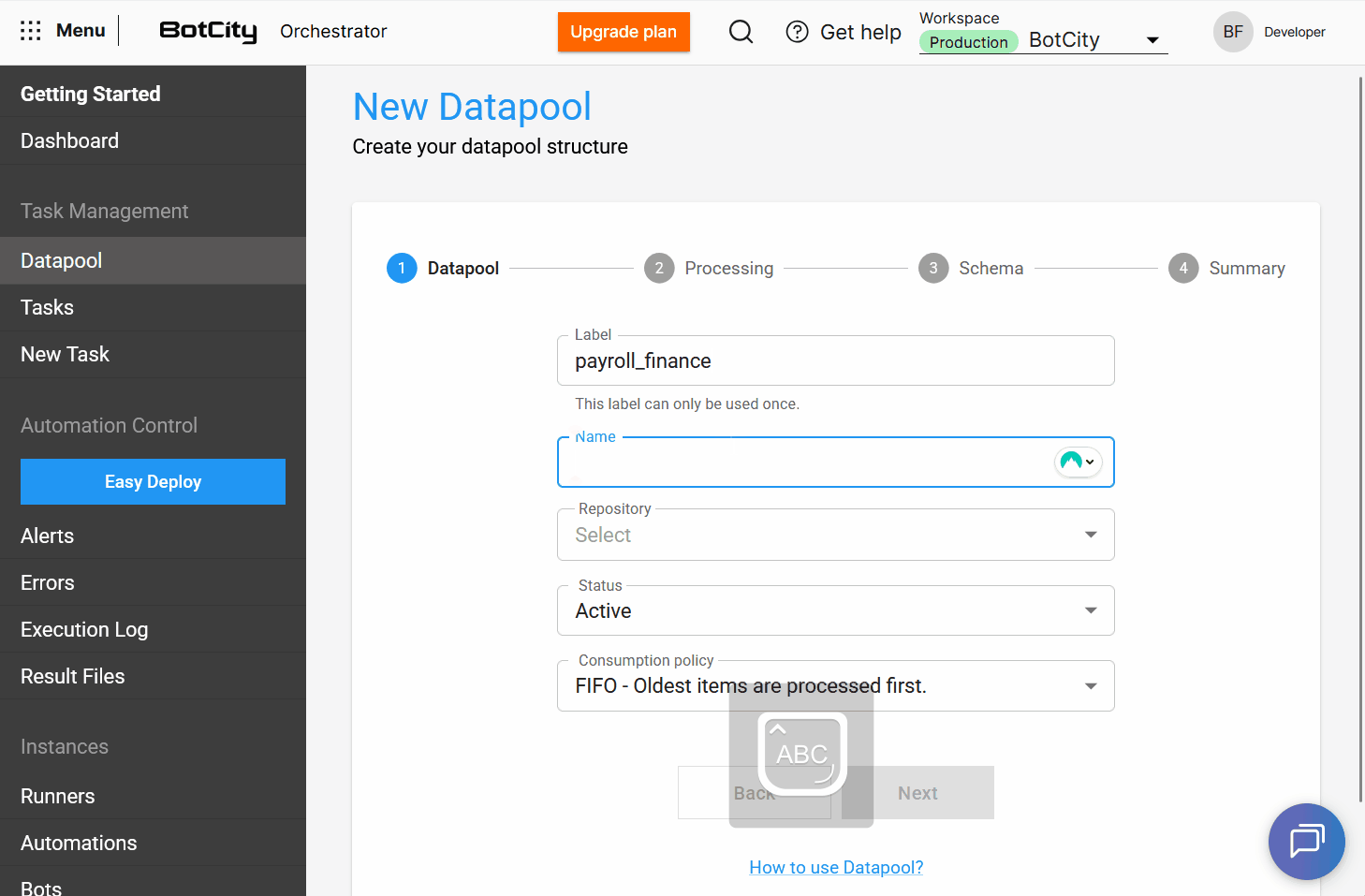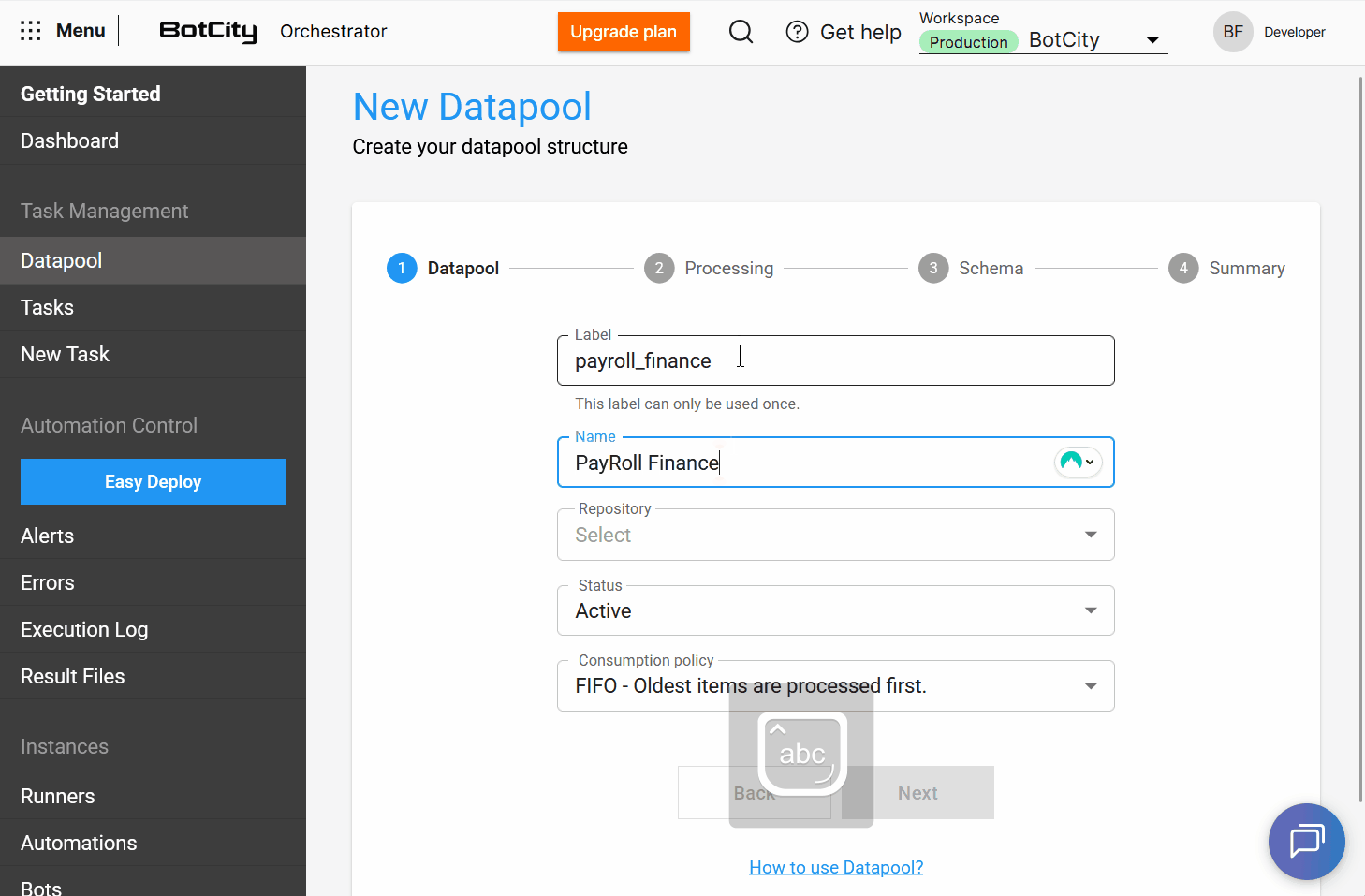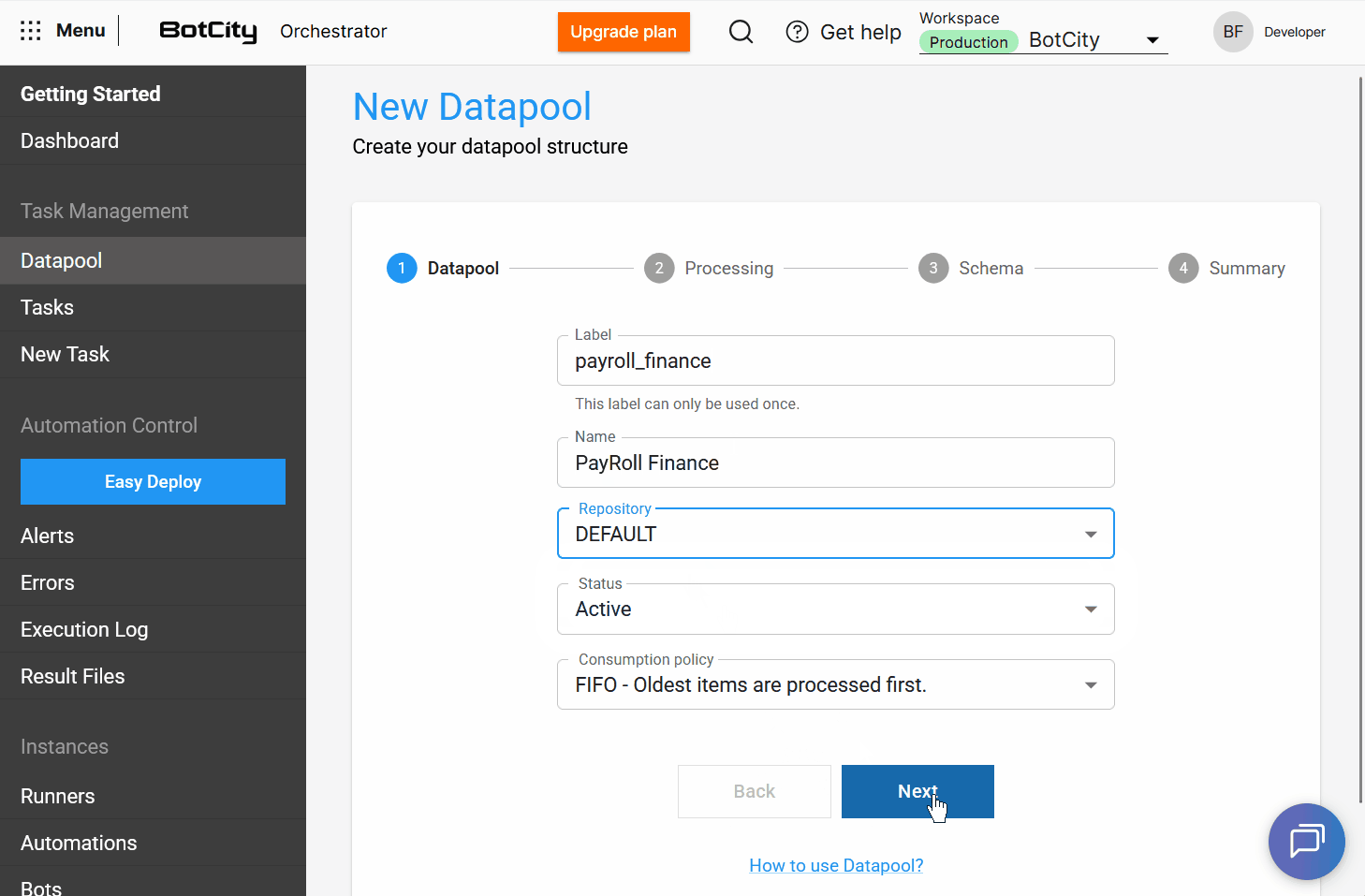
A criação de um novo Datapool agora é um processo intuitivo, guiado por etapas que garantem uma configuração completa e precisa. Além das melhorias de interface, foram adicionados recursos que tornam o Datapool mais robusto e flexível.
Processo de Criação por Etapas¶
A interface de criação foi reestruturada em um fluxo passo a passo para facilitar a configuração:
- Datapool: Configure as informações básicas do Datapool.
