September¶
Datapool¶
We are excited to announce the updates to the project we internally call Datapool 2.0. After months of in-depth user research and a dedicated development and implementation cycle, we present a series of new features carefully designed to help users process items more efficiently and gain deeper insights into their data.
Datapool Creation and Configuration¶
Creating a new Datapool is now an intuitive process, guided by steps that ensure complete and accurate configuration. In addition to interface improvements, features have been added to make the Datapool more robust and flexible.
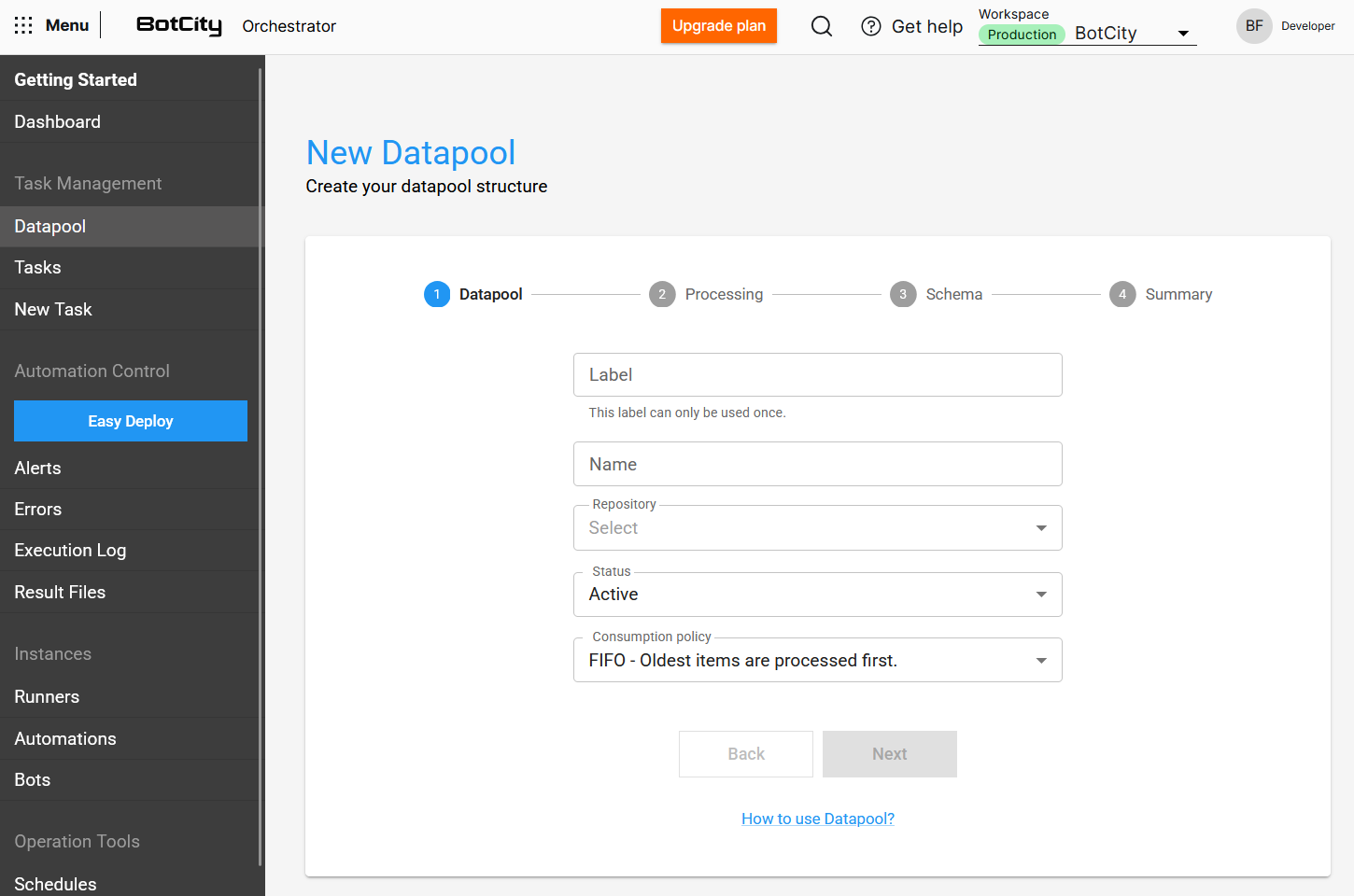
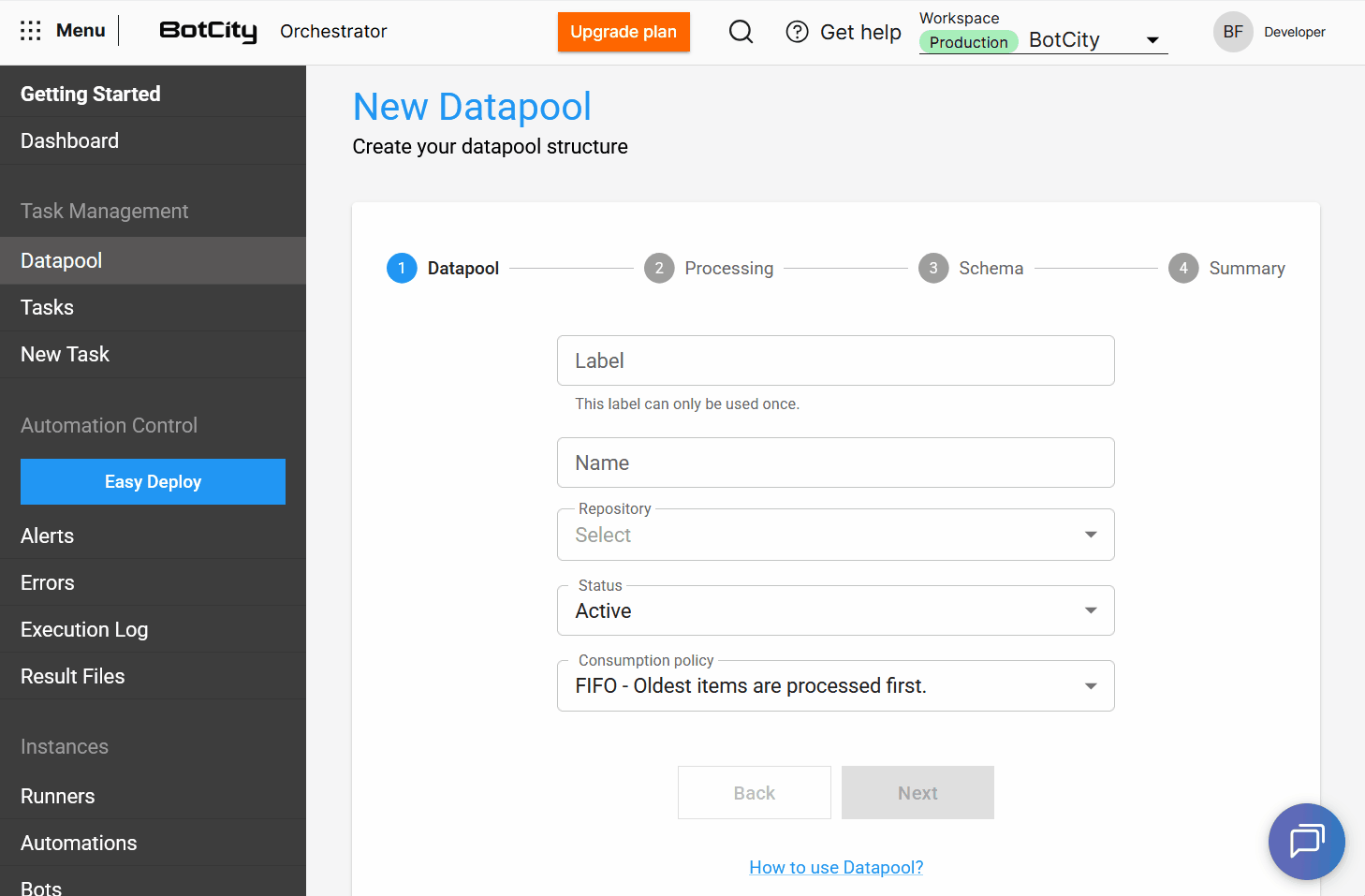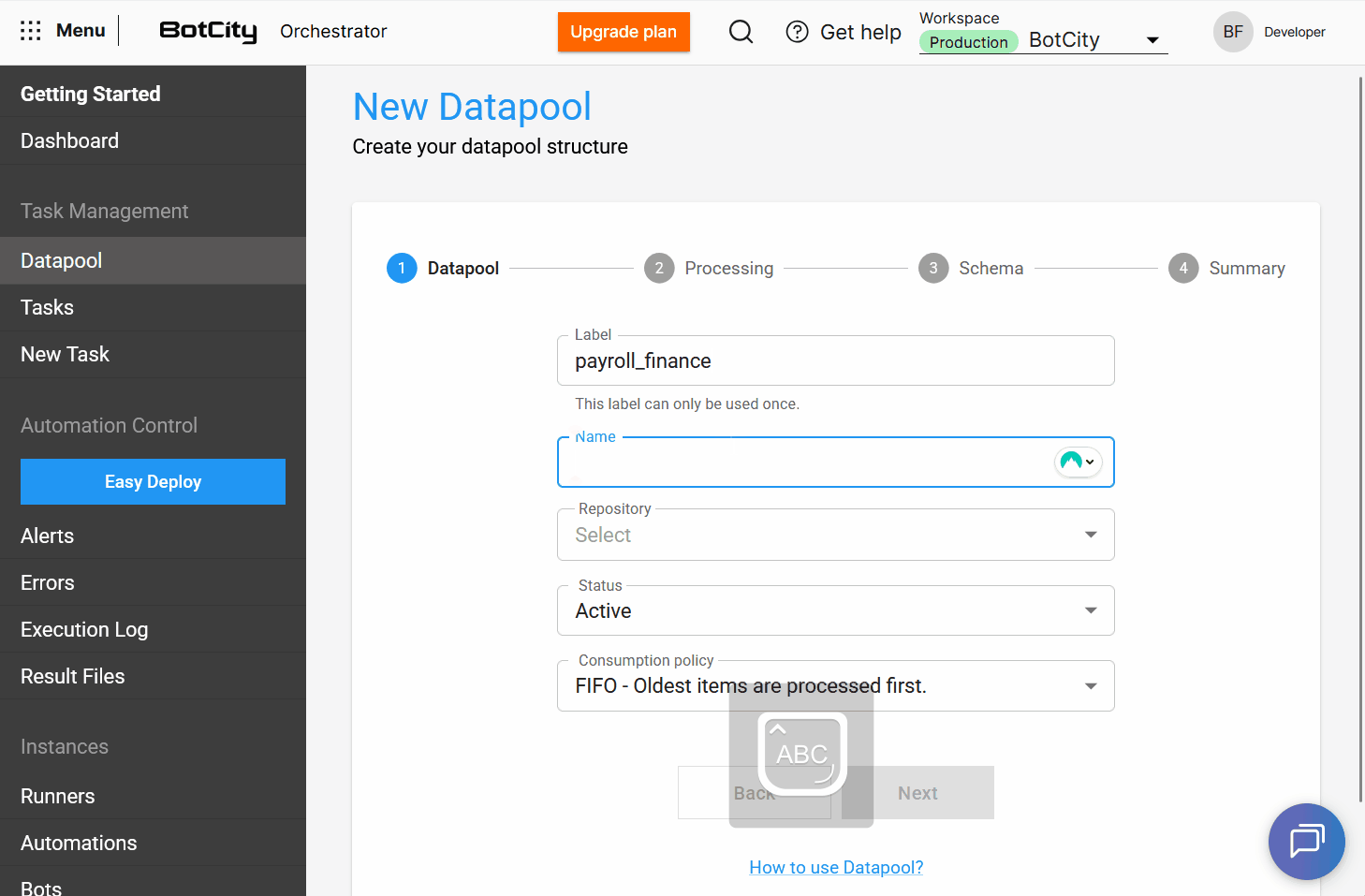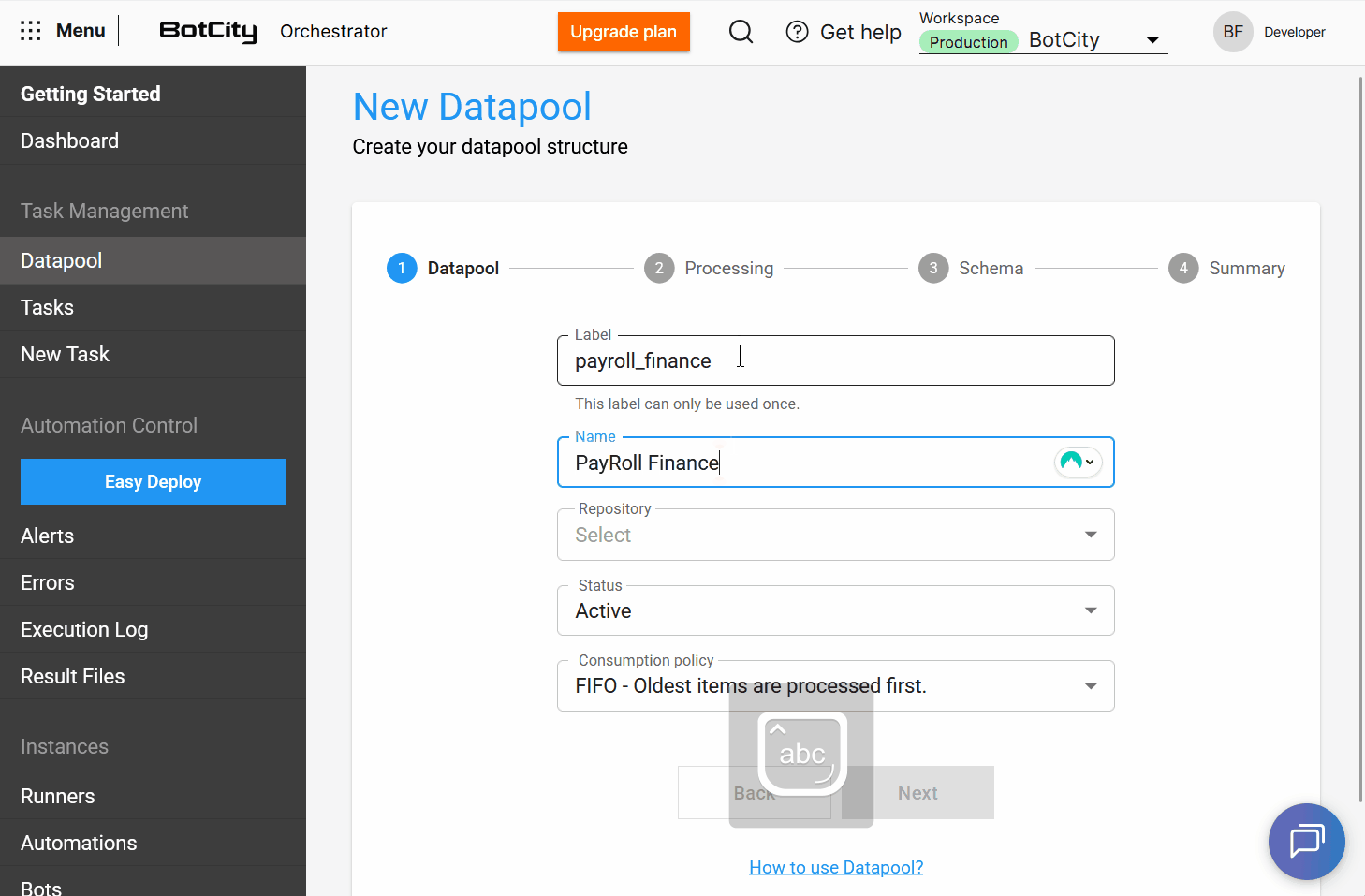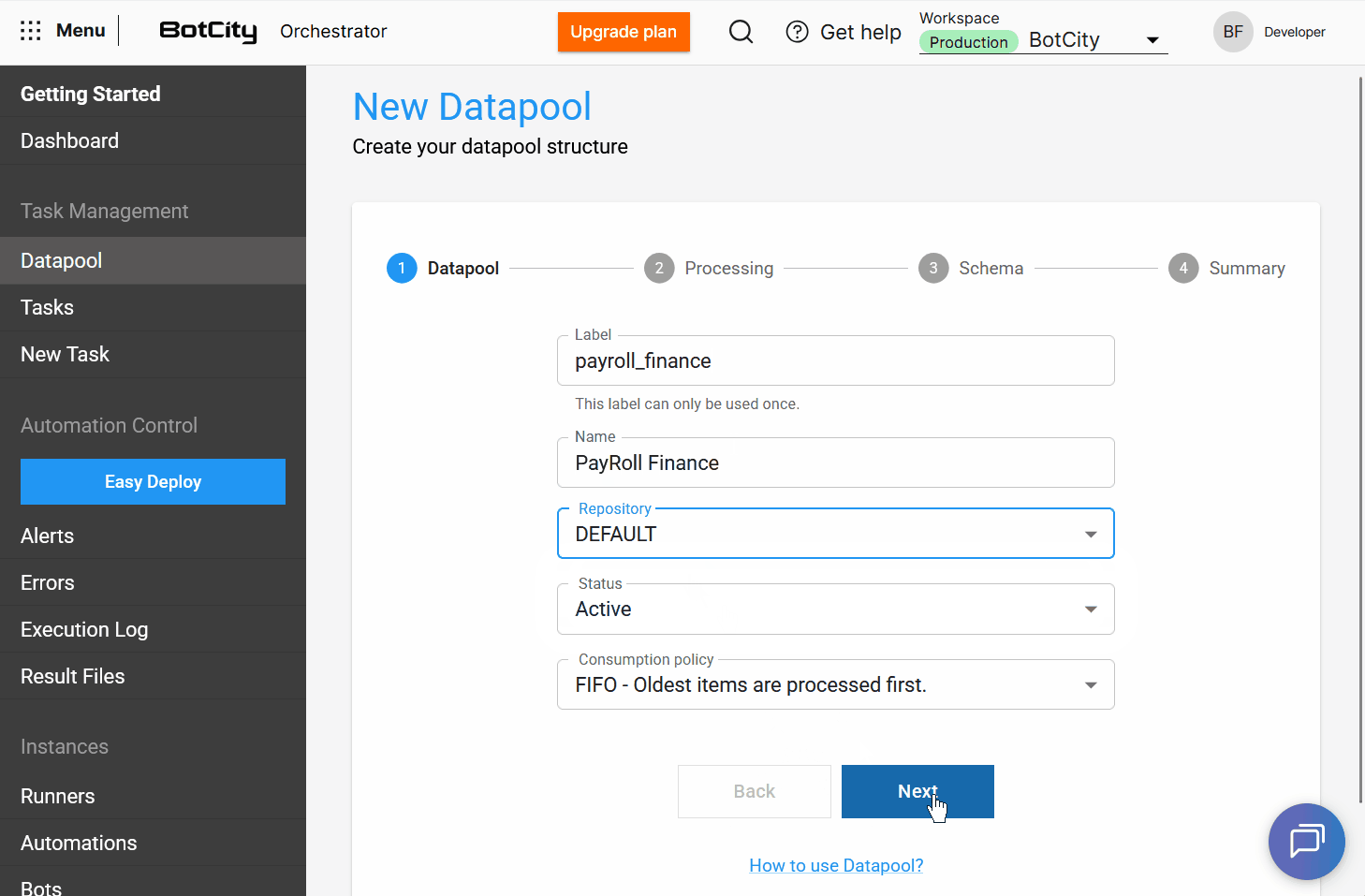
Step-by-Step Creation Process¶
The creation interface has been restructured into a step-by-step flow to simplify configuration:
- Datapool: Configure the basic information of the Datapool.
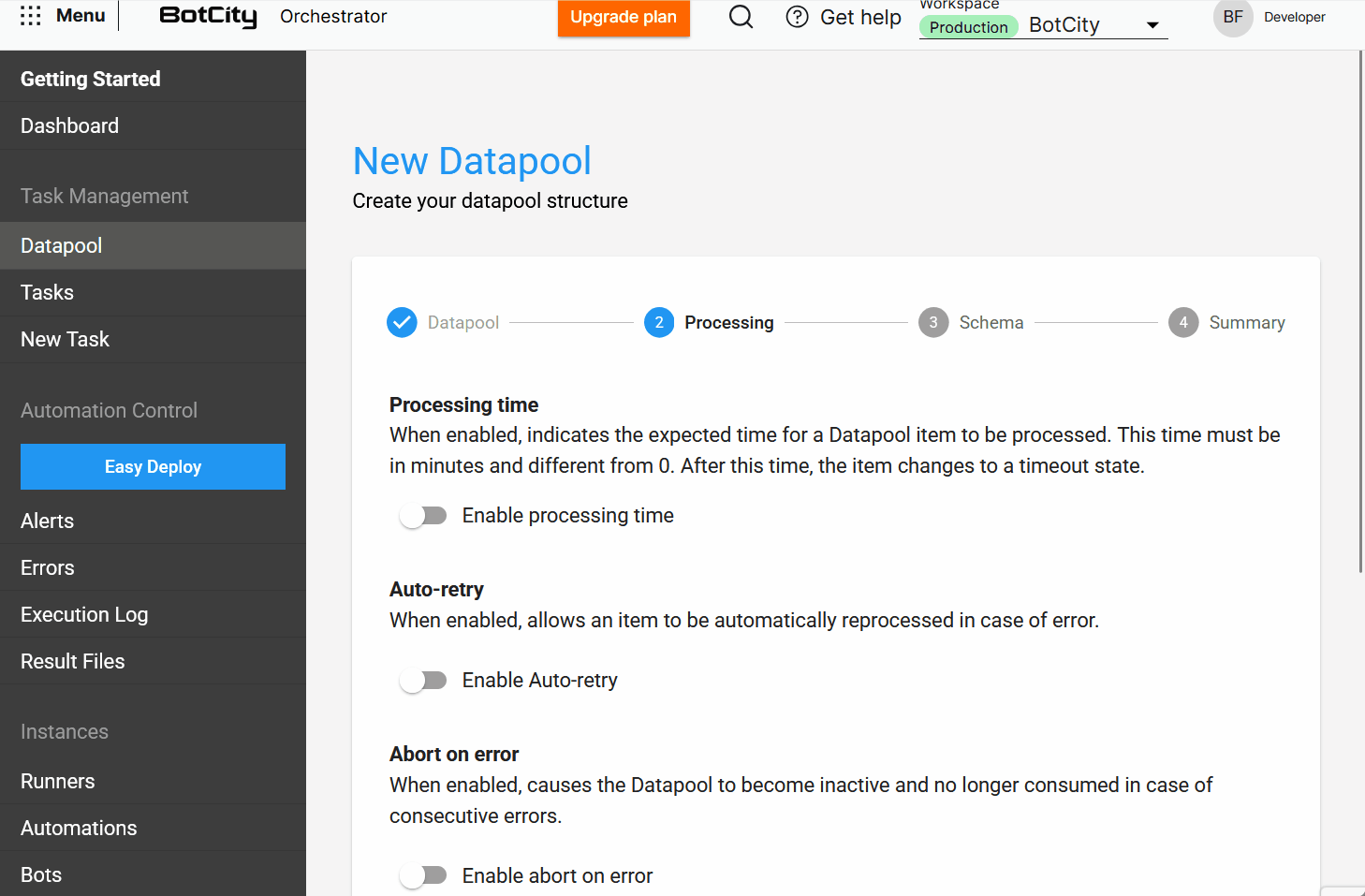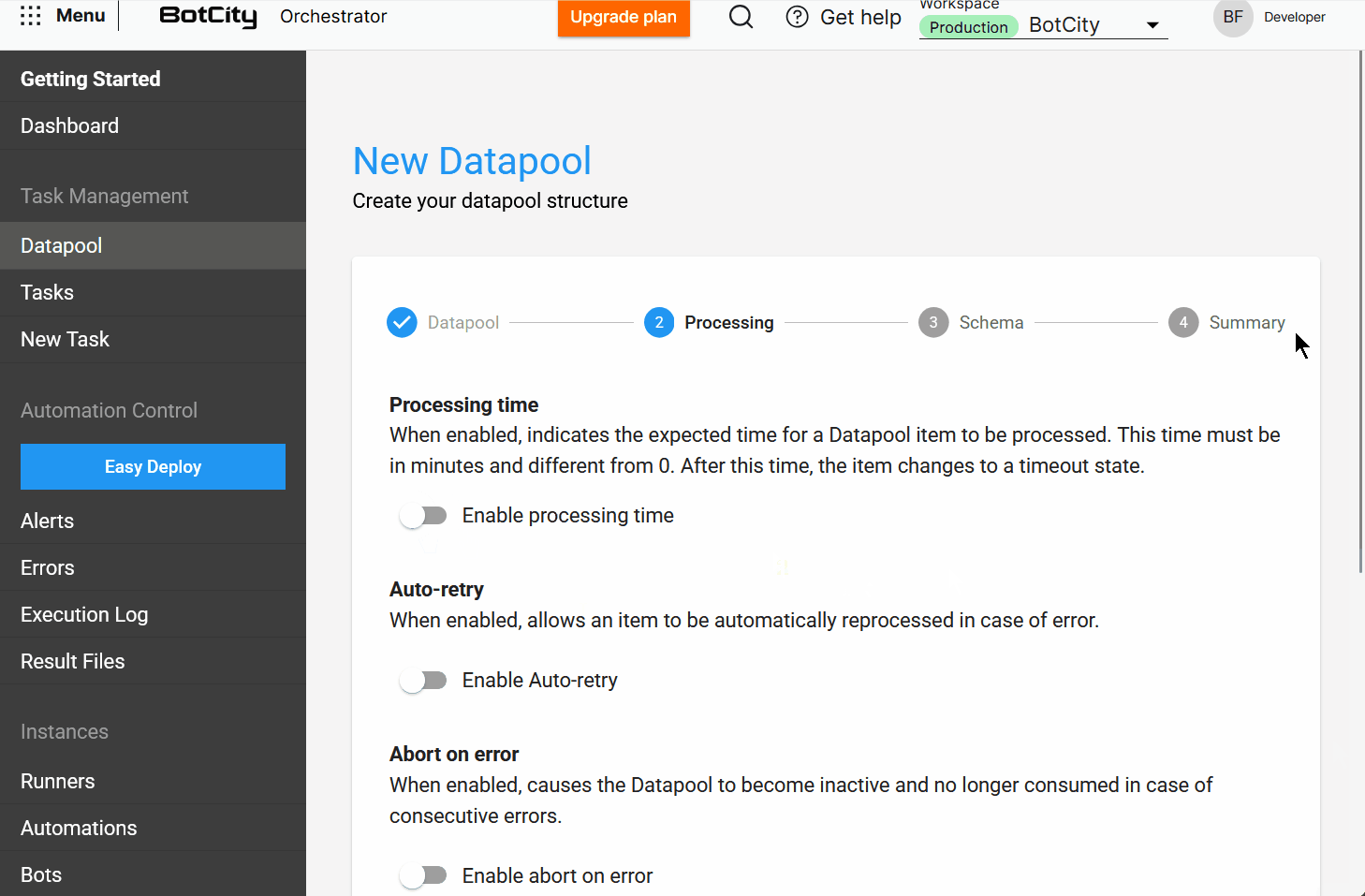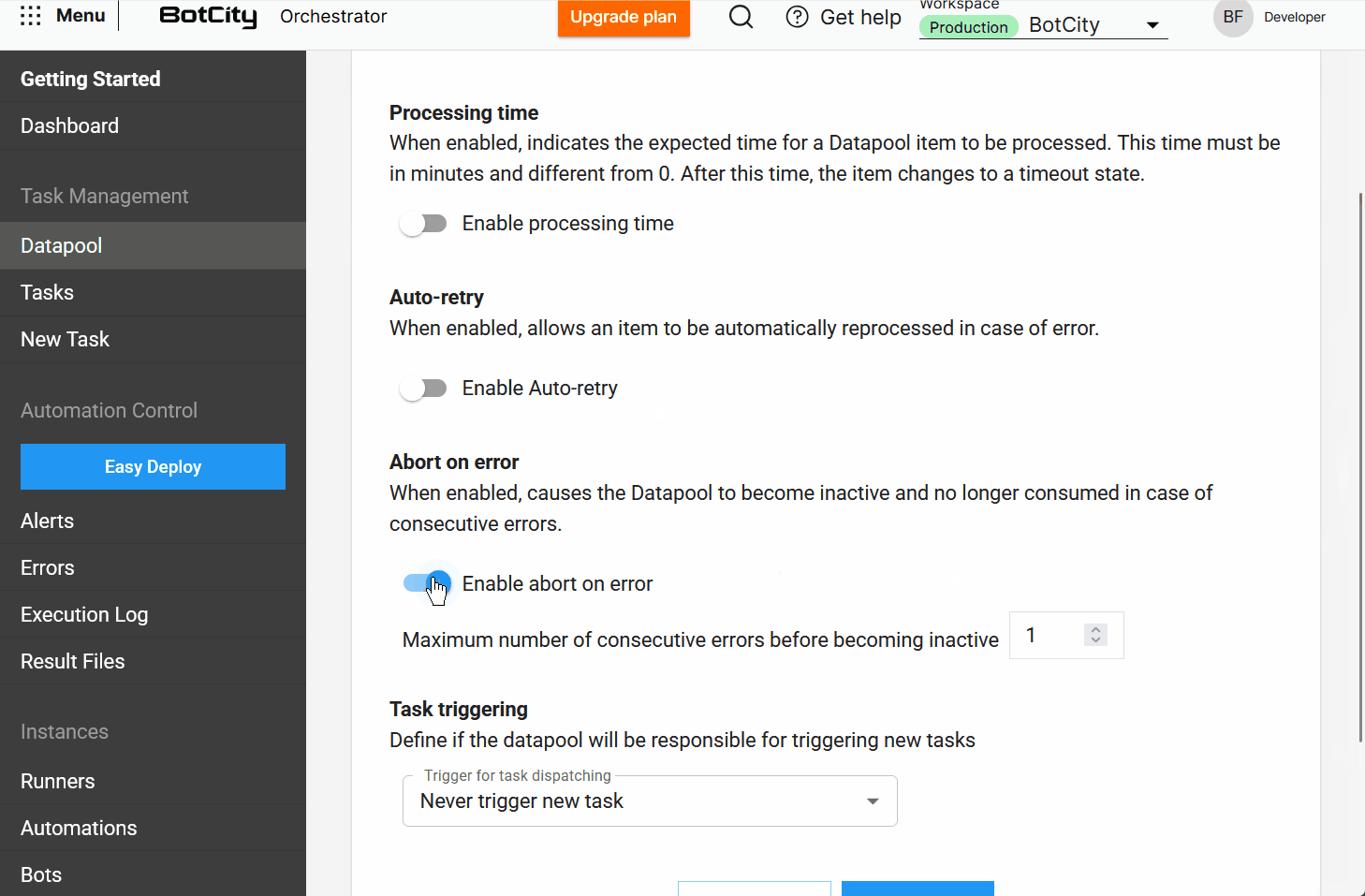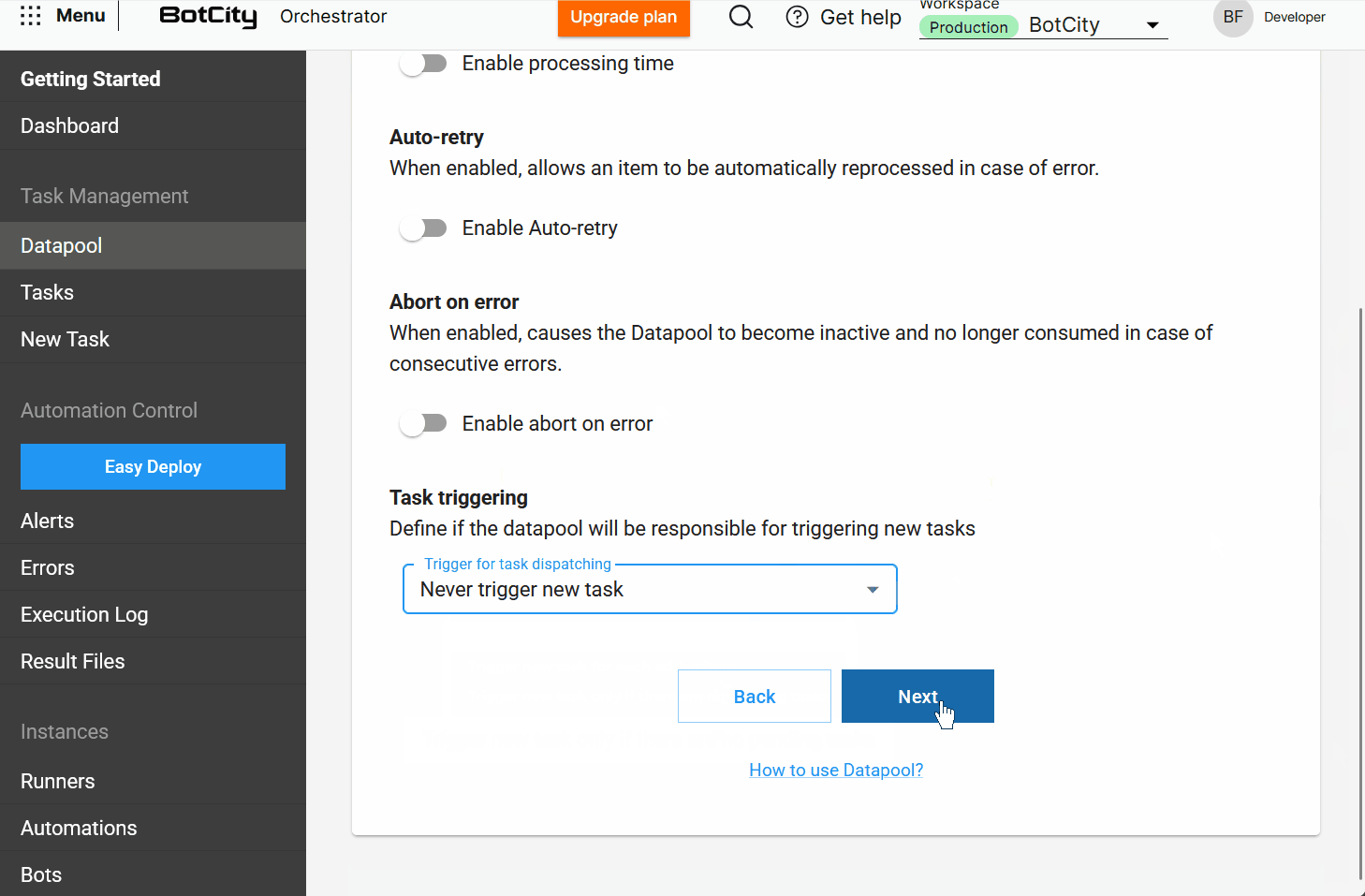
- Processing: Define how items will be processed. Here, users can find options such as
processing time,auto-retry,abort on error, andtask triggering. - Schema: Configure the data structure for processing items.