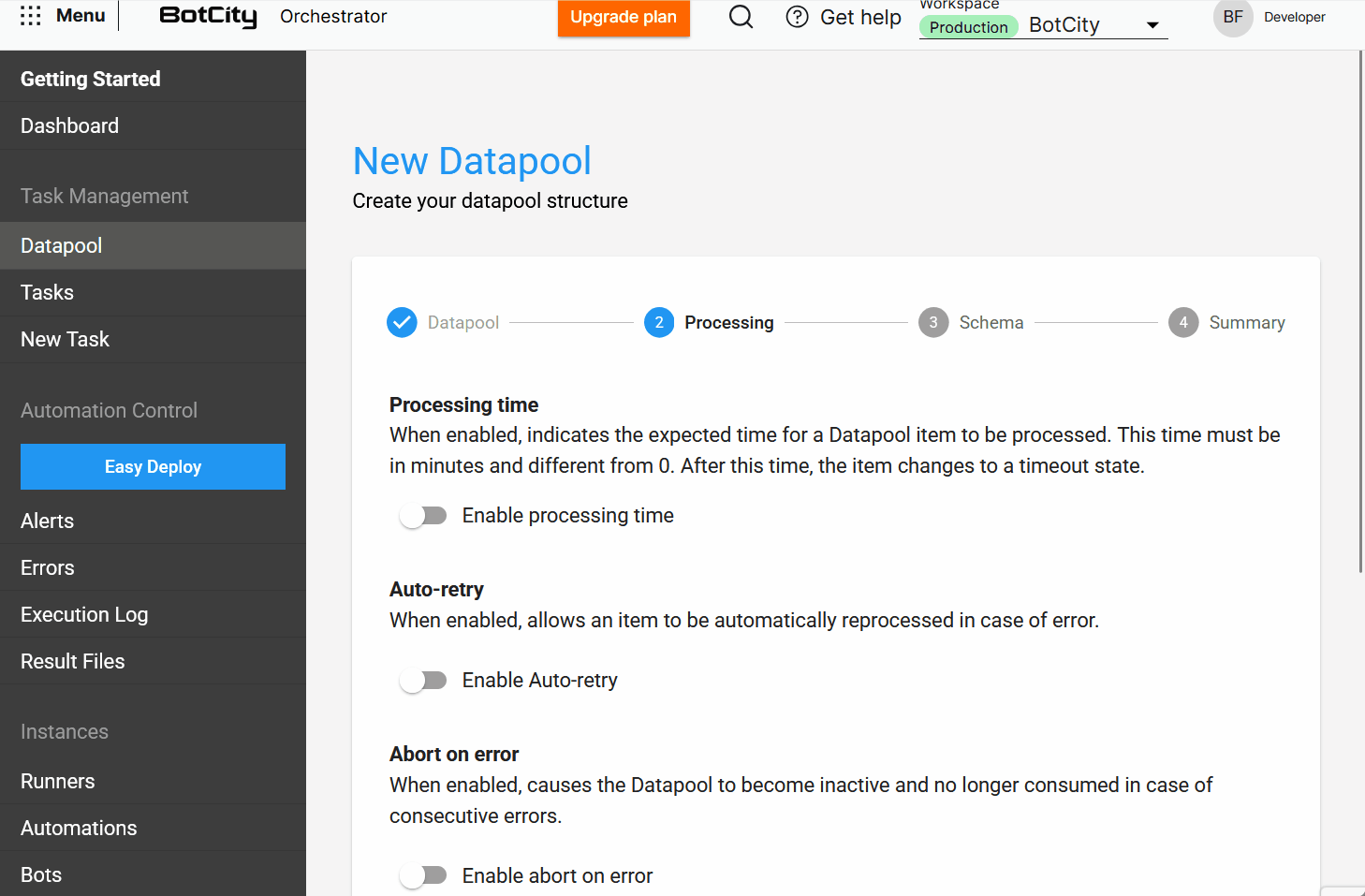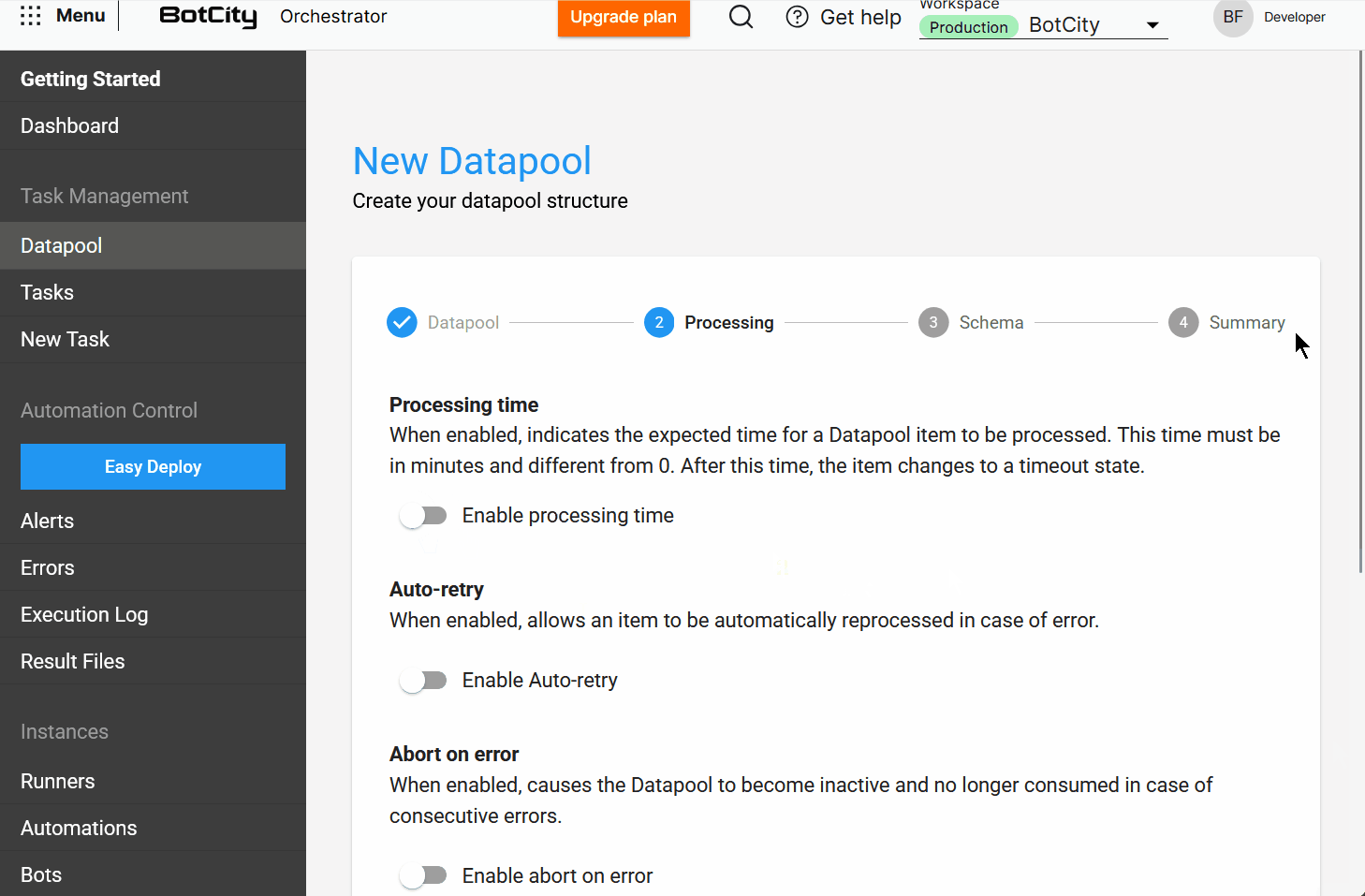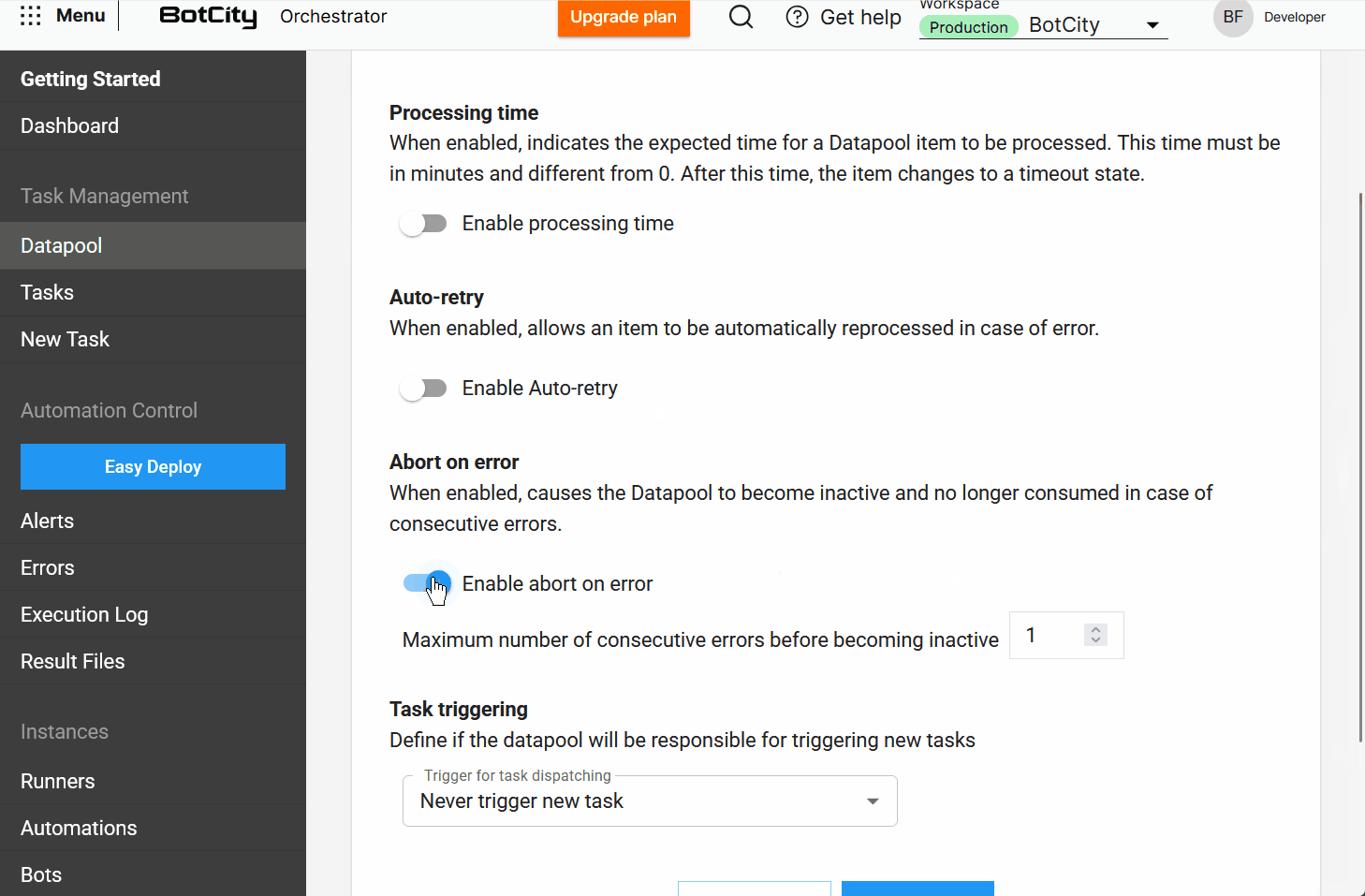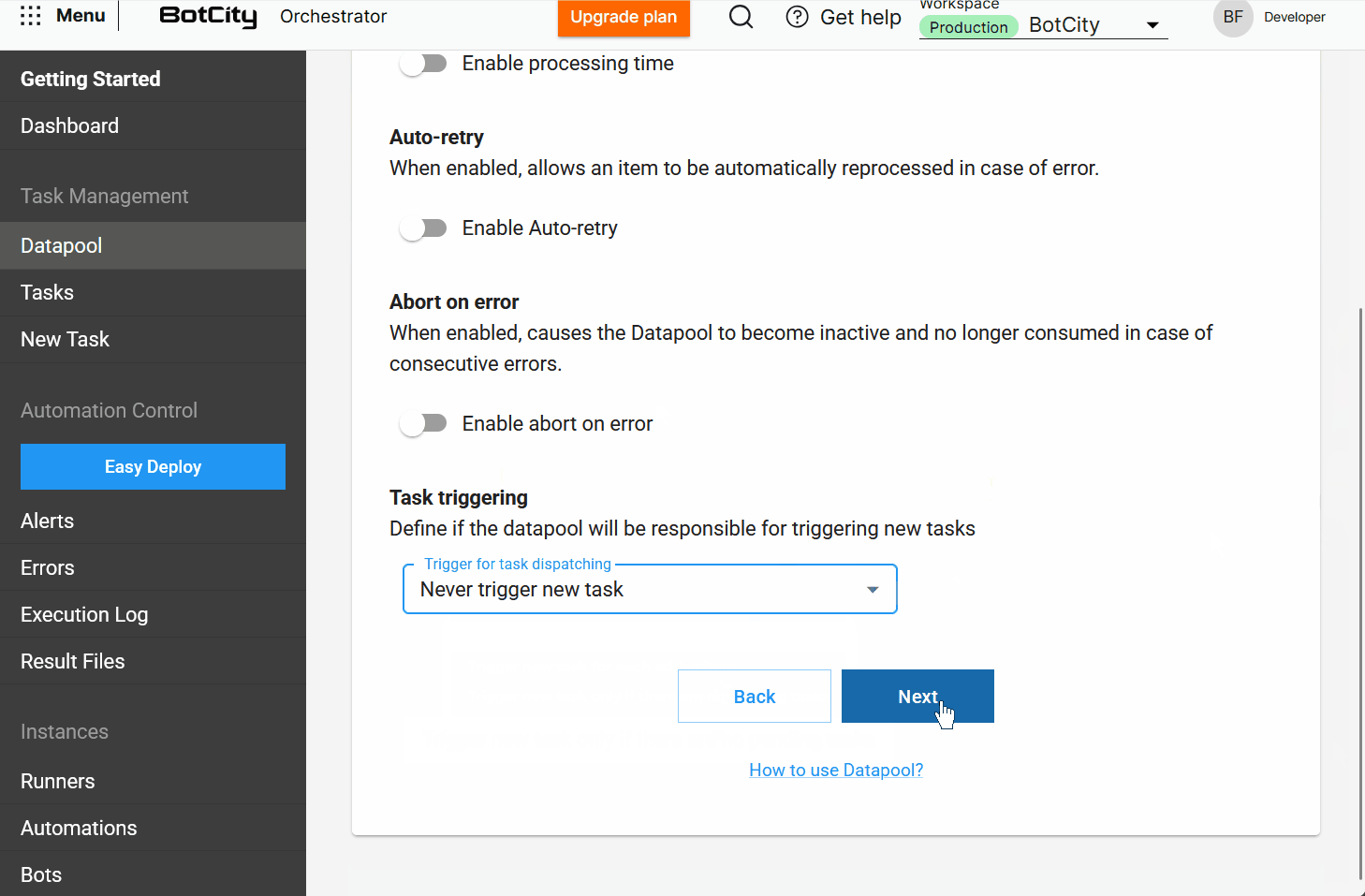
- Processamento: Defina como os itens serão processados. Aqui, o usuário encontra opções como
tempo de processamento,auto-retry,abortar em caso de erroedisparo de tarefas. - Schema: Configure a estrutura de dados para processar os itens.
- Resumo: Revise todas as escolhas feitas antes de finalizar a criação do Datapool.
Recursos de Configuração¶
A partir desta atualização o Datapool permite que os usuários atribuam um label e um nome à sua estrutura.
label: é um identificador único no sistema e não pode ser repetidonome: é uma identificação amigável para a lista principal de Datapools e pode ser repetido caso a estrutura seja recriada.
Textline Explicativo em todos os recursos do Datapool, com uma linha de texto explicativa que descreve a funcionalidade e o propósito de cada opção, auxiliando o usuário na configuração.
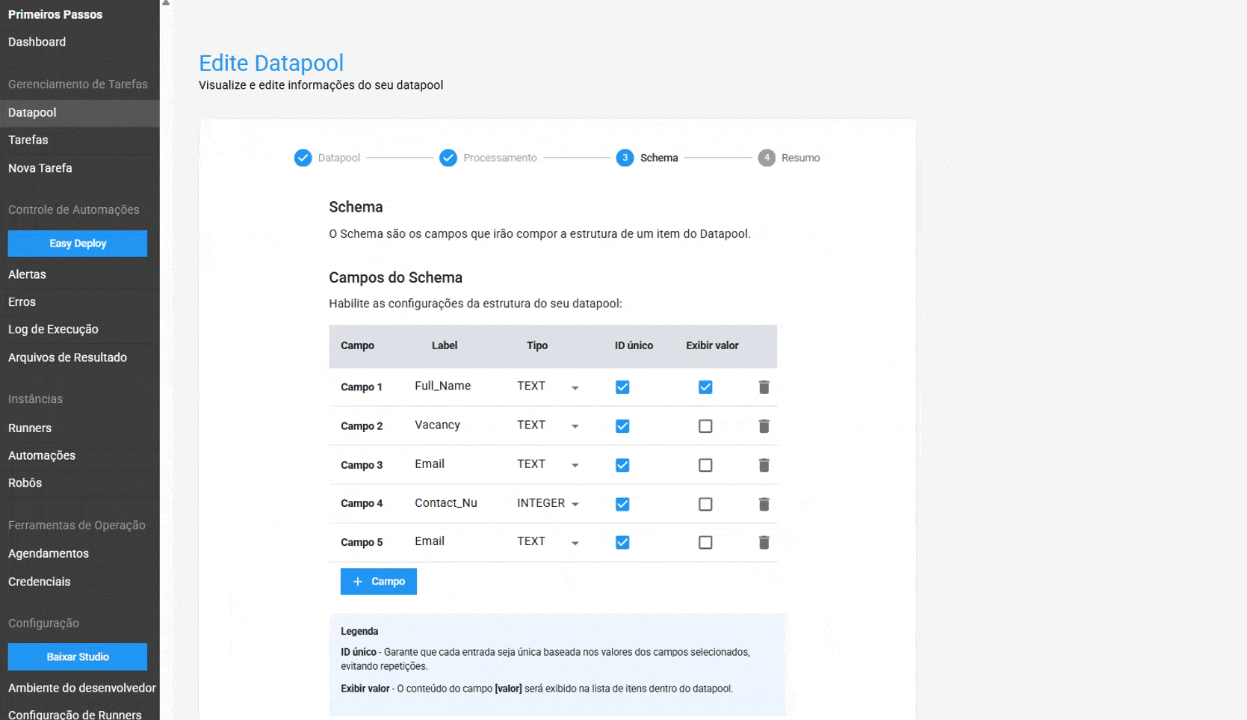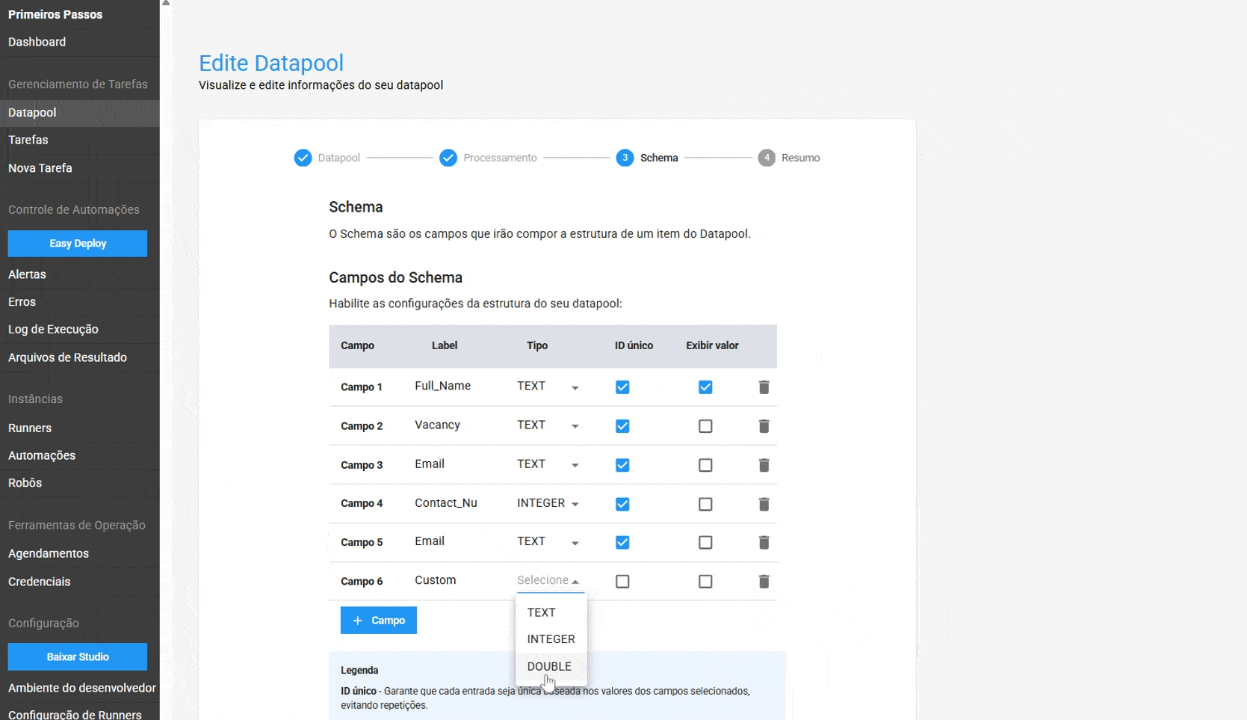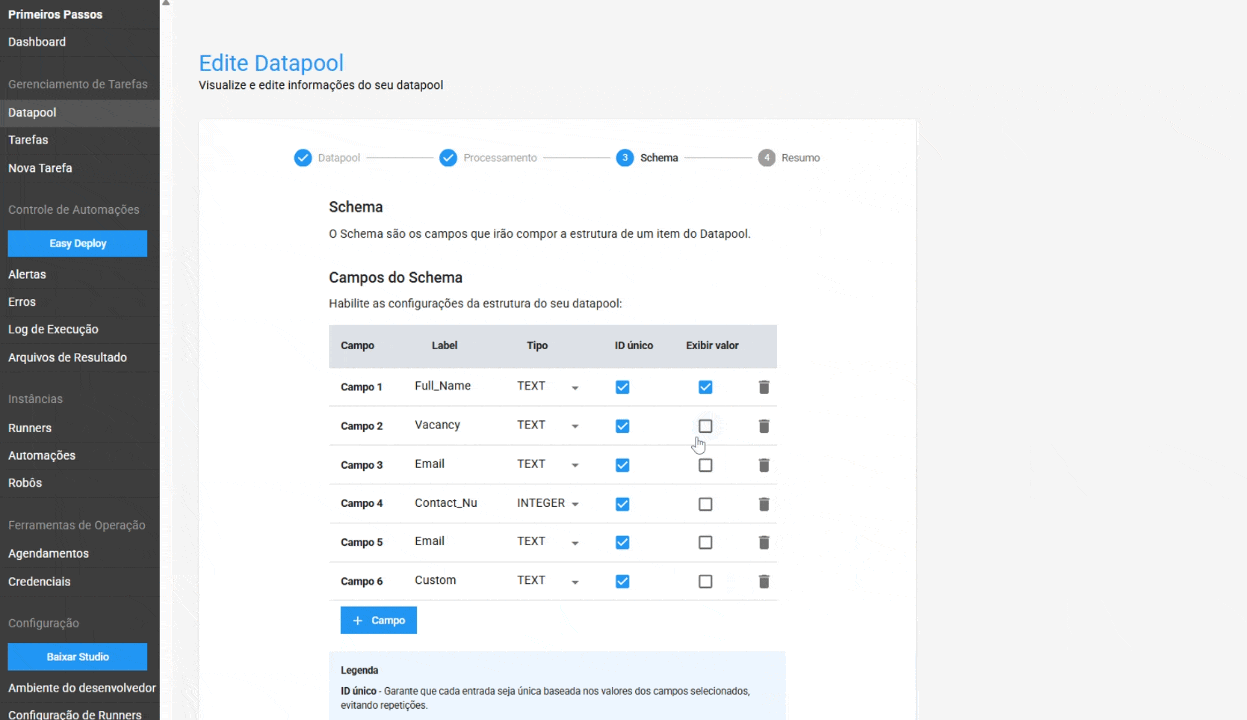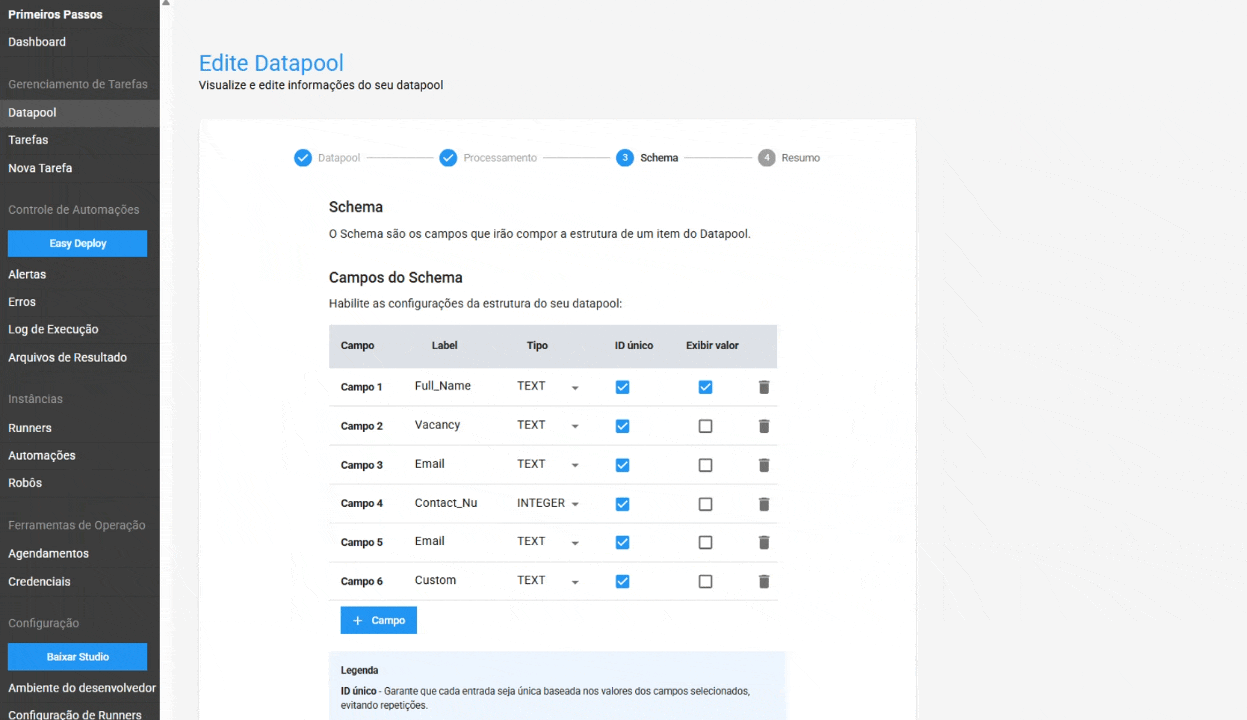
No Schema, foram adicionadas as configurações para:
- ID Único no Schema: ao ativar essa opção, o Datapool garante que cada entrada seja única, baseada nos valores dos campos selecionados. Isso ajuda a evitar a duplicação de dados e garante a integridade da informação. Este recurso é opcional.