- Summary: Review all choices made before finalizing the Datapool creation.
Configuration Features¶
With this update, the Datapool allows users to assign a label and a name to its structure.
label: a unique identifier in the system that cannot be repeated.name: a user-friendly identifier for the main Datapool list, which can be repeated if the structure is recreated.
Explanatory Textline in all Datapool features, with a line of text explaining the functionality and purpose of each option, assisting users in configuration.
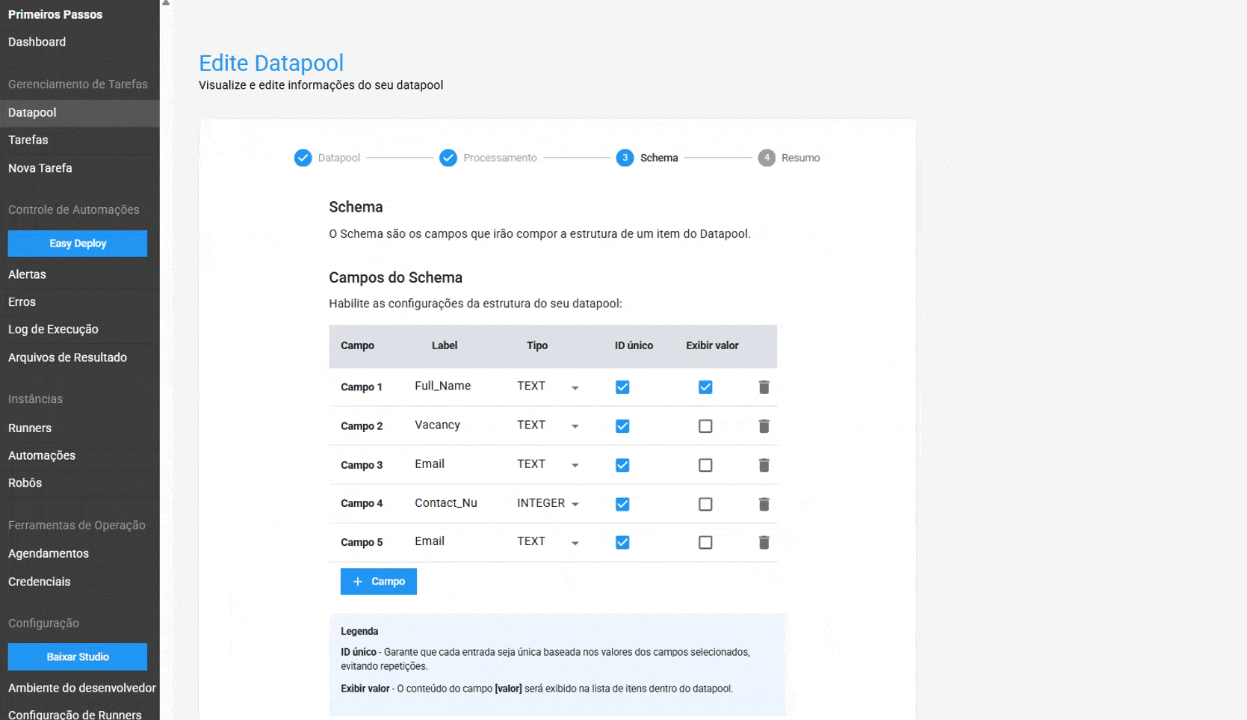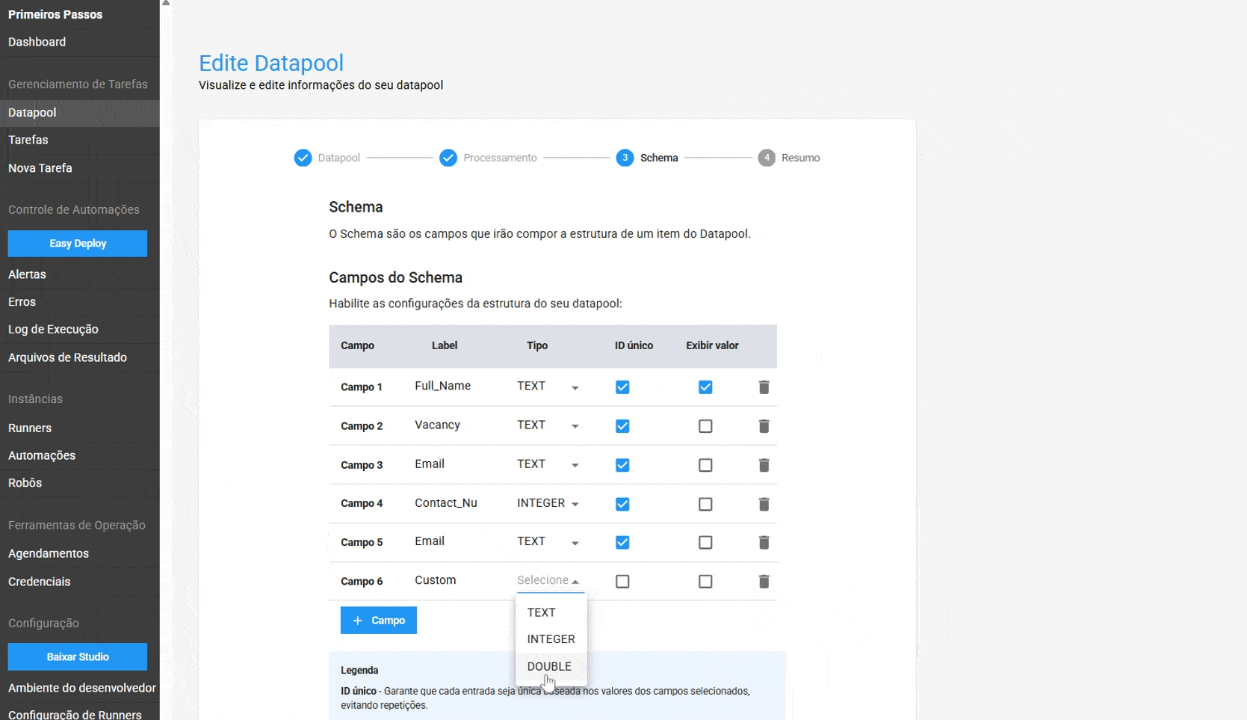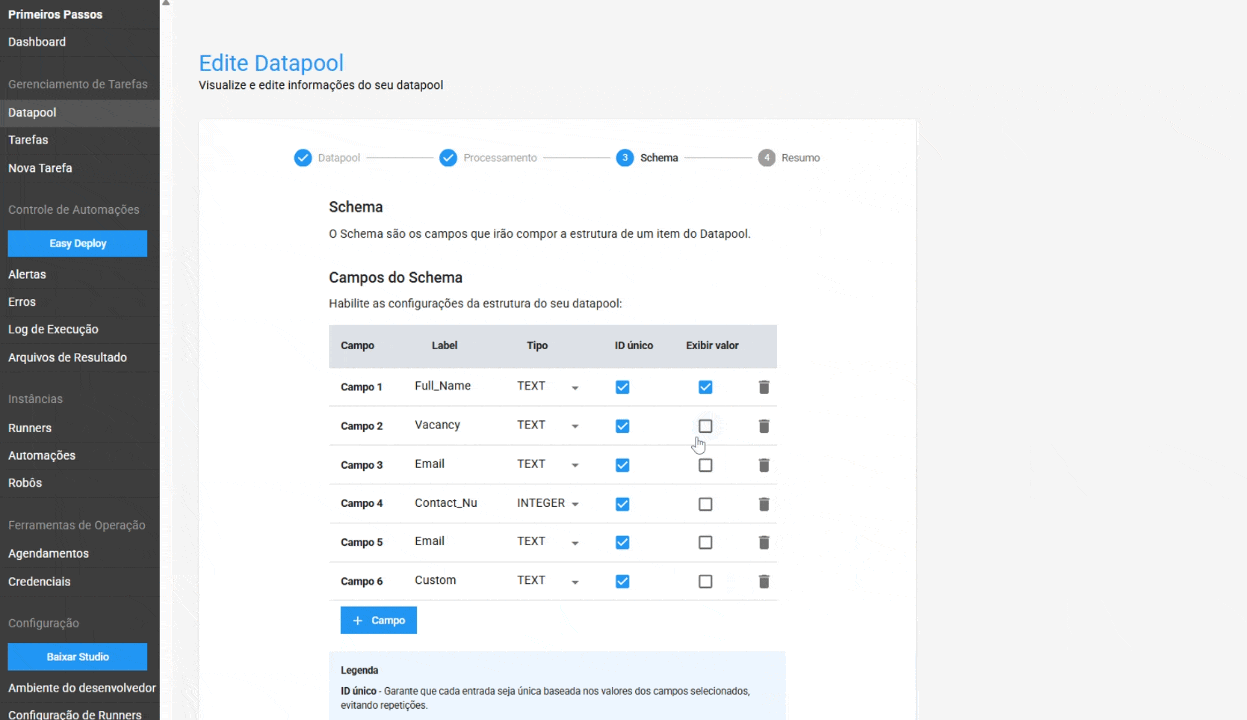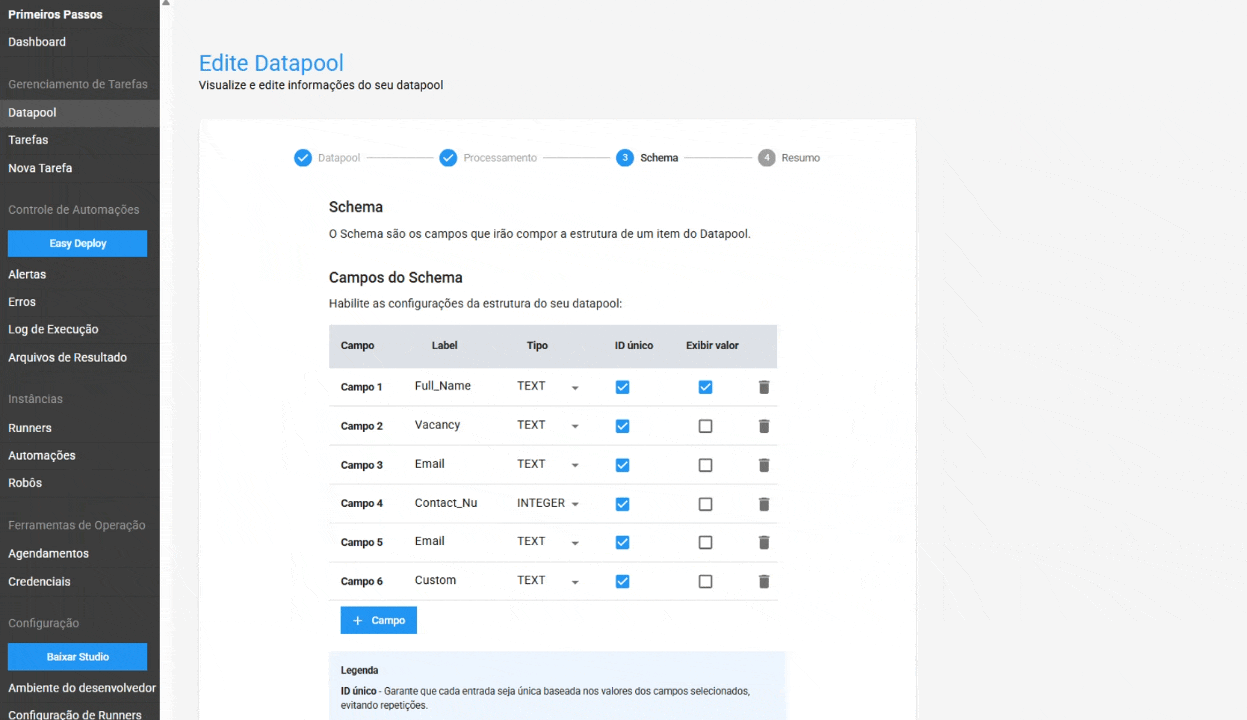
In the Schema, the following configurations have been added:
- Unique ID in Schema: When this option is enabled, the Datapool ensures that each entry is unique, based on the selected fields' values. This helps avoid data duplication and ensures data integrity. This feature is optional.
- Value Display in Item Table: Allows users to display the content of a specific field directly in the Datapool item table, making it easier to locate and manage an item. This is an optional feature.
Item Management and Manipulation¶
Improvements in item management and manipulation have been updated to give users more control and visibility over their data processing.
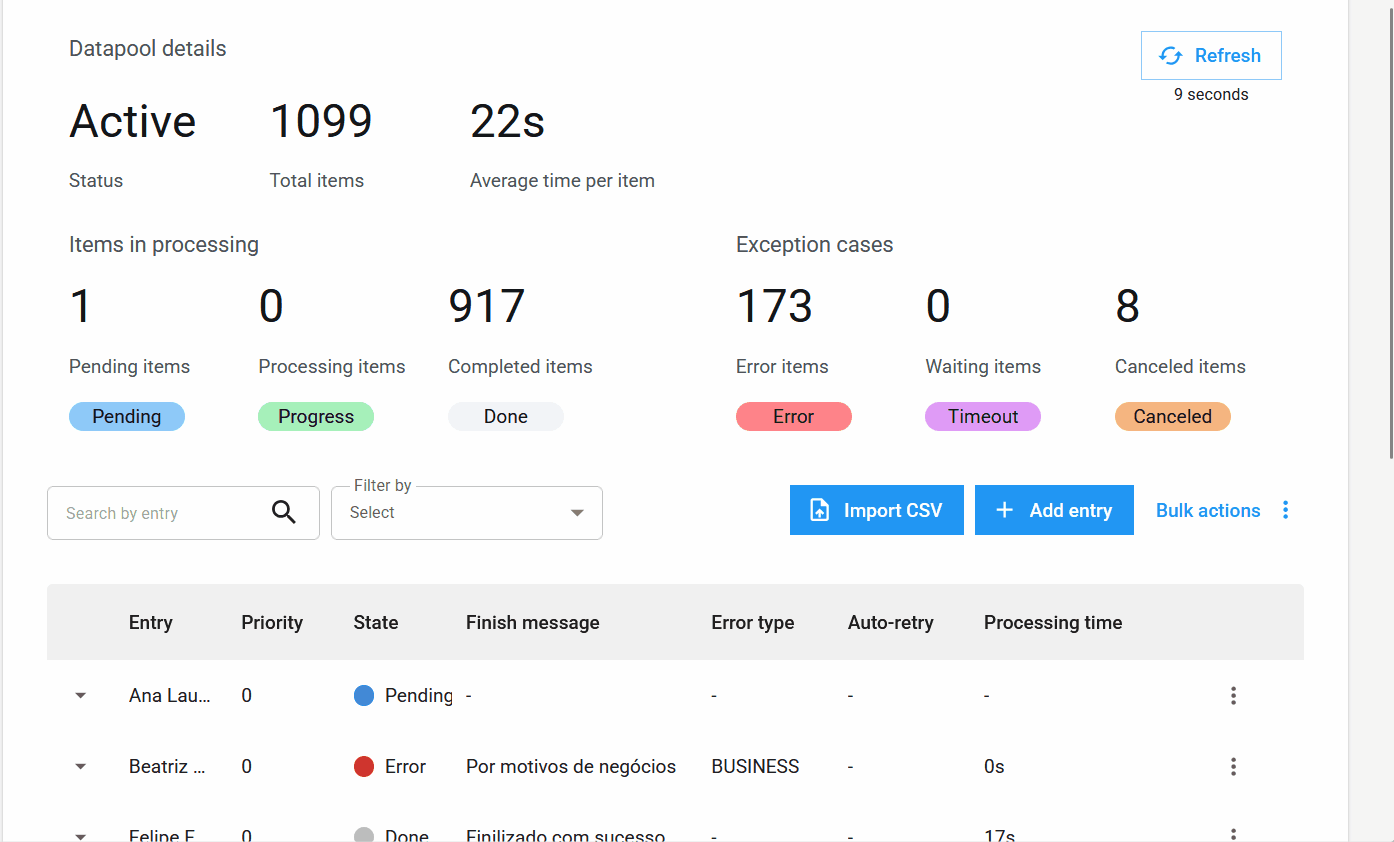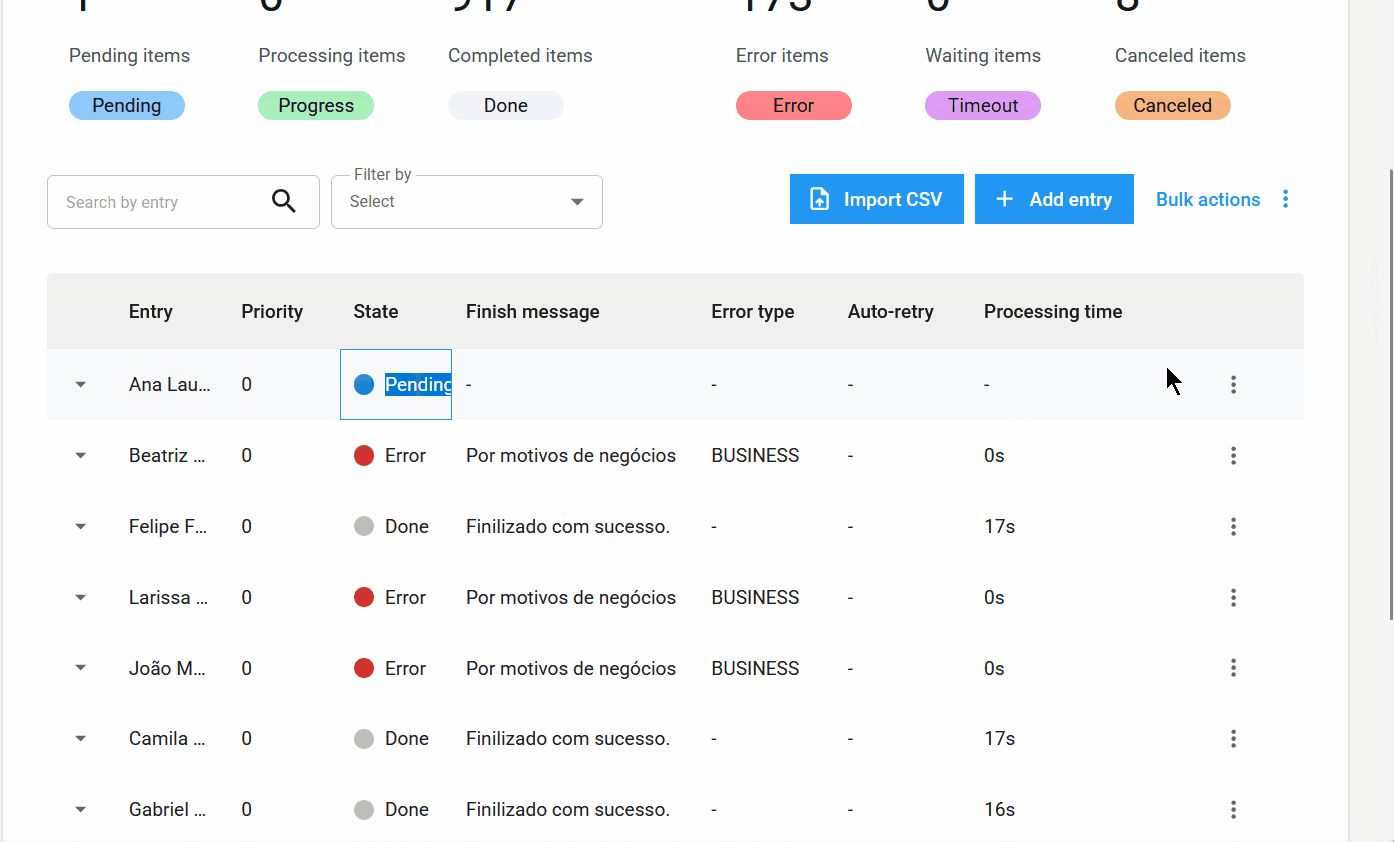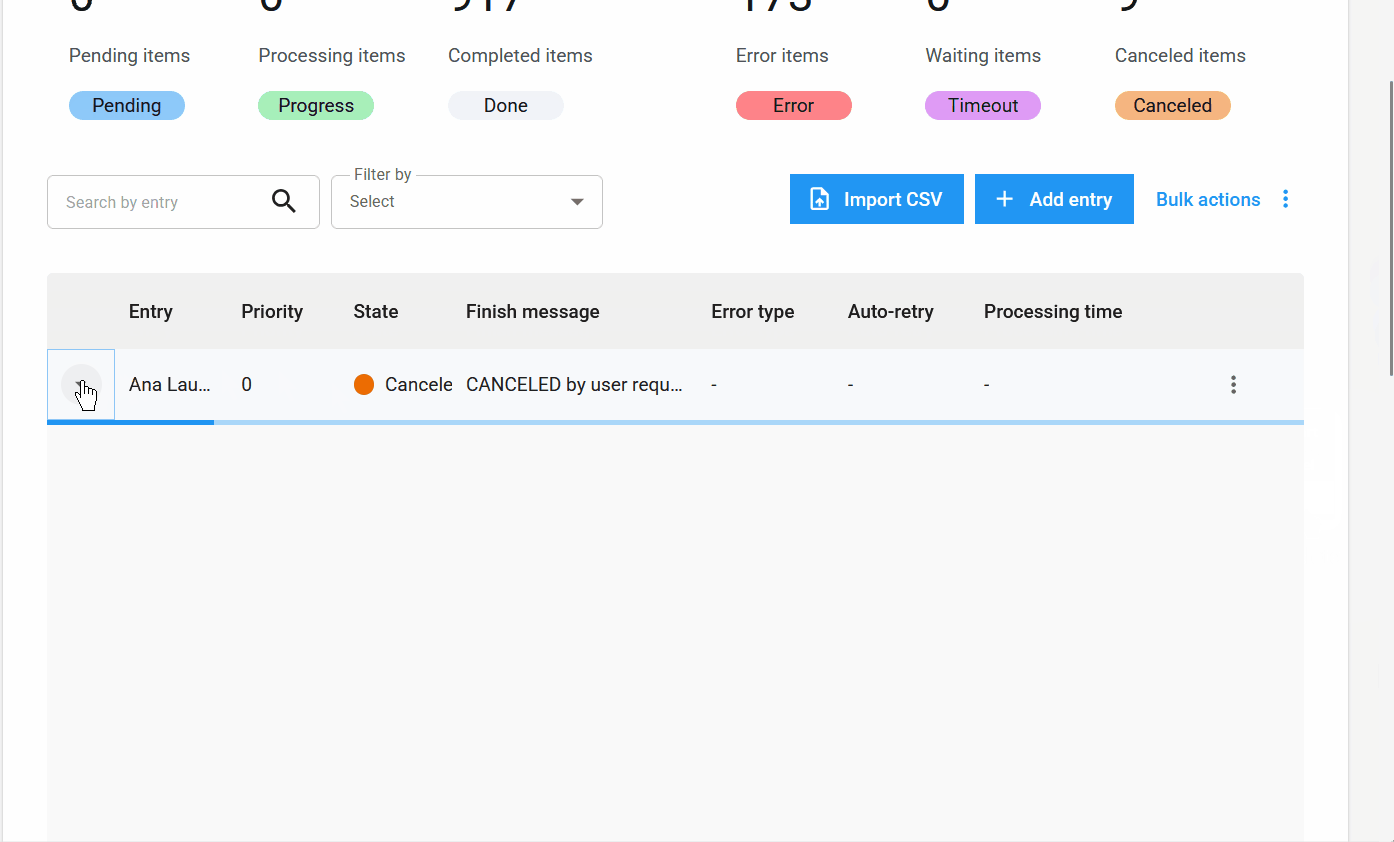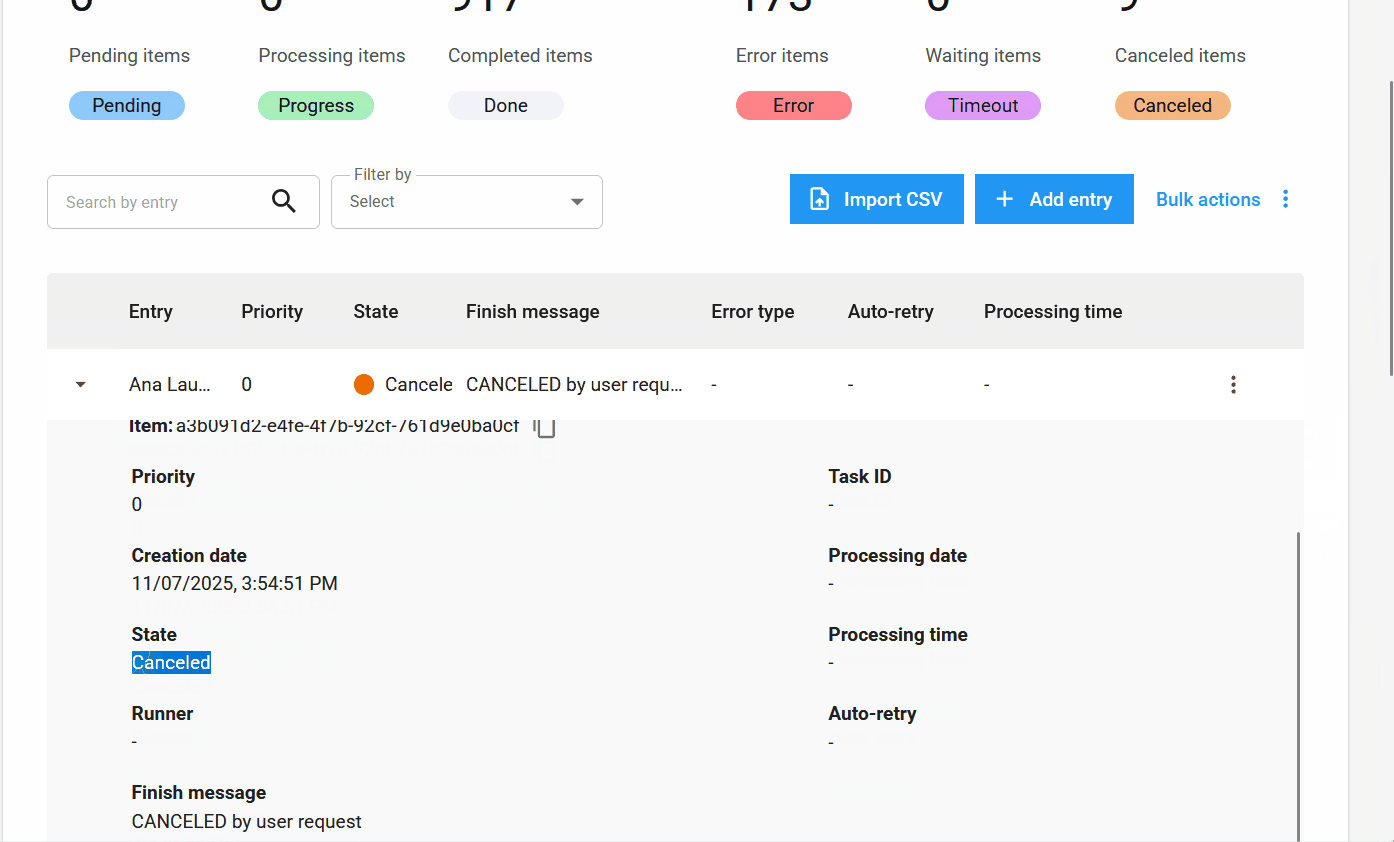
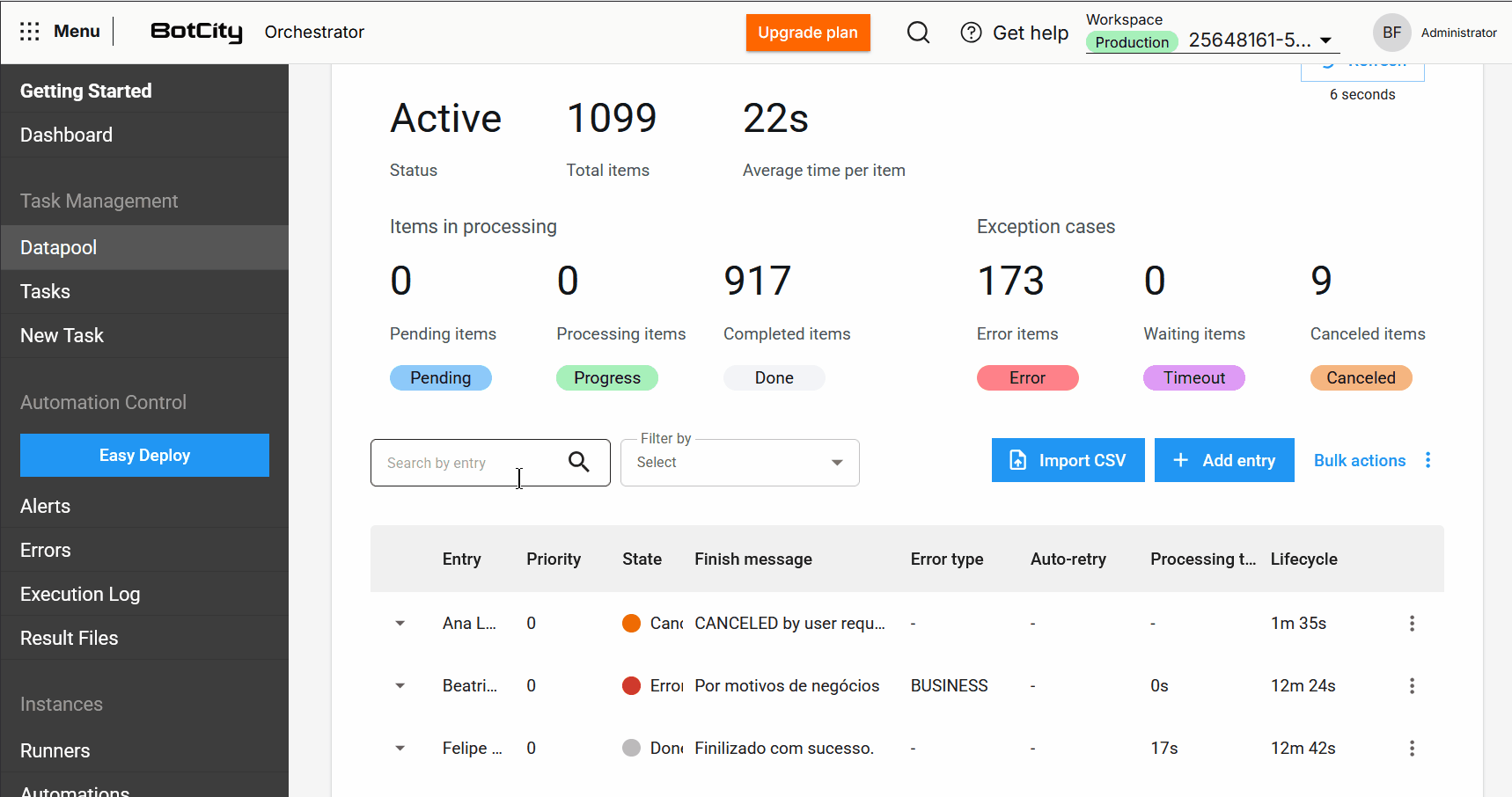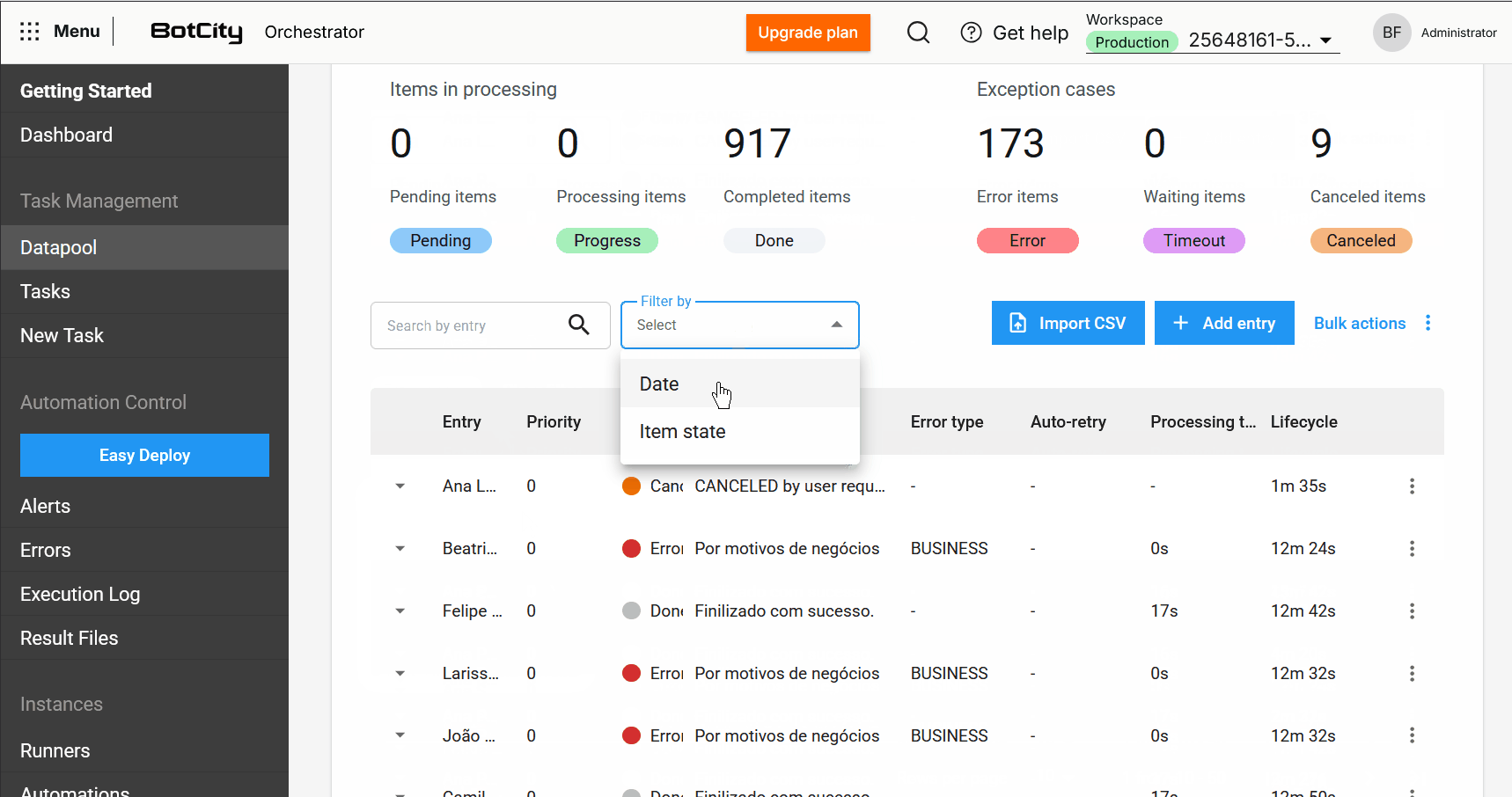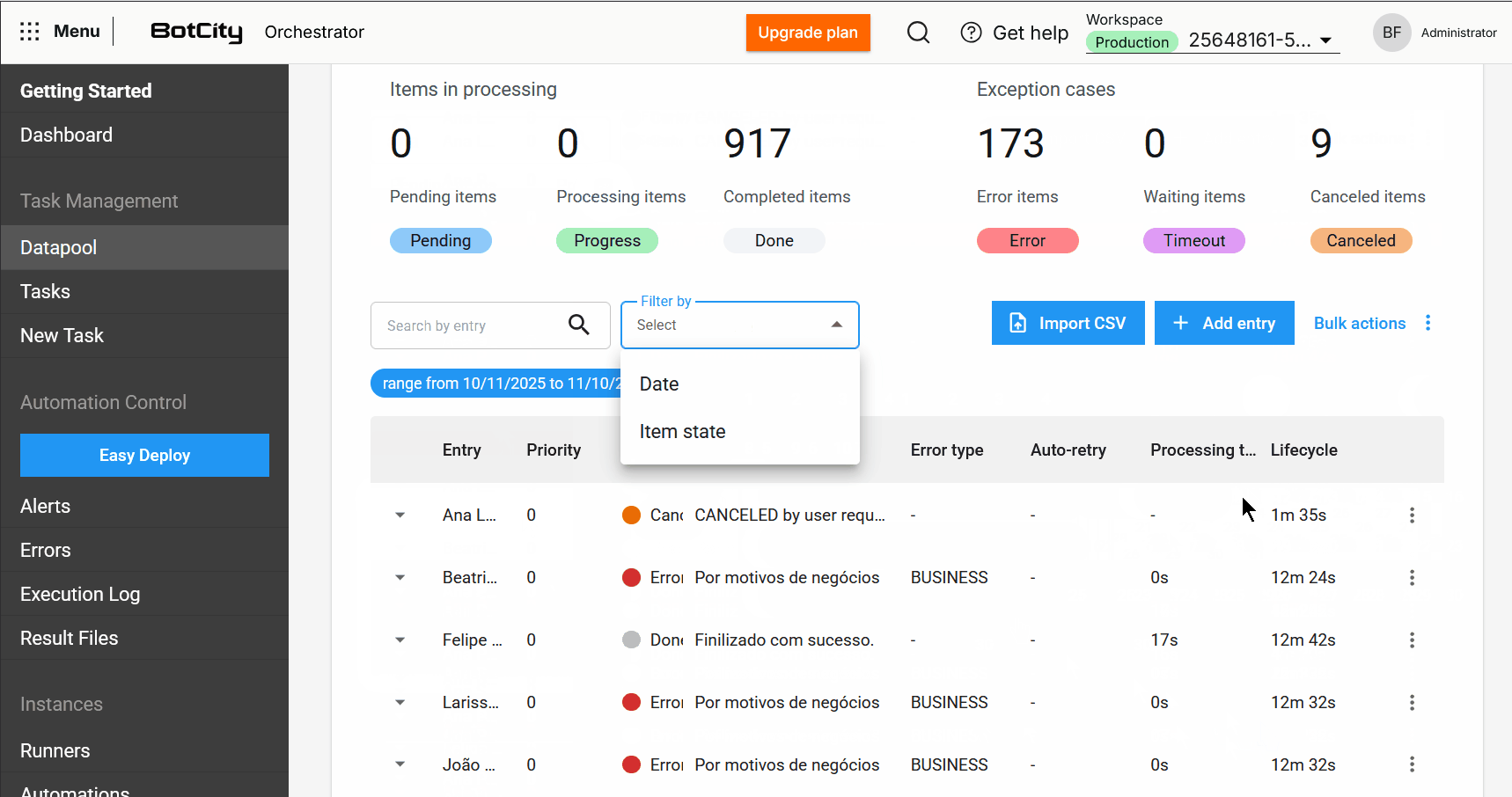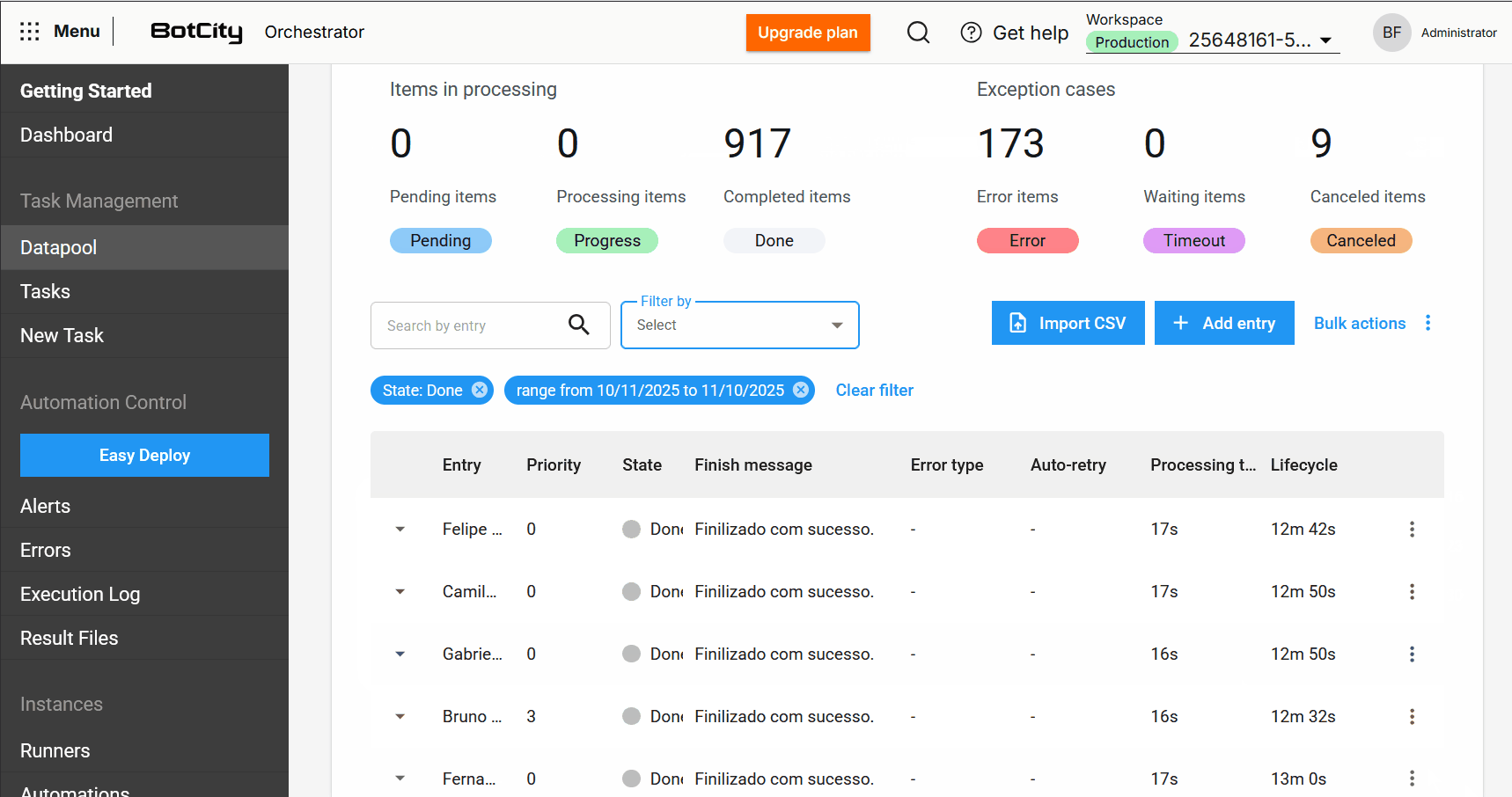
New Columns in the Processing Table¶
The item table has been expanded to include essential columns for monitoring:
- Input: Reflects the item identifier, which can be unique, a field value, or a hash.
- Priority: The priority set for processing.
- State: The updated state of the item.
- Completion Message: Completion, error, or cancellation messages that provide insights into the processing outcome.
- Error Type: Indicates whether the error was business-related or system-related.
- Auto-retry: Shows if the item is an auto-retry and its current count.
- Processing Time: The time spent processing an item.
- Lifecycle: The total time from the item's creation to its completion.
New Item States and Information¶
New item state: Canceled.
In addition to the states Pending, Processing, Completed, Error, and Timeout, the new Canceled state has been added. It applies when the user cancels an item before it is processed.
Bulk Actions and Usability Improvements¶
- Bulk Item Deletion: Users can delete items in the states
Pending,Completed,Error,Timeout, andCanceledusing the bulk actions button. Note: deleting an item is irreversible.