- Exibição de valor na tabela de itens: permite ao usuário exibir o conteúdo de um campo específico diretamente na tabela de itens do Datapool, facilitando a localização e o gerenciamento de um item. Este é um recurso opcional.
Gerenciamento e Manipulação de Itens¶
As melhorias de gestão e manipulação de itens foram atualizadas para dar aos usuários mais controle e visibilidade sobre o processamento de seus dados.
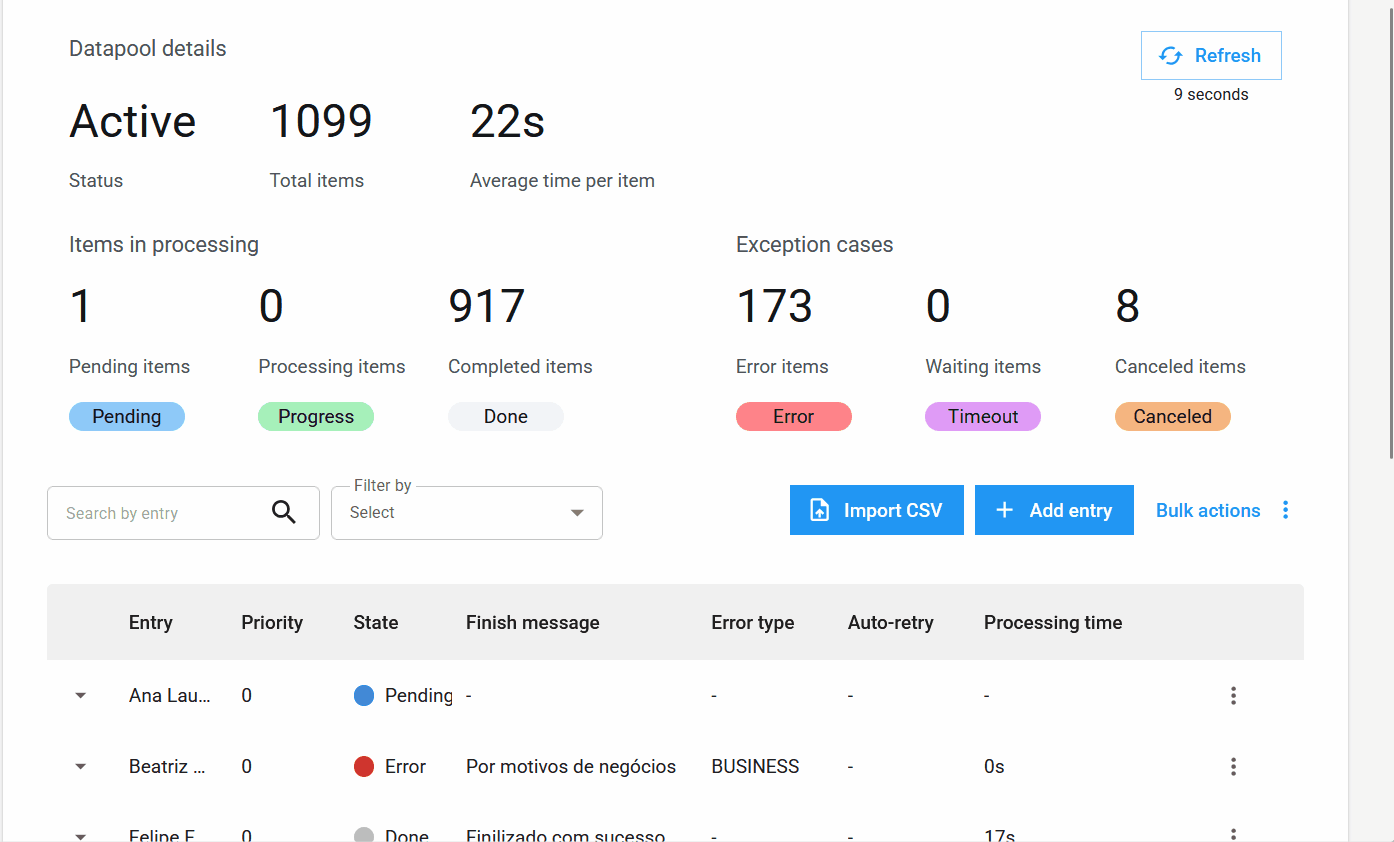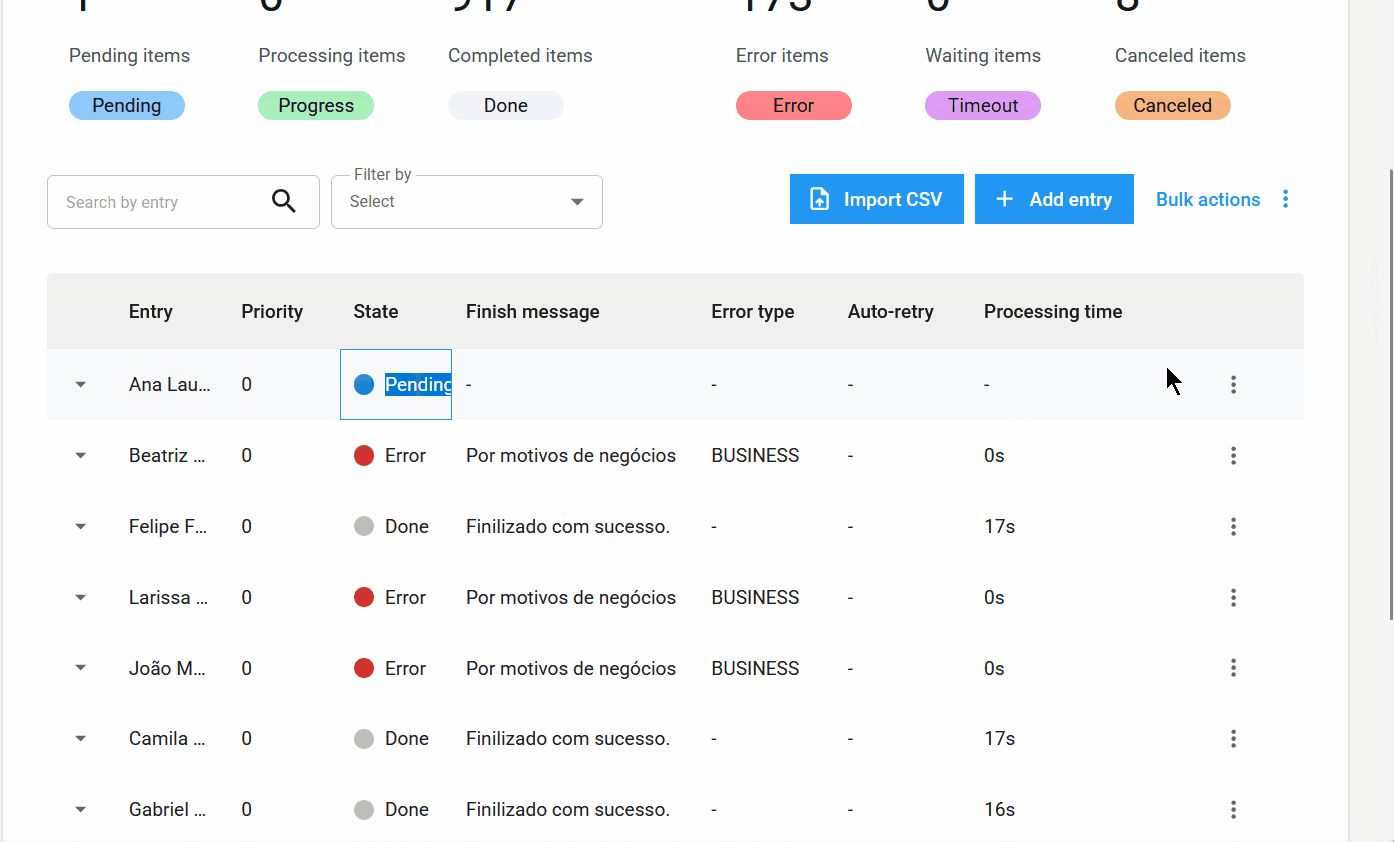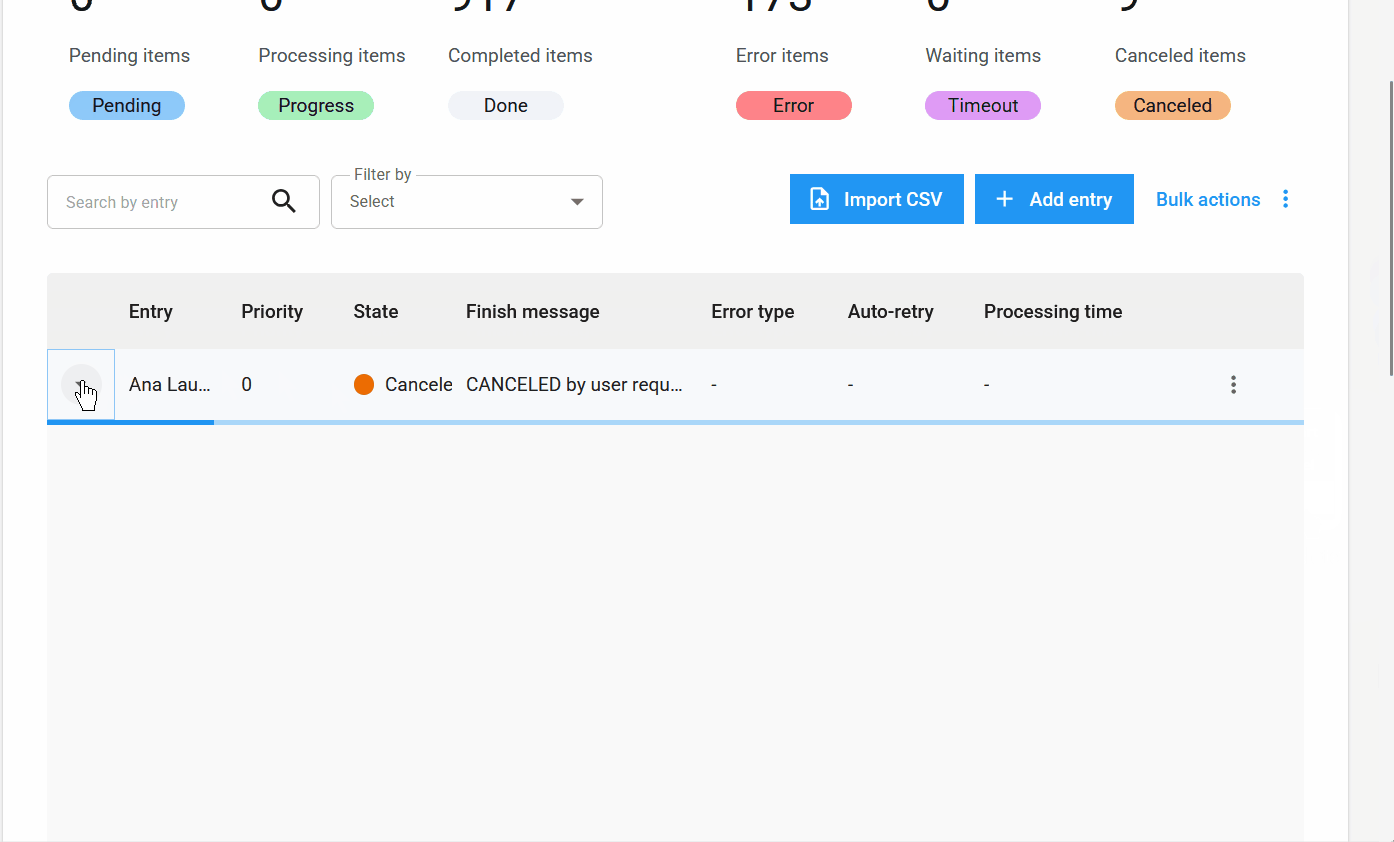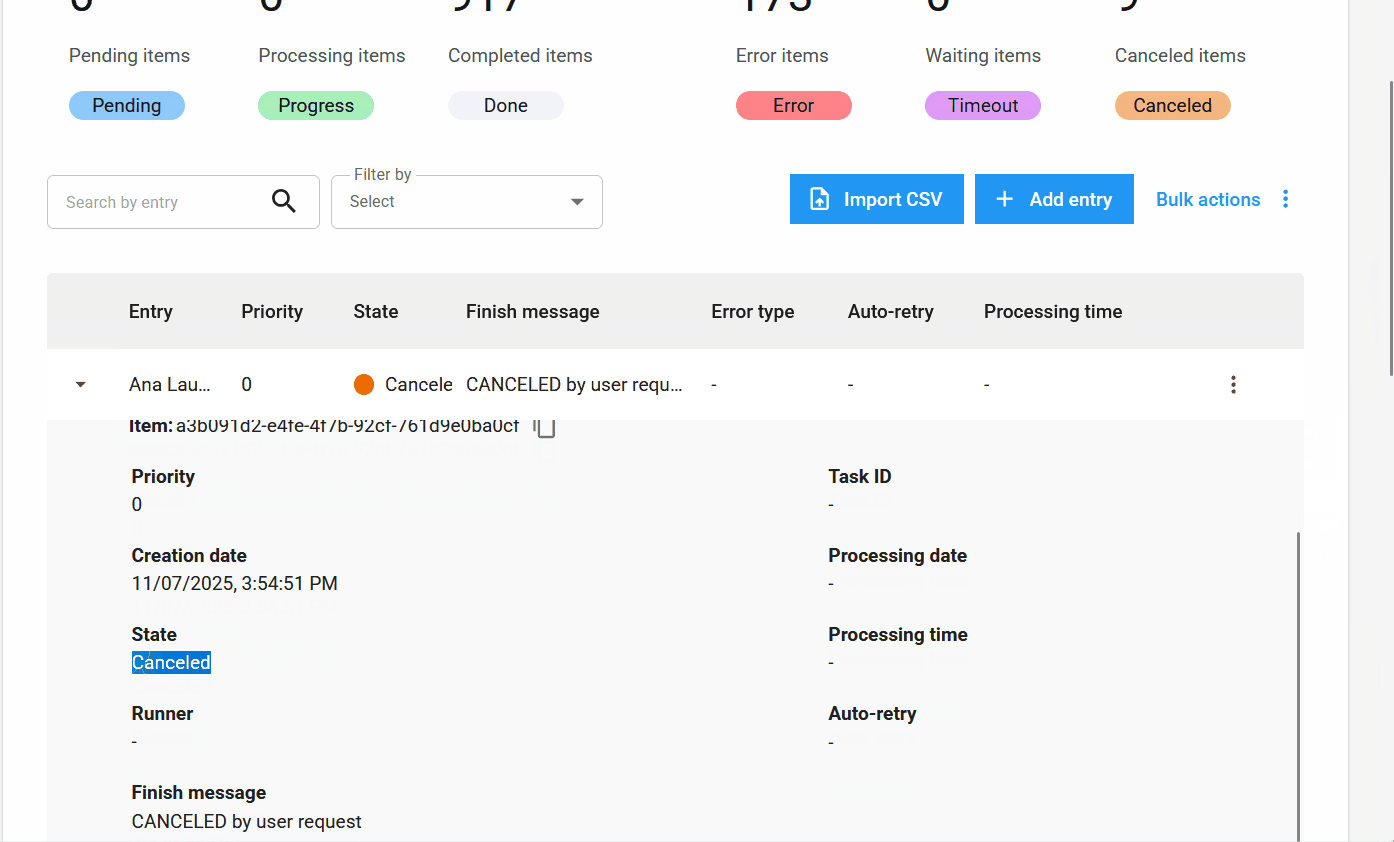
Novas colunas na Tabela de Processamento¶
A tabela de itens foi expandida para incluir colunas essenciais para o monitoramento:
- Entrada: Reflete o identificador do item, que pode ser único, um valor de campo ou um hash.