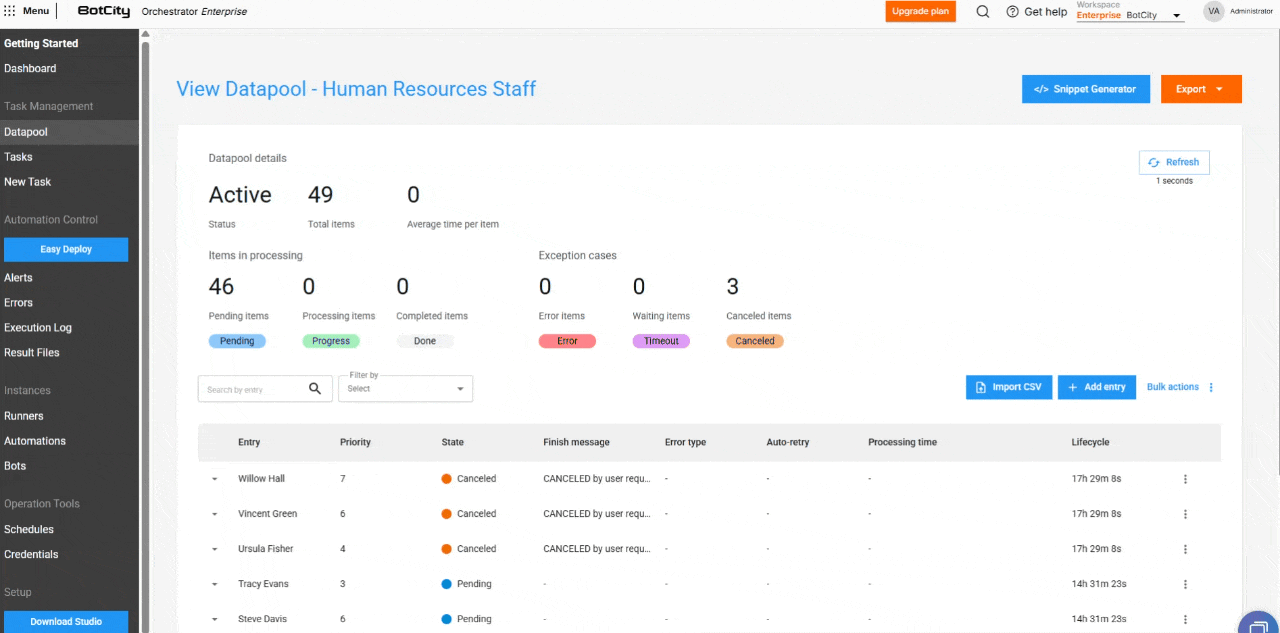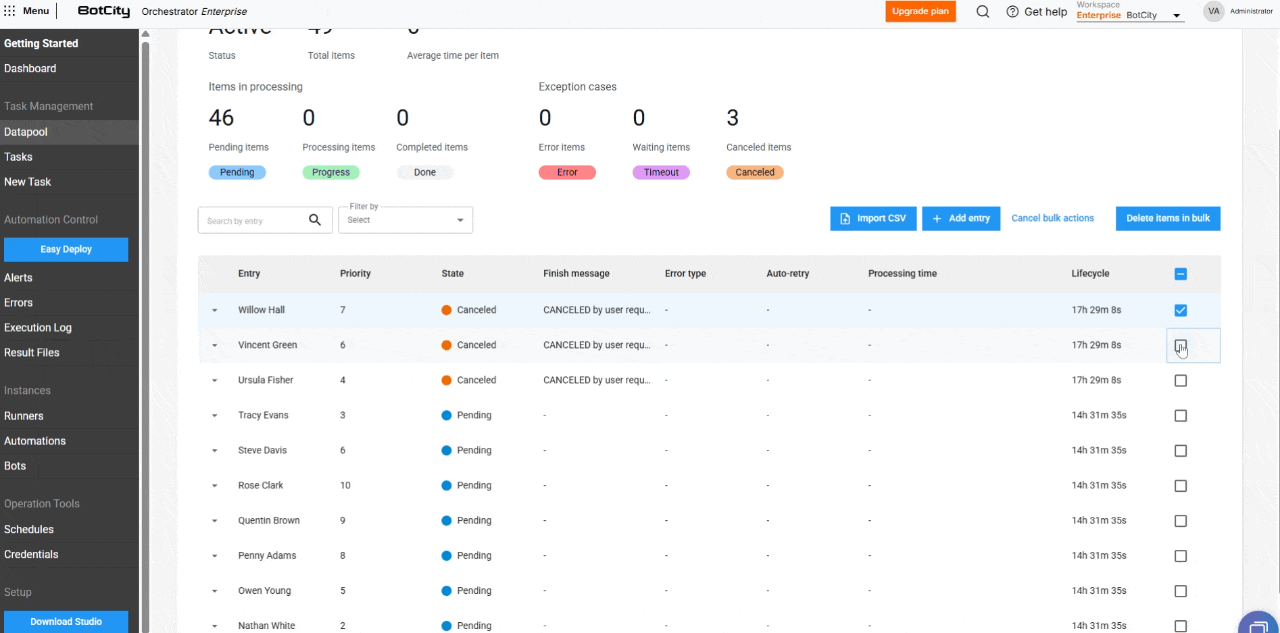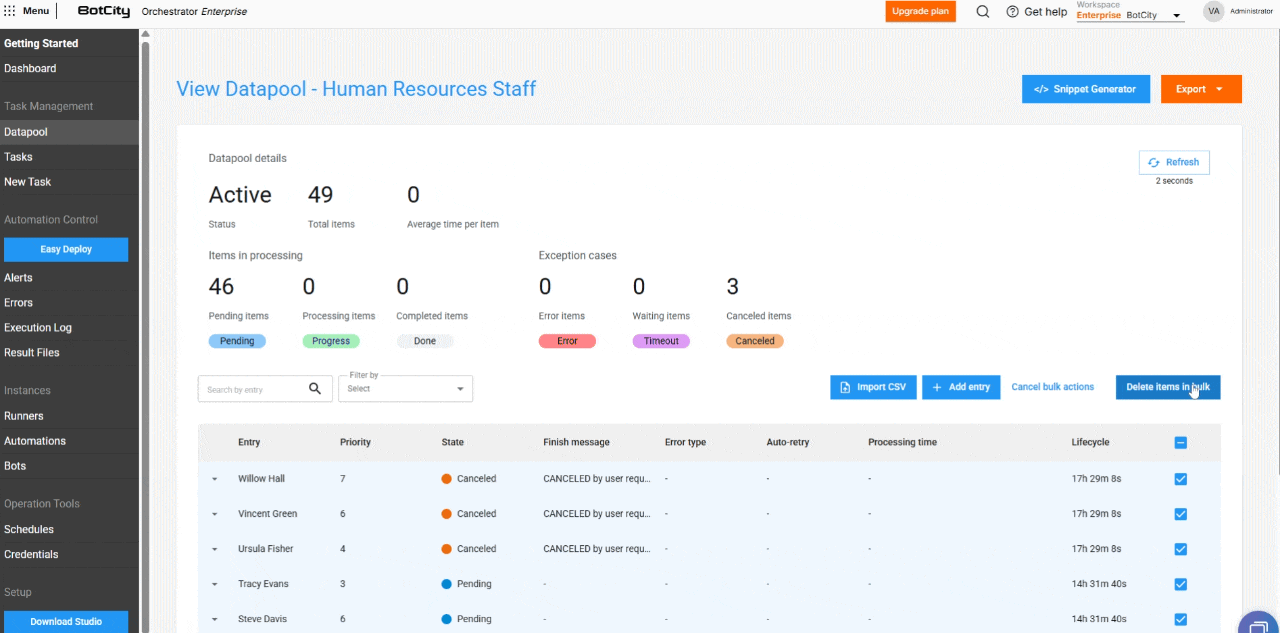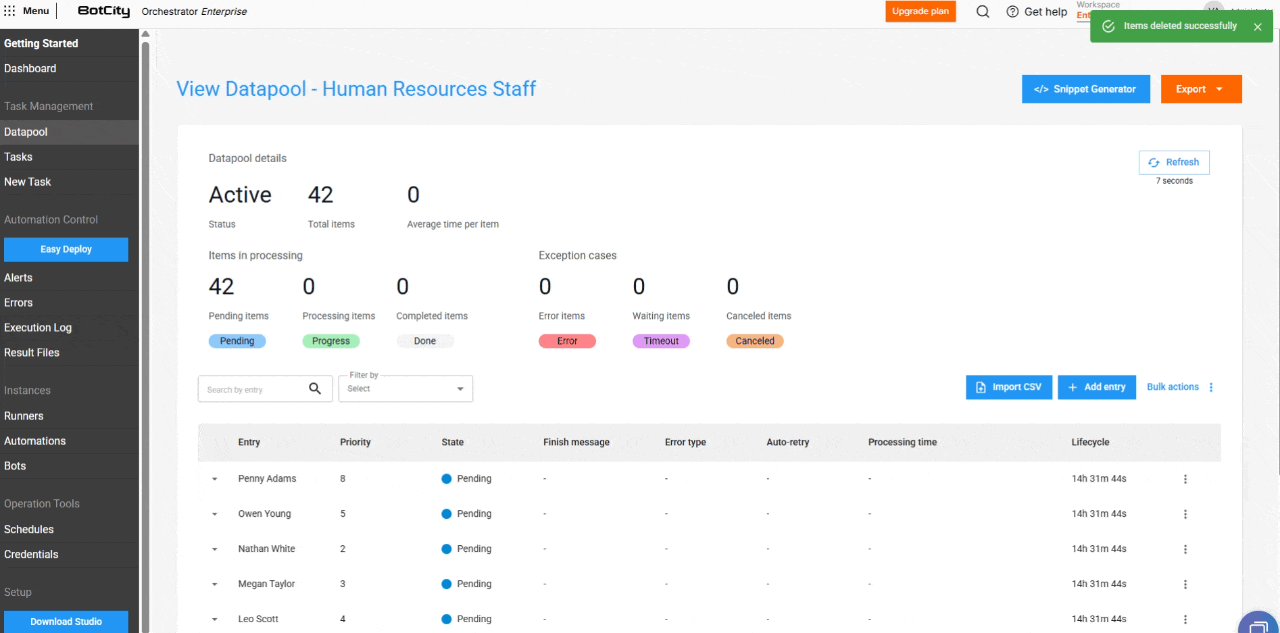
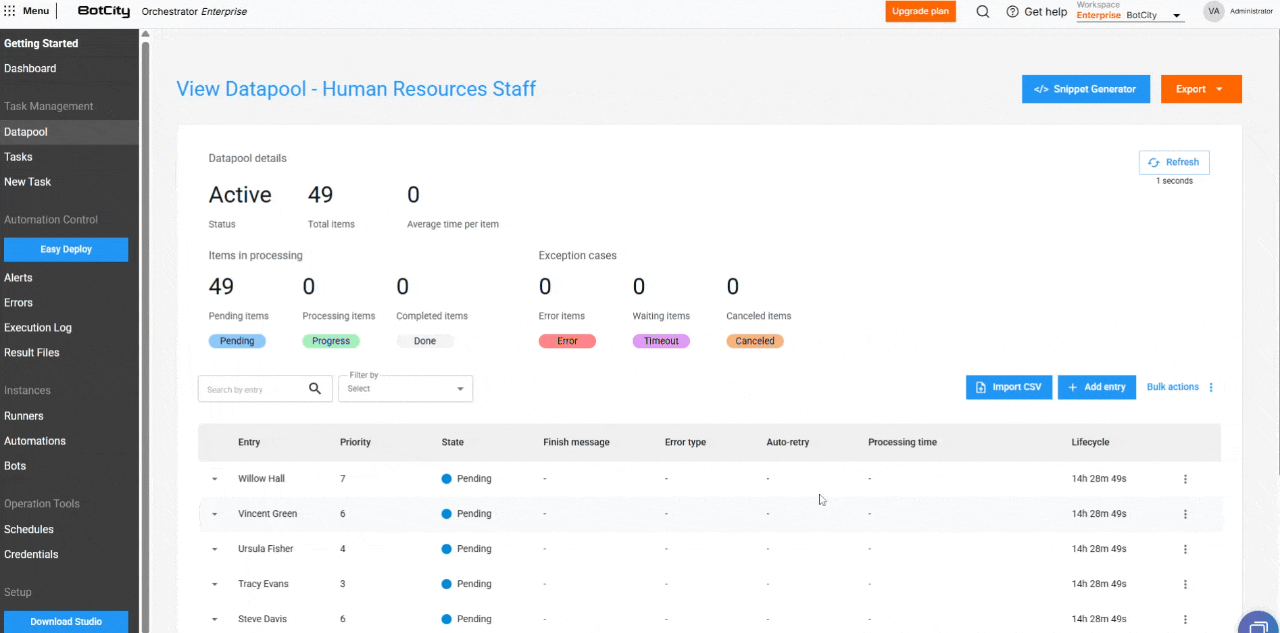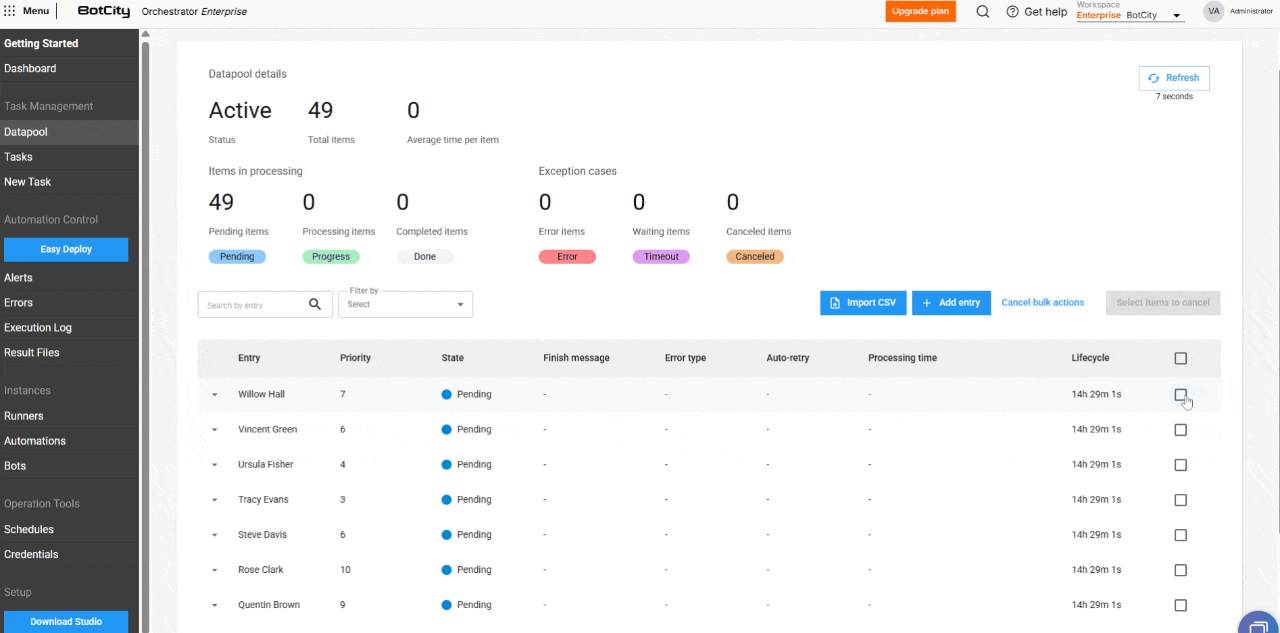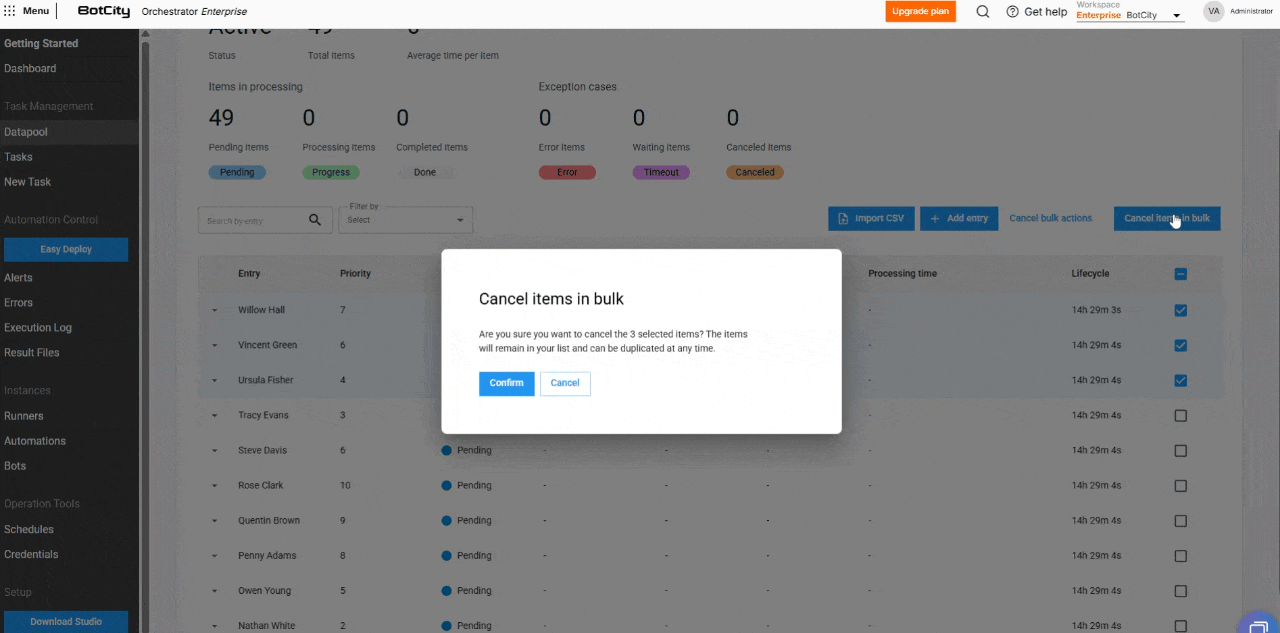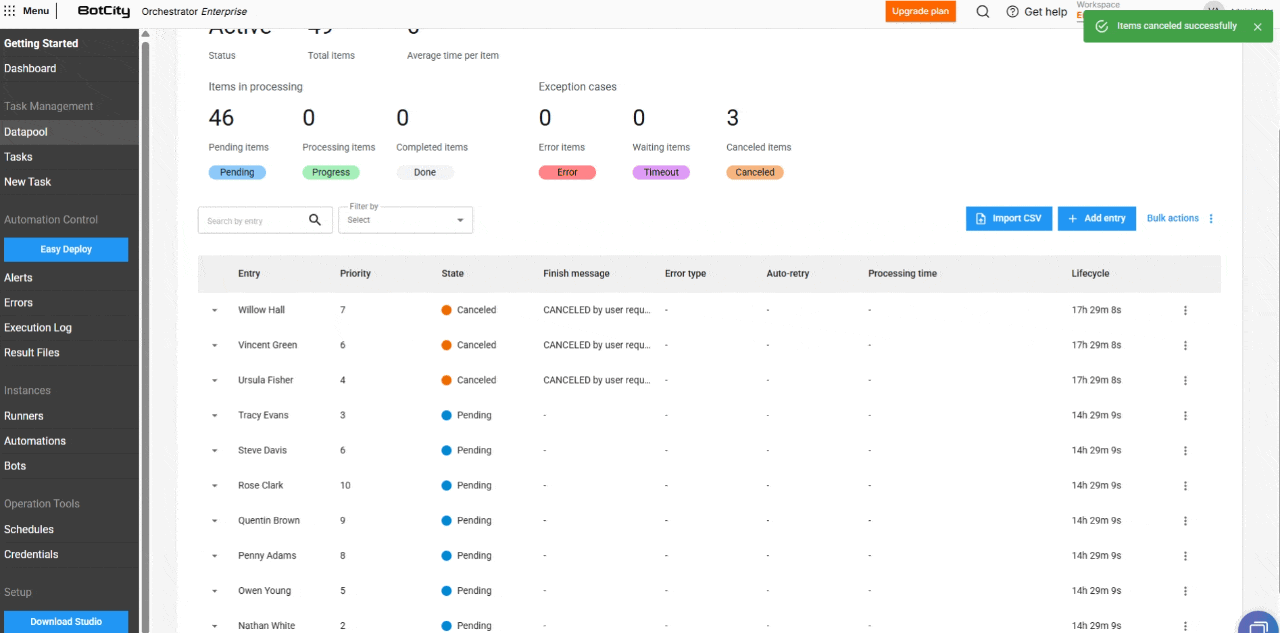
- Bulk Item Cancellation: Items with the
Pendingstatus can be canceled in bulk, allowing users to stop processing large volumes of data.
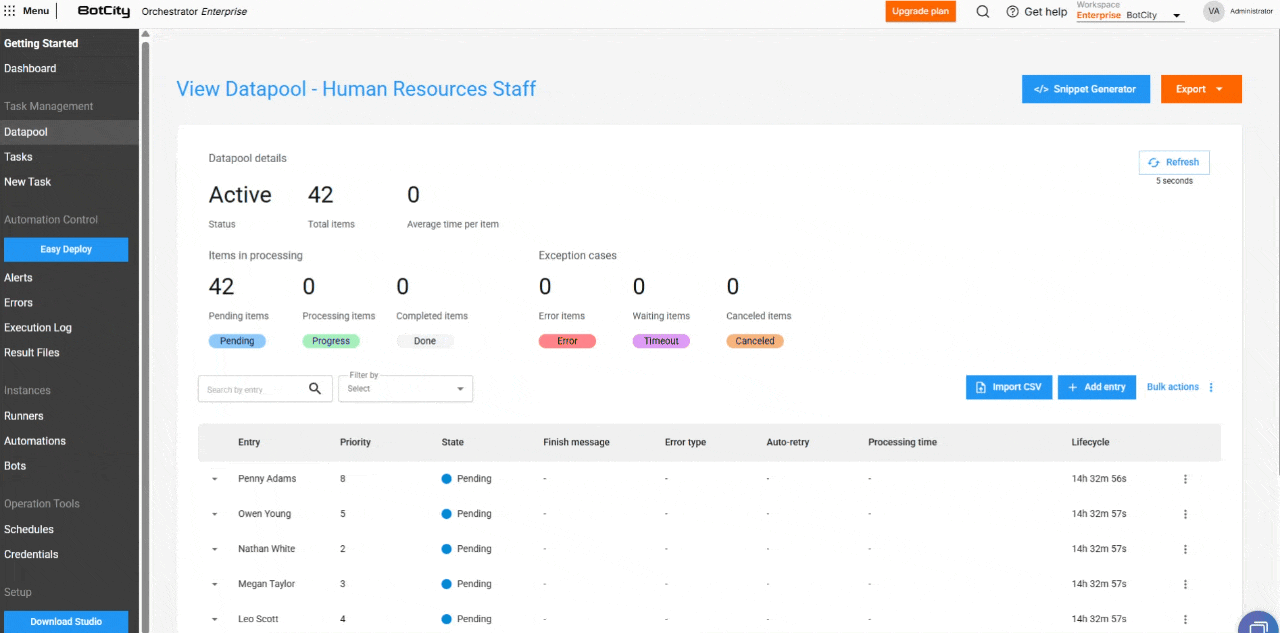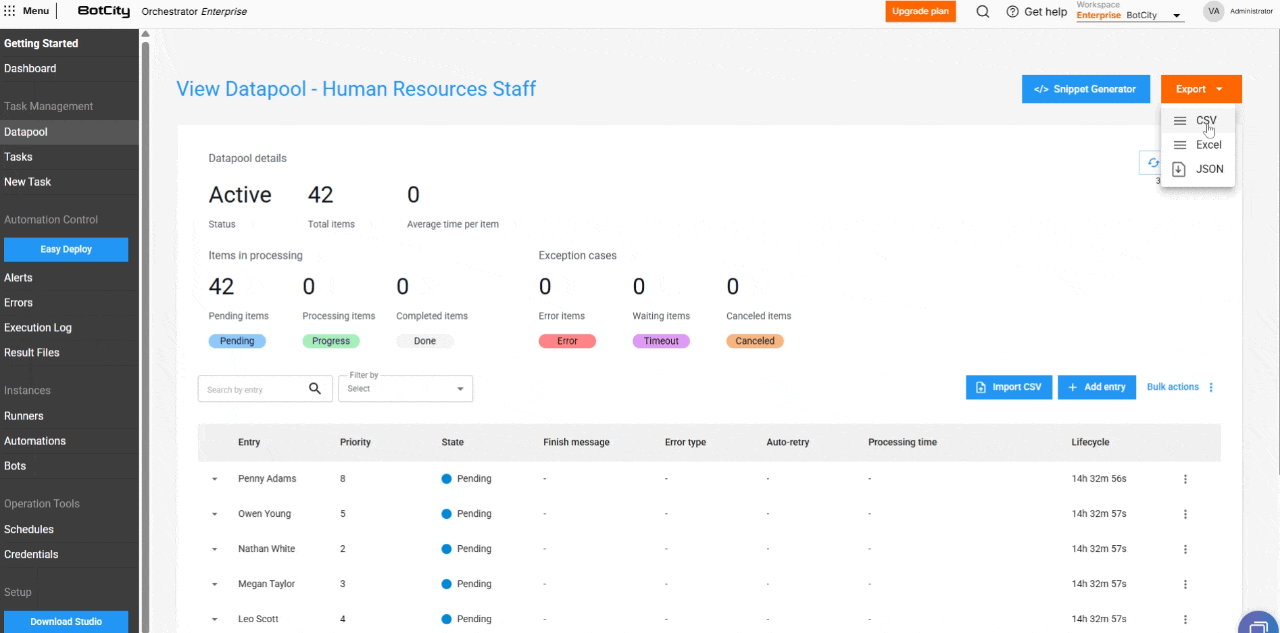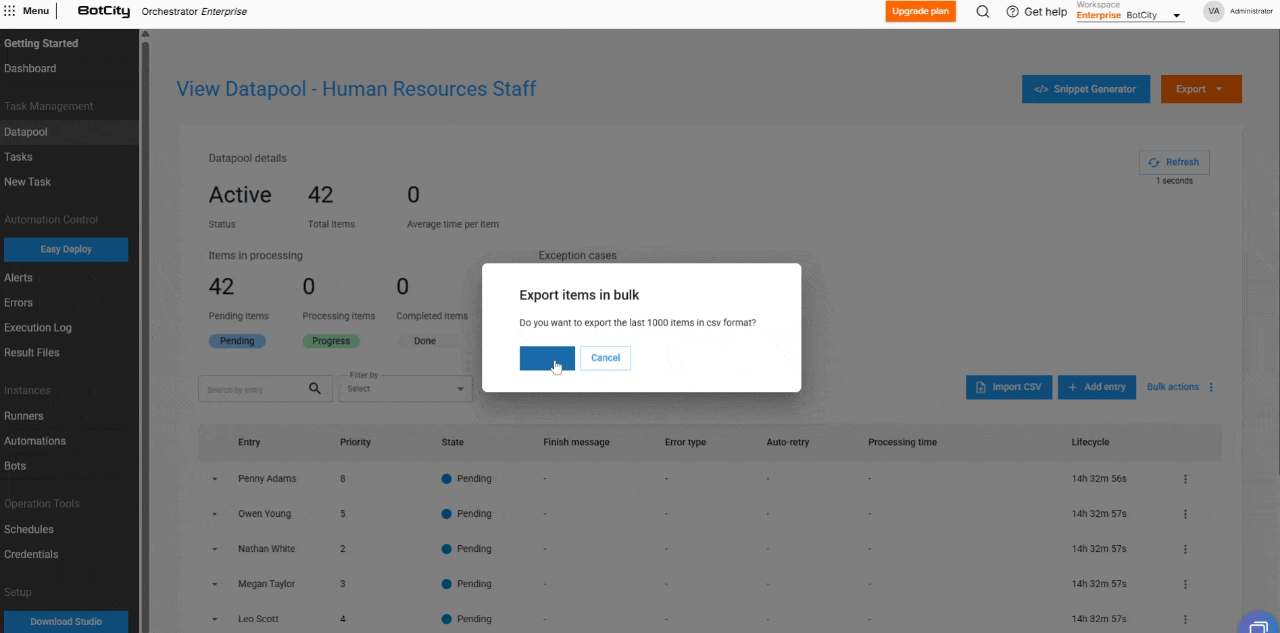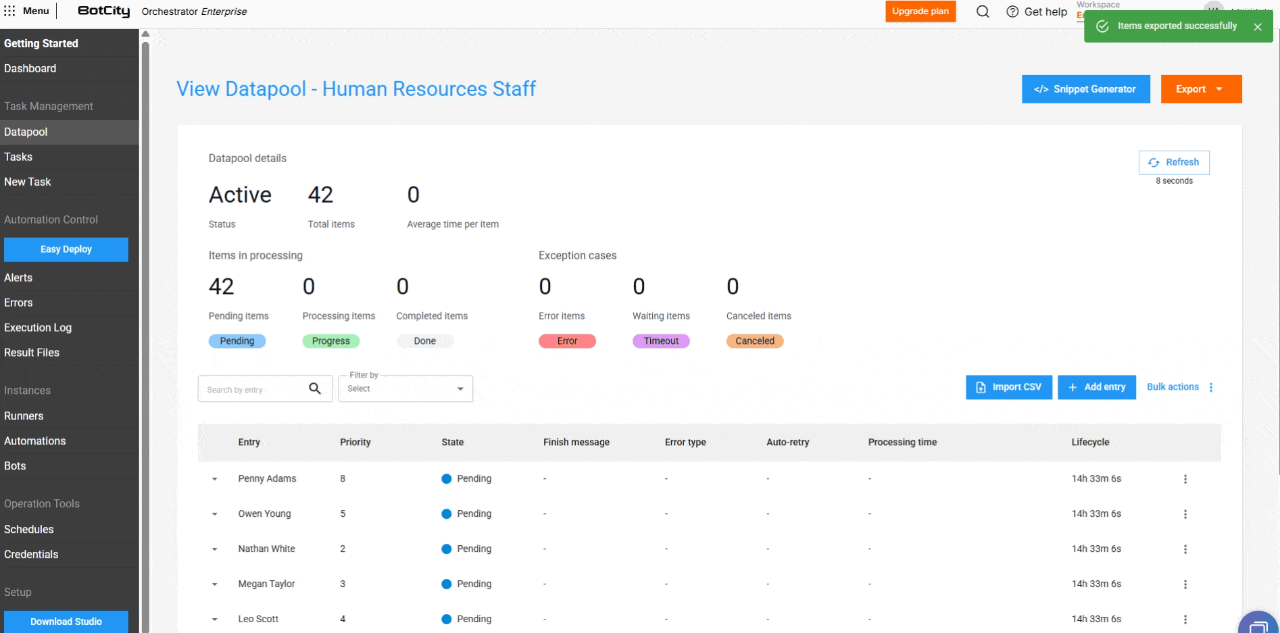
- Item Export: Users can export the most recent 1,000 items in
CSV,XLSX, orJSONformats.
- Enhanced Search and Filters: It is now possible to search for items by the input column and filter by a specific period or date range, making it easier to locate items.
Datapool 2.0 represents a significant leap in how users can manage and process batch data. These improvements have been implemented to provide more control, transparency, and efficiency.
If you have any questions about transitioning to this new version or need assistance in making the most of the new features, you can consult our official documentation and rely on our support team.