- Prioridade: A prioridade definida para o processamento.
- Estado: O estado atualizado do item.
- Mensagem de Finalização: Mensagens de conclusão, erro ou cancelamento que oferecem insights sobre o resultado do processamento.
- Tipo de Erro: Indica se o erro foi de negócio ou de sistema.
- Auto-retry: Mostra se o item é um auto-retry e qual é a sua contagem atual.
- Tempo de Processamento: O tempo gasto no processamento de um item.
- Ciclo de Vida: O tempo total desde a criação do item até a finalização.
Novos Estados e informações de itens¶
Novo estado de item: Cancelado.
Além dos estados Pendente, Processando, Concluído, Erro e Timeout, o novo estado Cancelado é adicionado. Ele é aplicado quando o usuário cancela um item antes que ele seja processado.
Ações em massa e melhorias de usabilidade¶
- Deleção de Itens em Massa: Os usuários podem deletar itens nos estados
Pendentes,Concluídos,Erro,TimeouteCanceladospor meio do botão de ações em massa. Fique atento: a deleção de um item é irreversível.
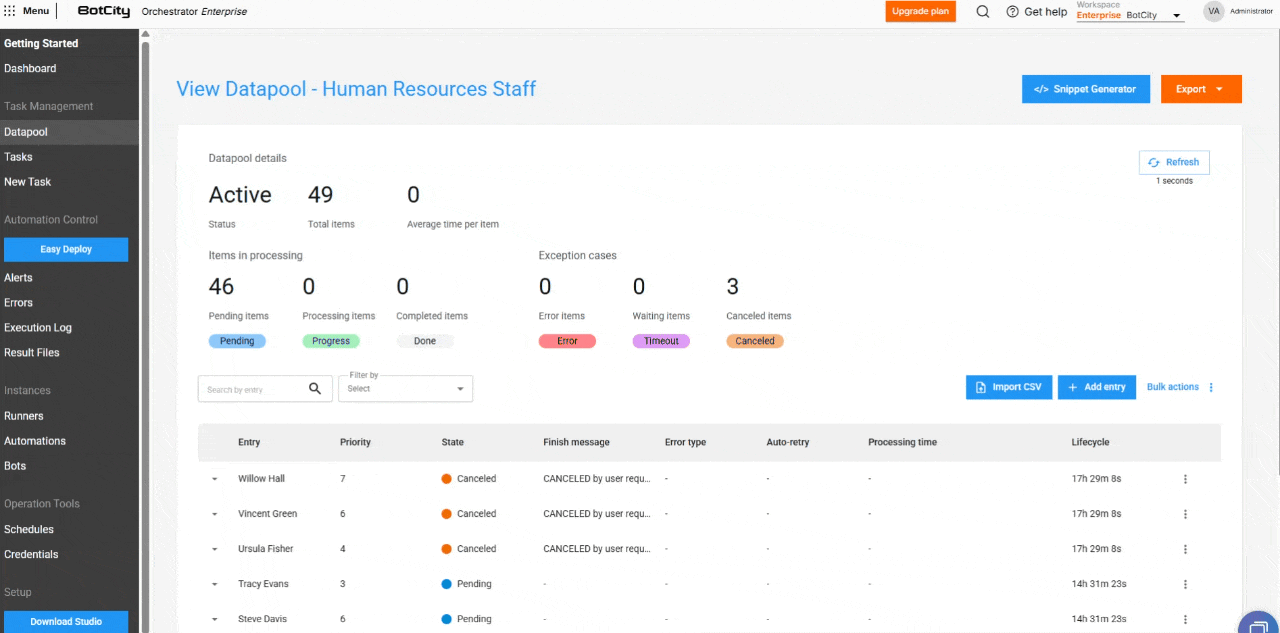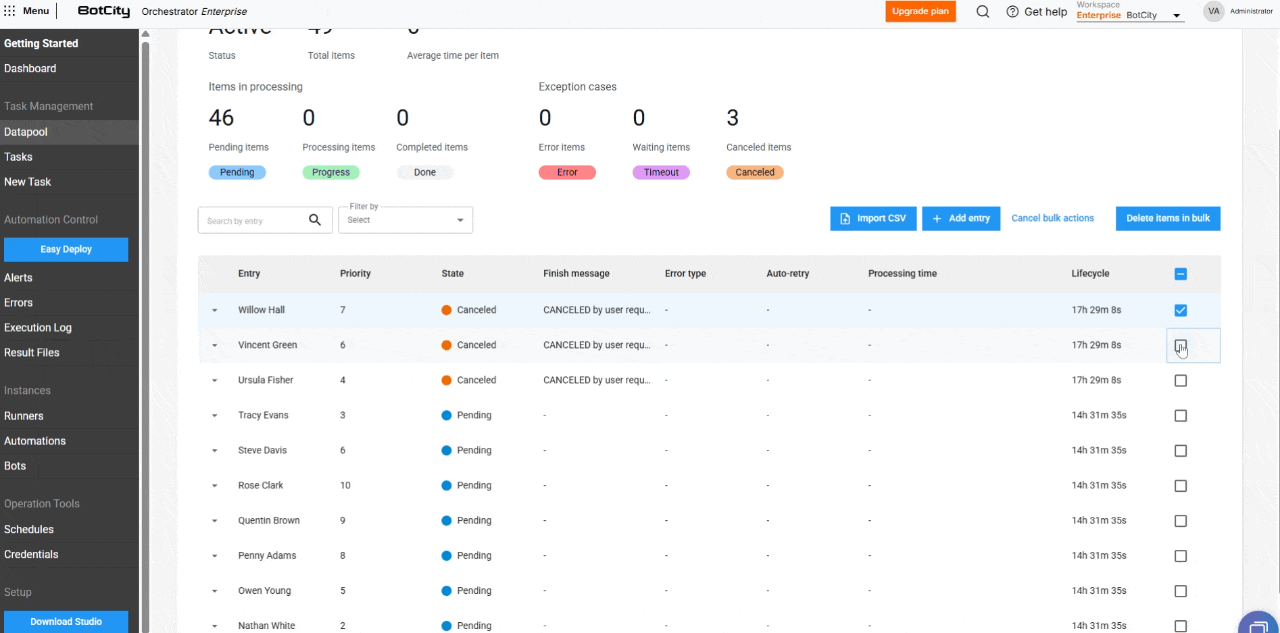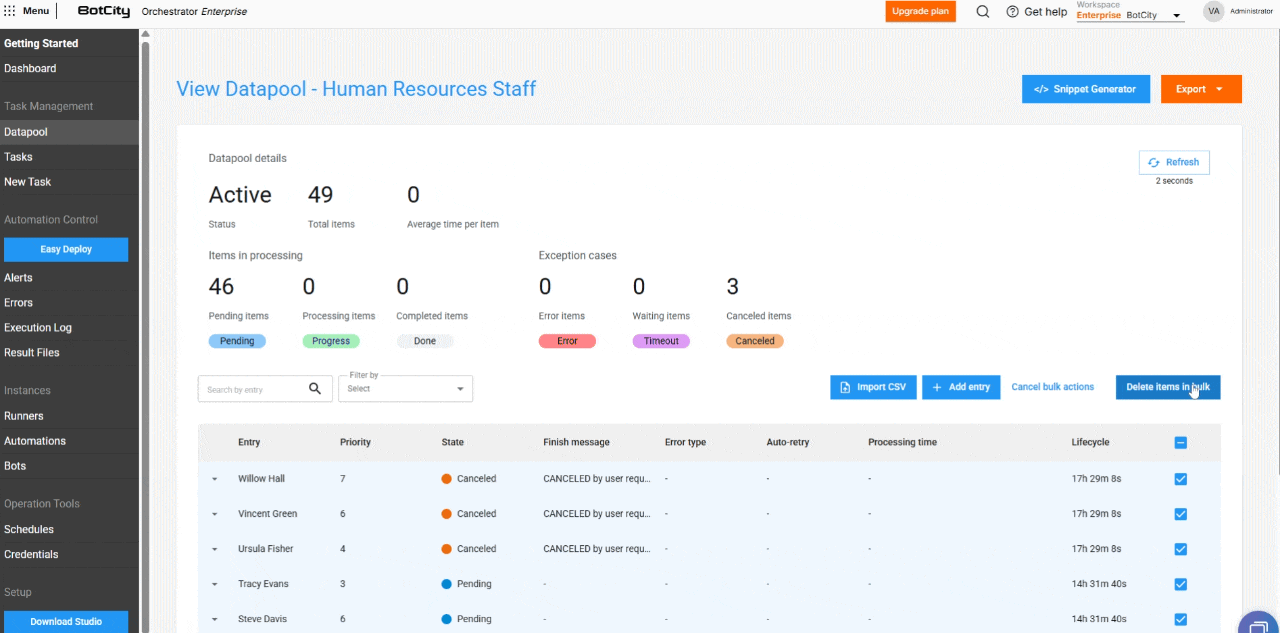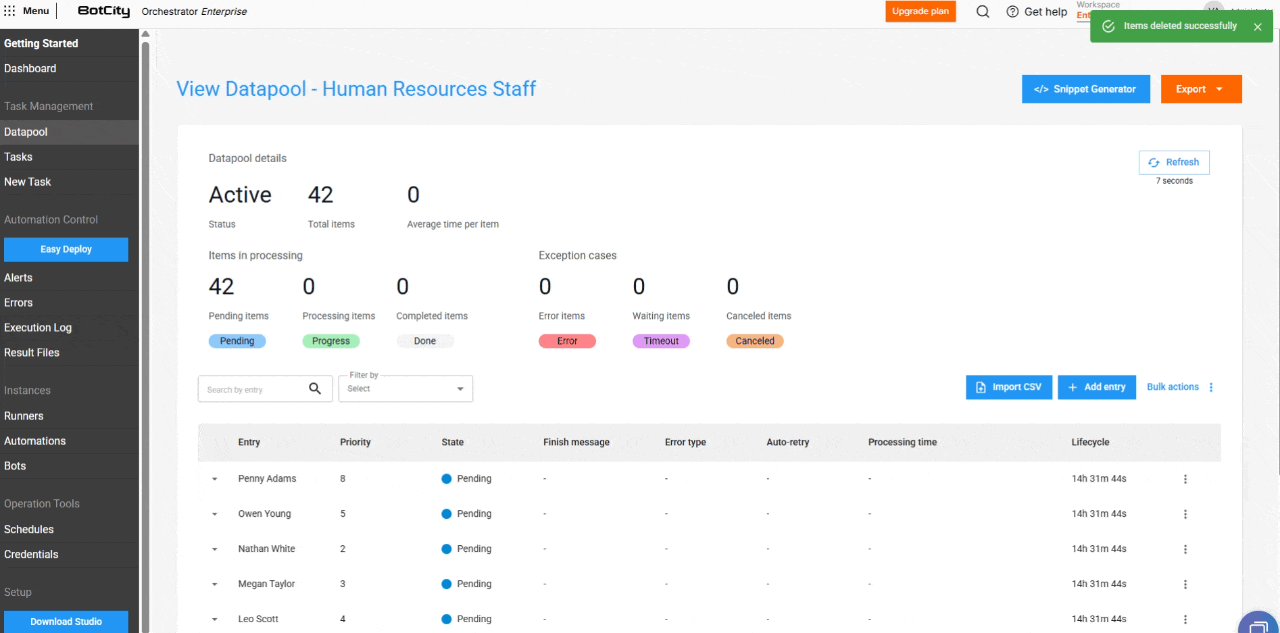
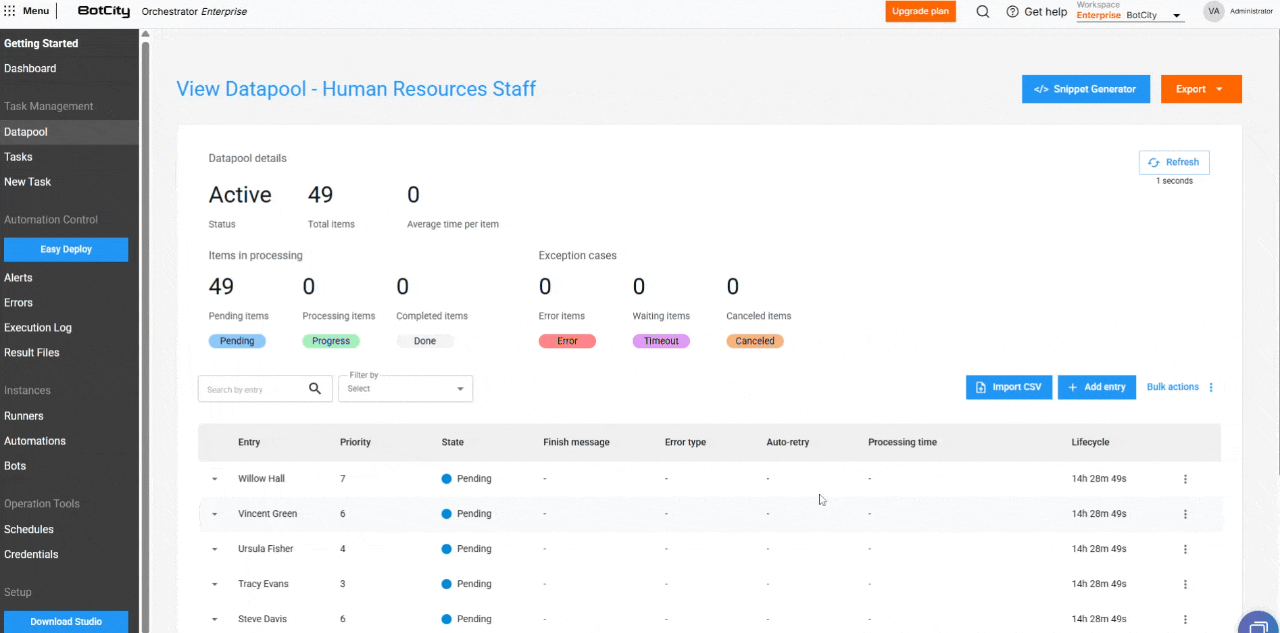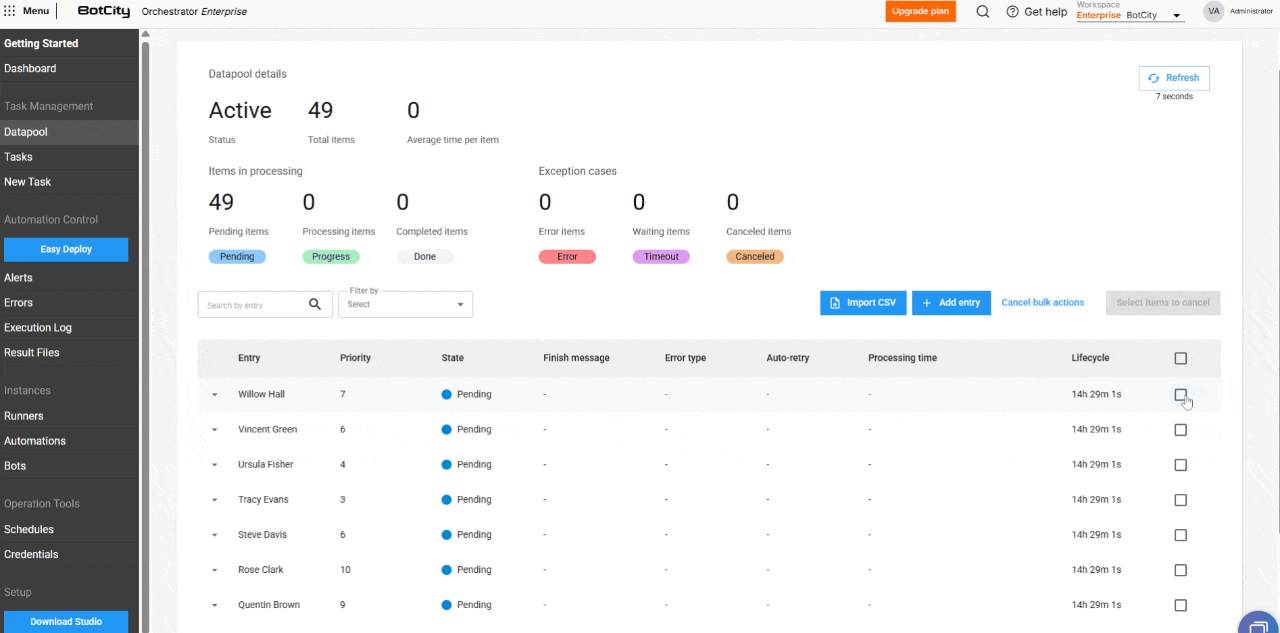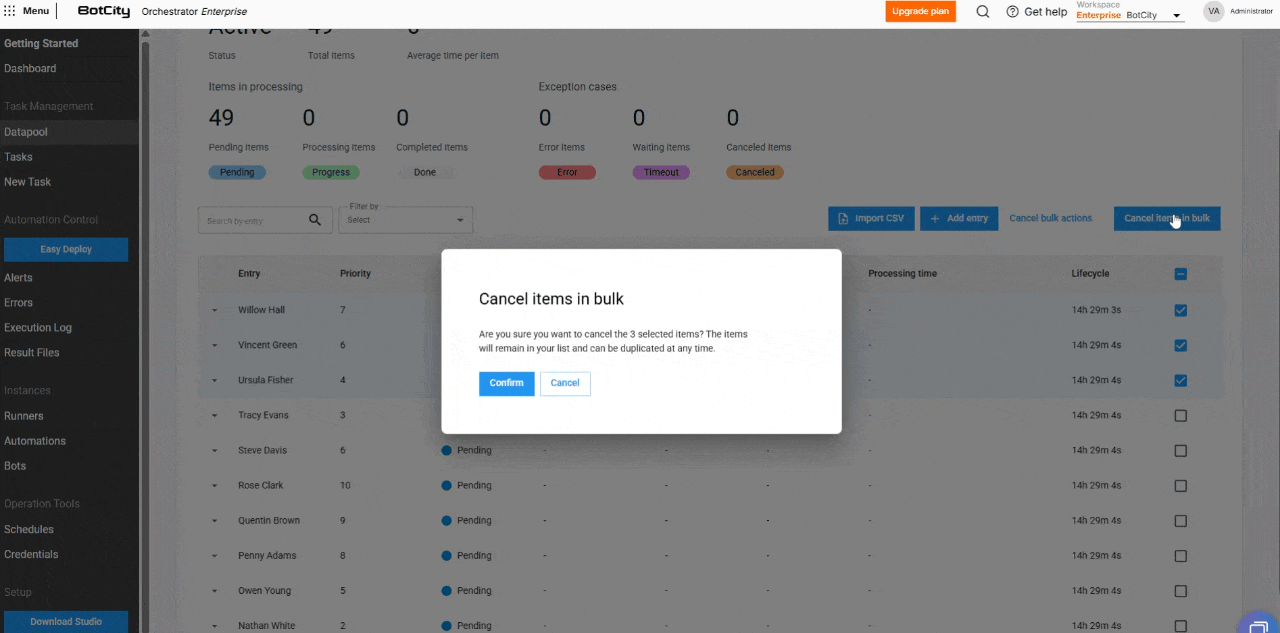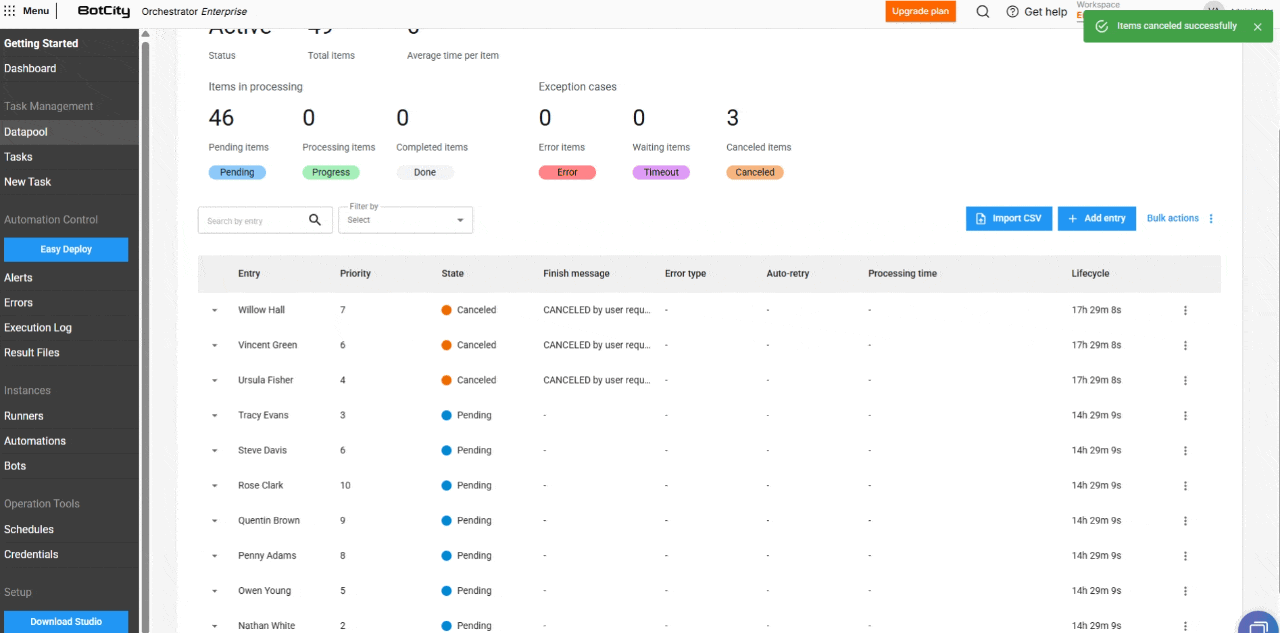
- Cancelamento de itens em massa: os itens com status
Pendentepodem ser cancelados em massa, permitindo que o usuário interrompa o processamento de grandes volumes de dados.
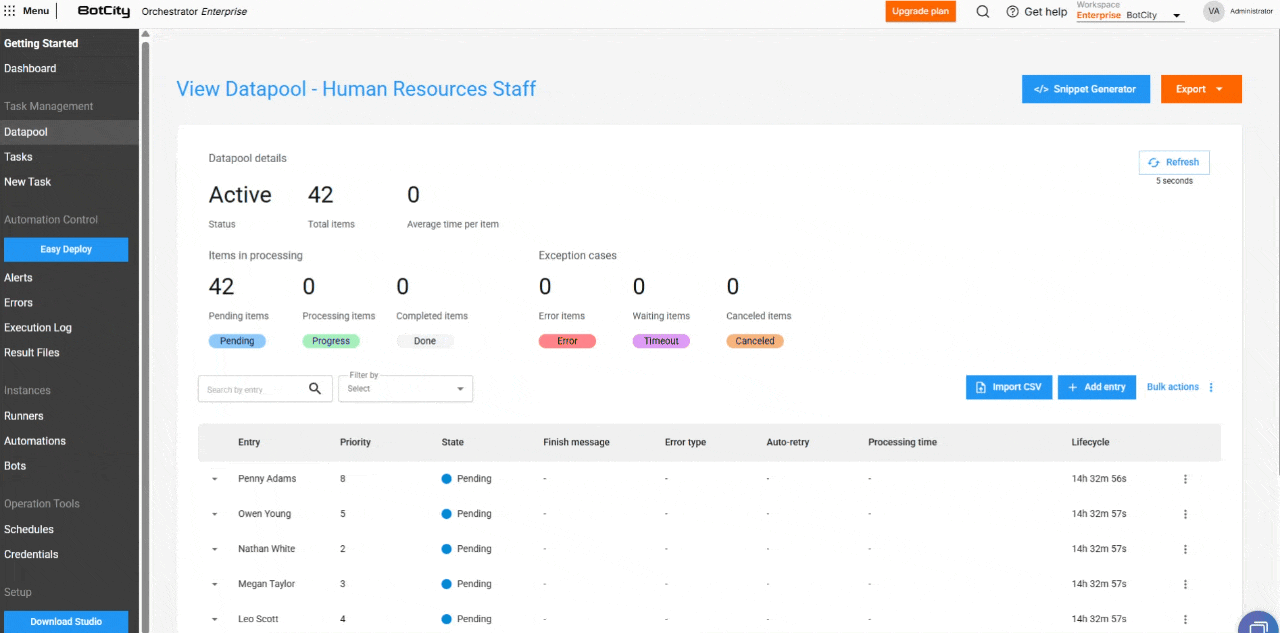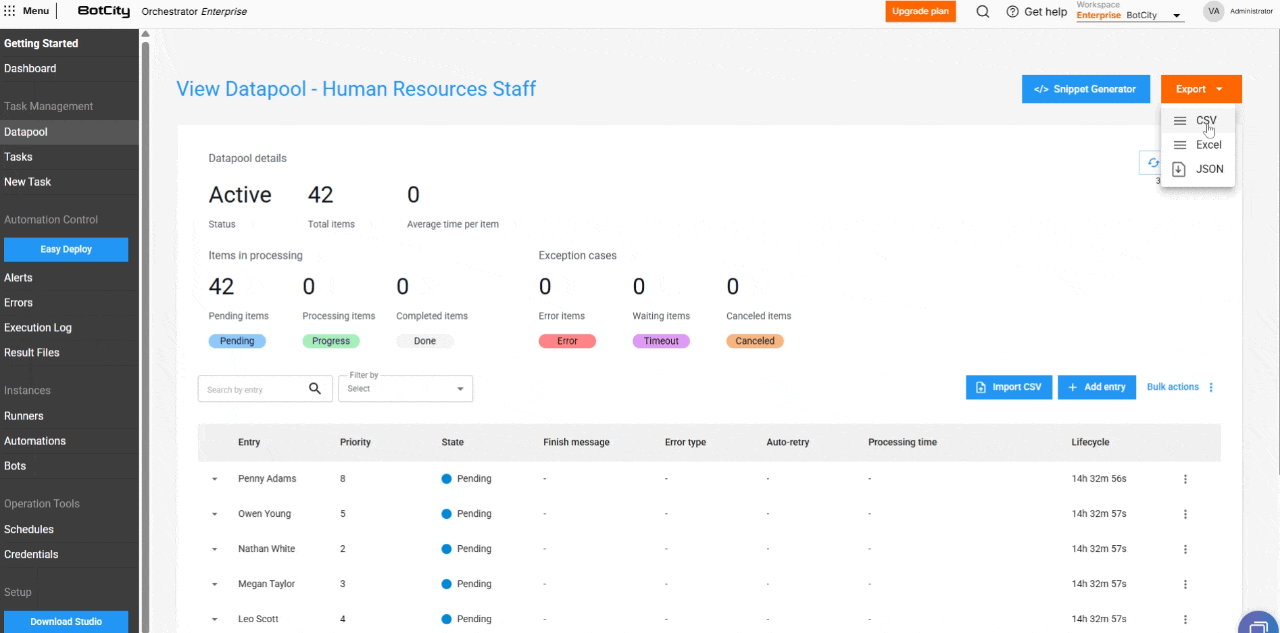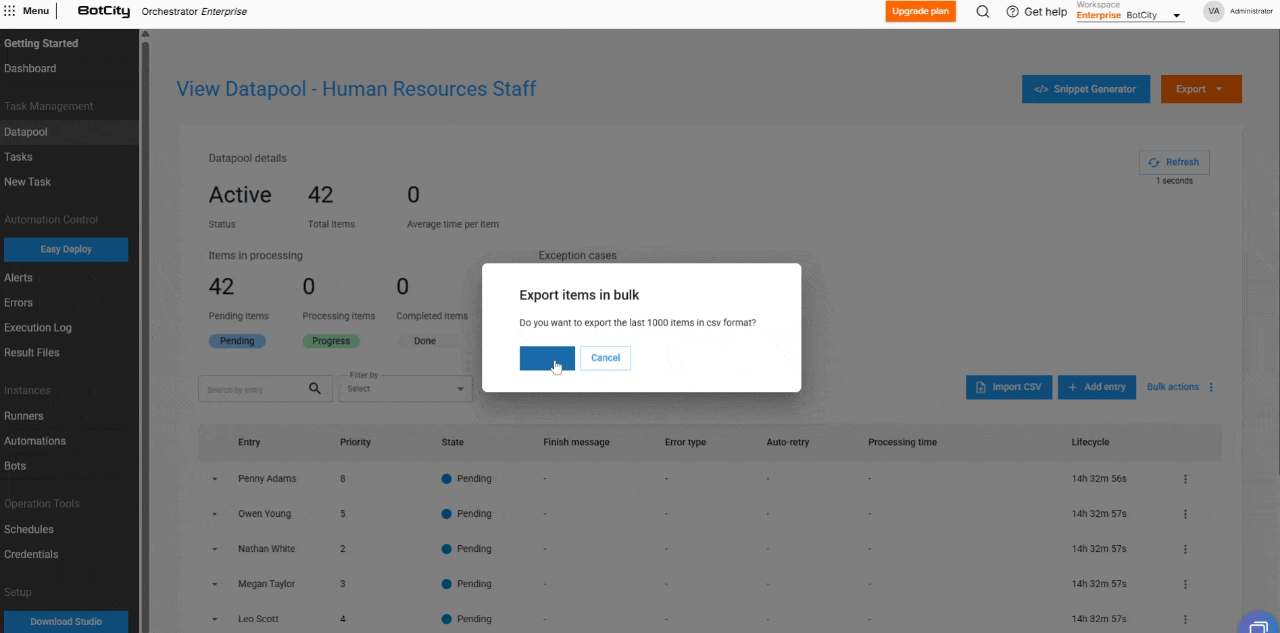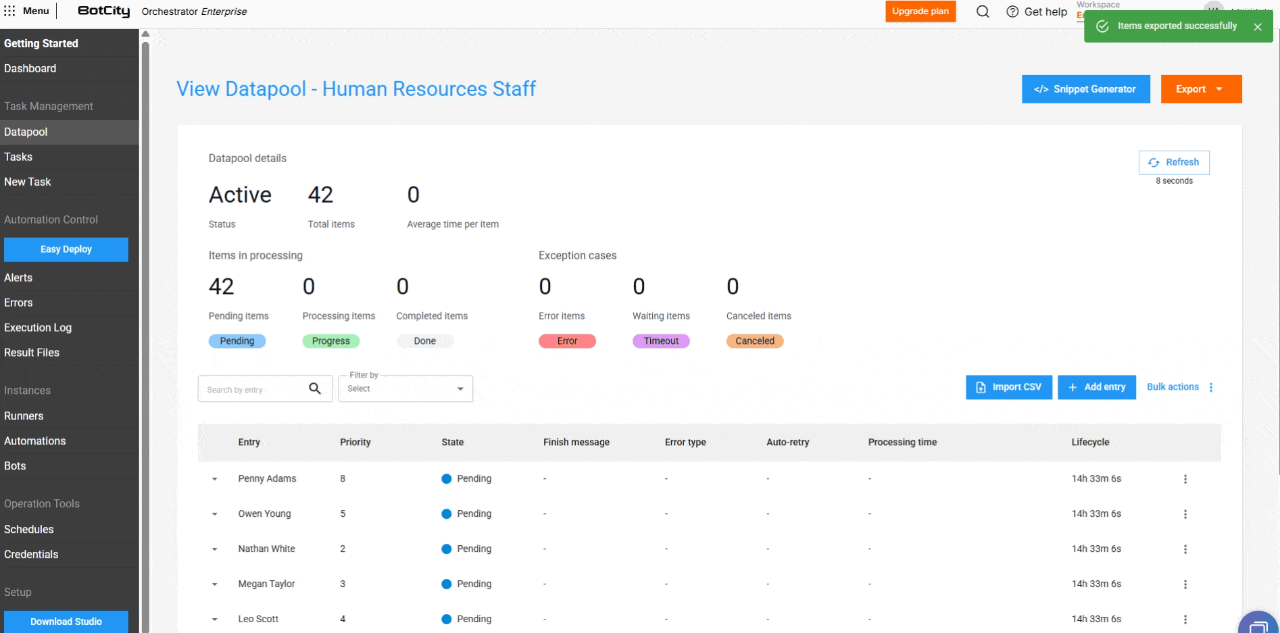
- Exportação de itens: O usuário pode exportar os últimos 1.000 itens mais recentes nos formatos
CSV,XLSXouJSON.
- Busca e filtros aprimorados: Agora é possível buscar itens pela coluna de entrada e filtrar por período específico ou intervalo de dias, facilitando a localização de itens.
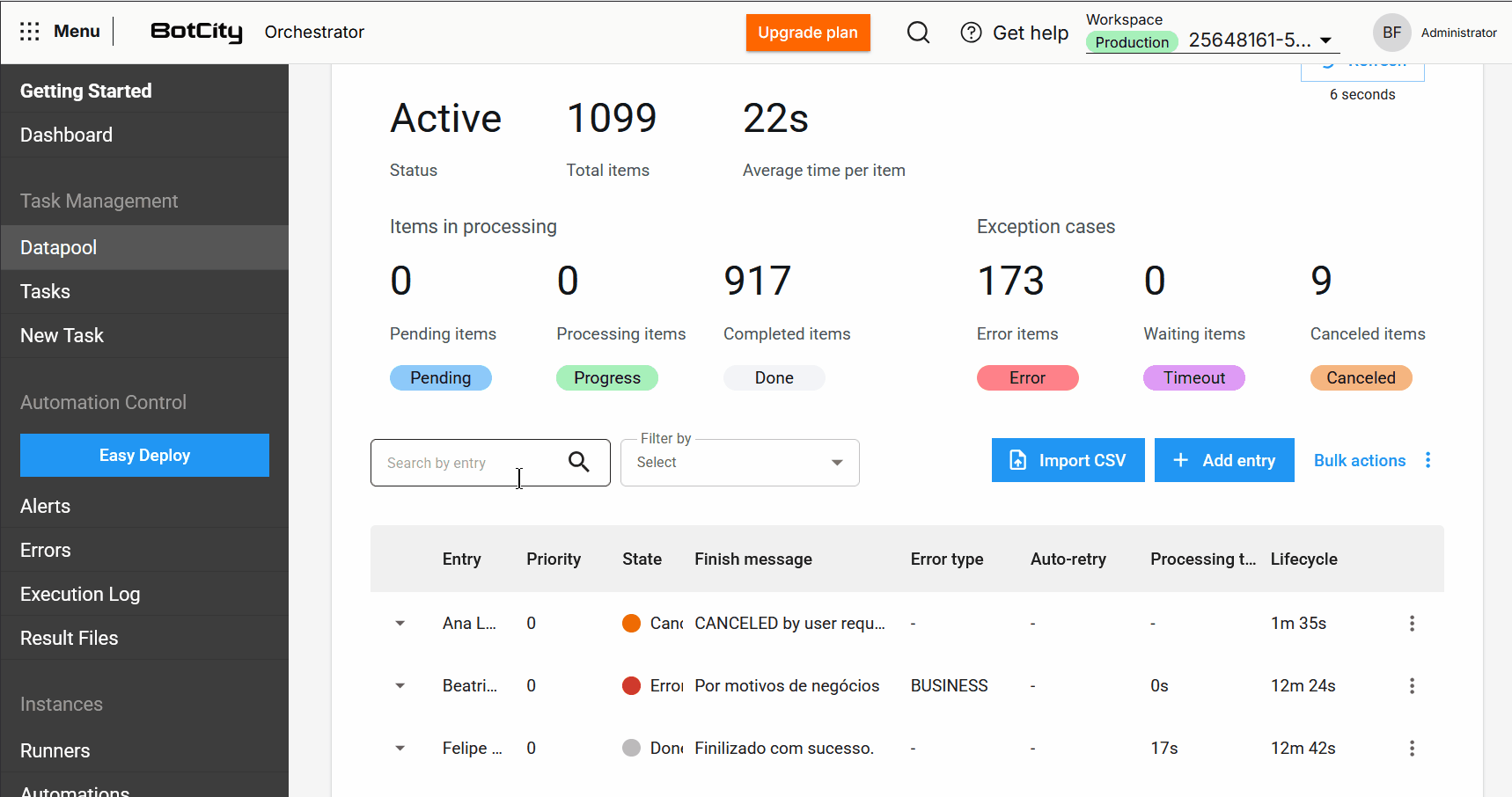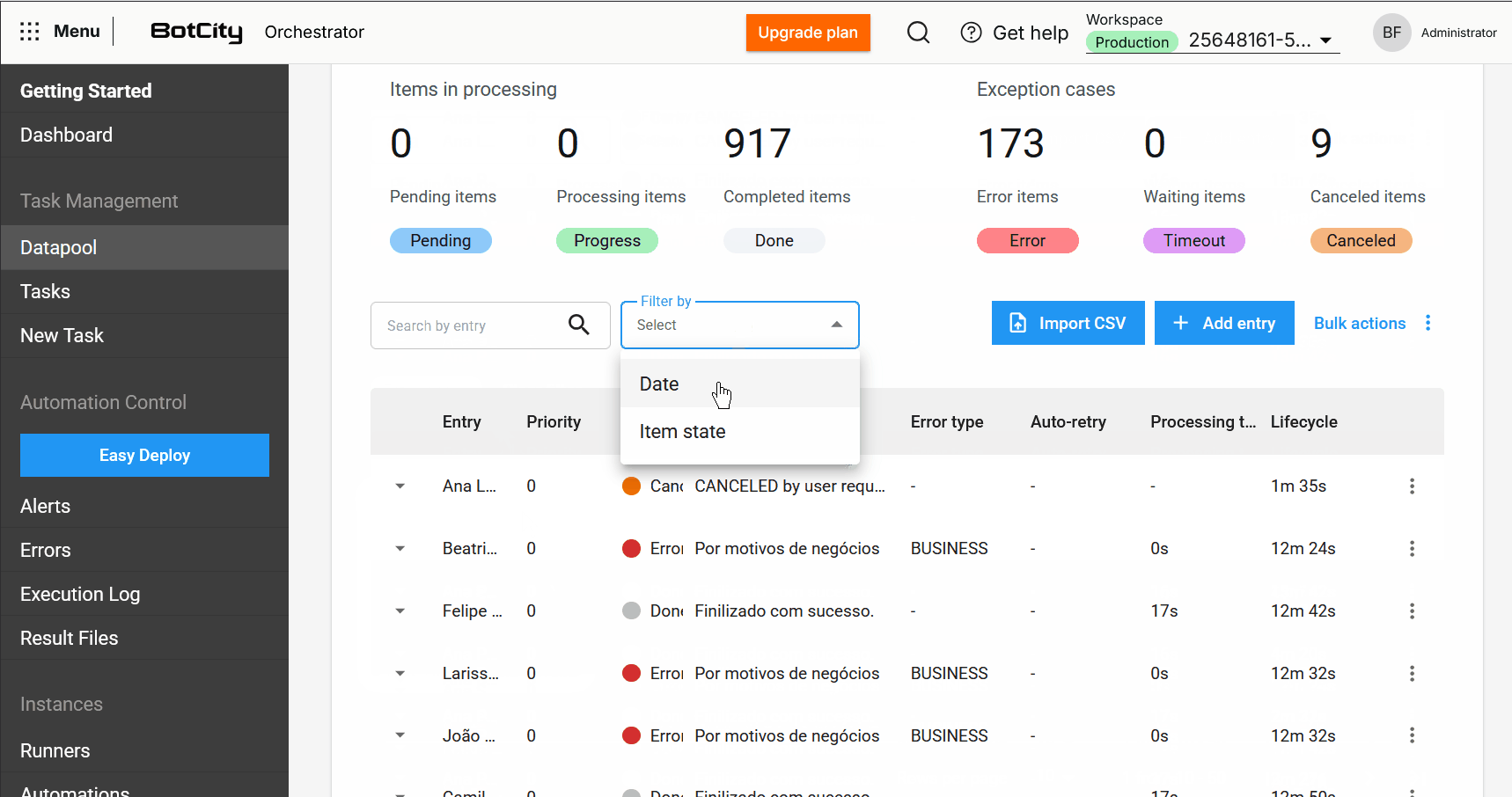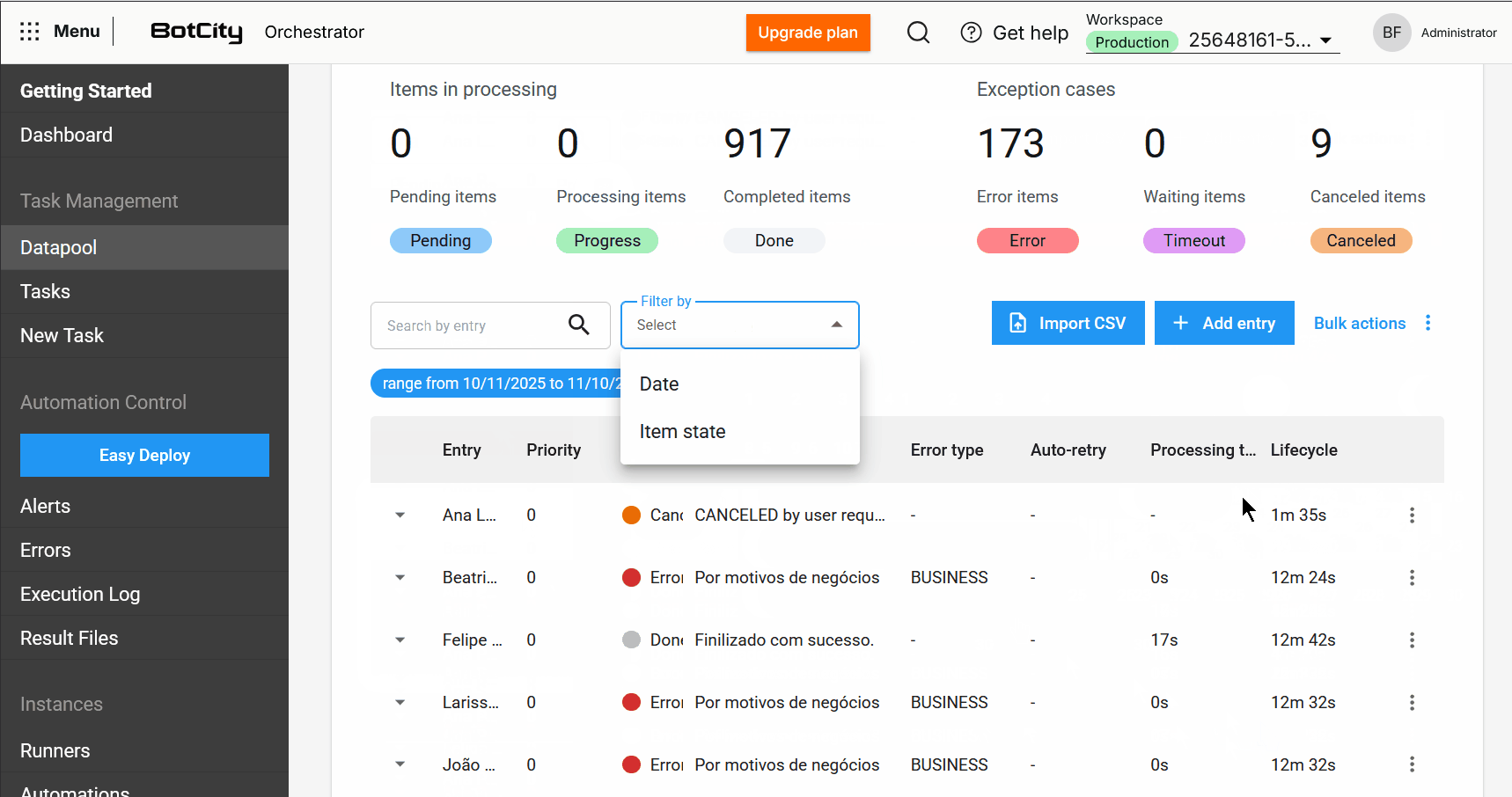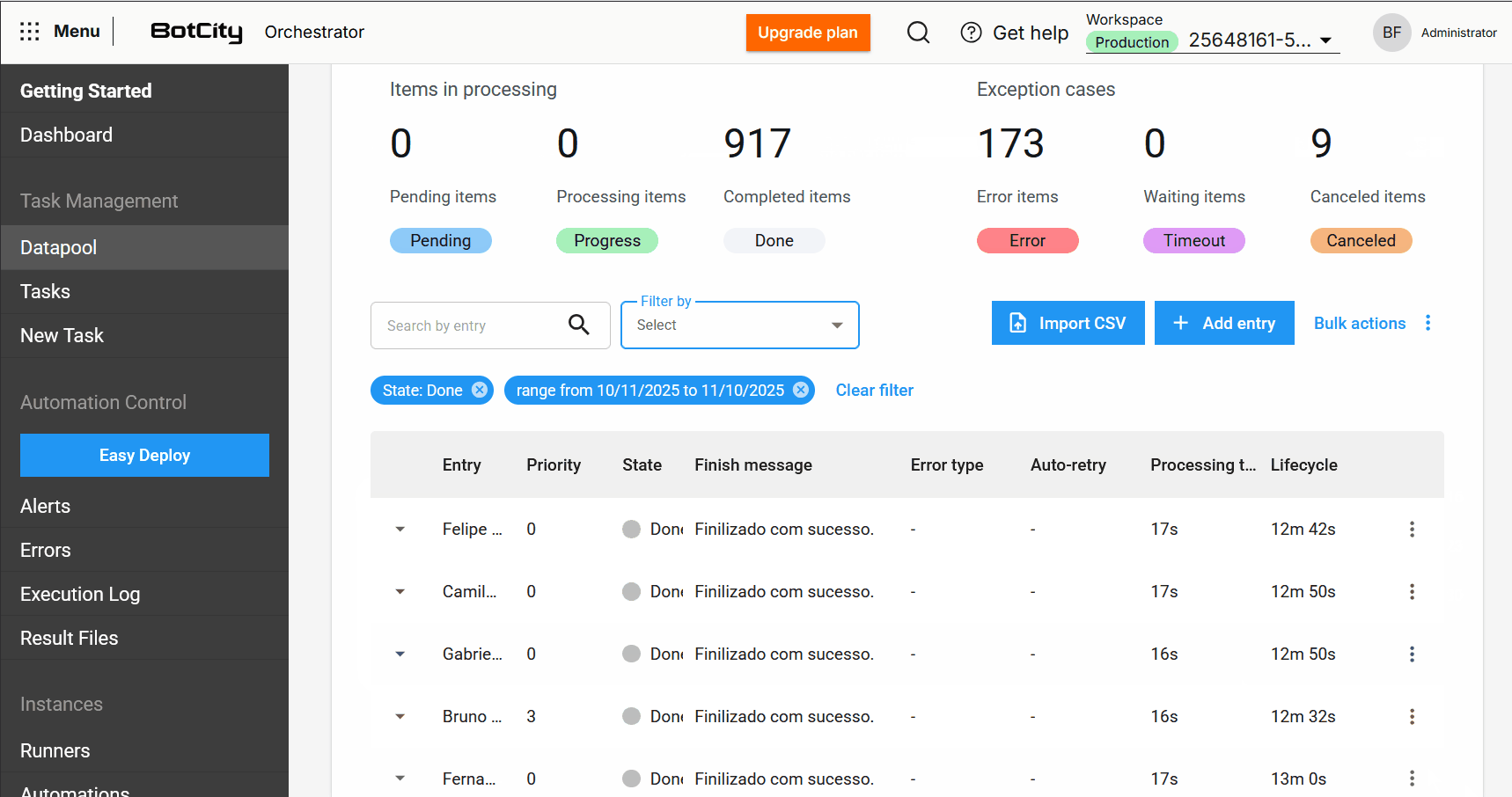
O Datapool 2.0 representa um salto significativo na forma como os usuários podem gerenciar e processar dados em lote. Essas melhorias foram implementadas para proporcionar mais controle, transparência e eficiência.
Se você tiver alguma dúvida sobre a transição para esta nova versão ou precisar de assistência para aproveitar ao máximo os novos recursos, você pode consultar nossa documentação oficial e conte com nossa equipe de suporte.